论文笔记:VDSR:Accurate Image Super-Resolution Using Very Deep Convolutional Networks
论文信息

论文代码
https://github.com/huangzehao/caffe-vdsr
Abstract
提出一个高准确度的SISR方法。该方法使用一个深网络(启发于用于ImageNet 分类的VGG-net)。使用深网络可以有效提高结果,但是训练收敛速度会变缓慢,因此提出一个简单但有效的训练策略:仅学习残差;使用比SRCNN高10^4倍的高学习率。使用极高学习率会导致梯度爆炸,解决方法:残差学习和梯度裁剪(gradient clipping)
1. Introduction
单幅图像超分辨率(Single image super-resolution ,SISR):给定一个LR图像产生一个HR图像的问题。
SISR方法:
1)较早方法--
bicubic interpolation
Lanczos resampling [7]
2) 更有效的方法--
utilizing statistical image priors [20, 13]
internal patch recurrence [9]
3) 学习的方法--
Neighbor embedding [4,15] methods
Sparse coding [25, 26, 21, 22] methods
random forest [18] and convolutional neural network (CNN) [6]
SRCNN缺点:
1) 第一,依赖于小图像区域的上下文信息 ;
2) 第二,训练收敛太慢;
3) 第三,网络仅针对单一尺度使用。
本文方法解决以上问题:
1)上下文信息(Context):深网络可以使用较大的感受野,这可以充分考虑上下文信息;
2)收敛(Convergence):加速训练方法:残差学习和极高学习率;
3)尺度(Scale Factor):一个单一的神经网络可以针对多尺度超分辨率;
2. Related Work
将本文方法和SRCNN对比:

1)模型(Model)
本文模型较深(20 vs. 3)
用于重建的信息更多即感受野更大(41 × 41 vs. 13 × 13)
2) 训练( Training)
SRCNN: Training time might be spent on learning this auto encoder so that the convergence rate of learning the other part (image details) is significantly decreased.
Our: Our network models the residual images directly and can have much faster convergence with even better accuracy.
3) 尺度(Scale)
SRCNN: 单一尺度
Our:多尺度
4) 一些小不同
本文输出图像和输入图像尺寸相同(补0),SRCNN输出比输入小;
对于所有层本文使用相同学习率,SRCNN使用不同学习率为了更好收敛。
3. Poposed Method
3.1 Proposed Network
输入为插值后的低分辨率图像。
除第一层和最后一层之外,中间d层有相似结构:64个滤波器,尺寸为3 × 3 × 64,每一个滤波器跨64个通道,在3 × 3空间区域内操作。
第一层,对输入图像操作。
最后一层用于图像重建,包含一个滤波器,尺寸为3 × 3 × 64。
在每个卷积层之前补0保证特征图和输入图像尺寸一样。

3.2 Training
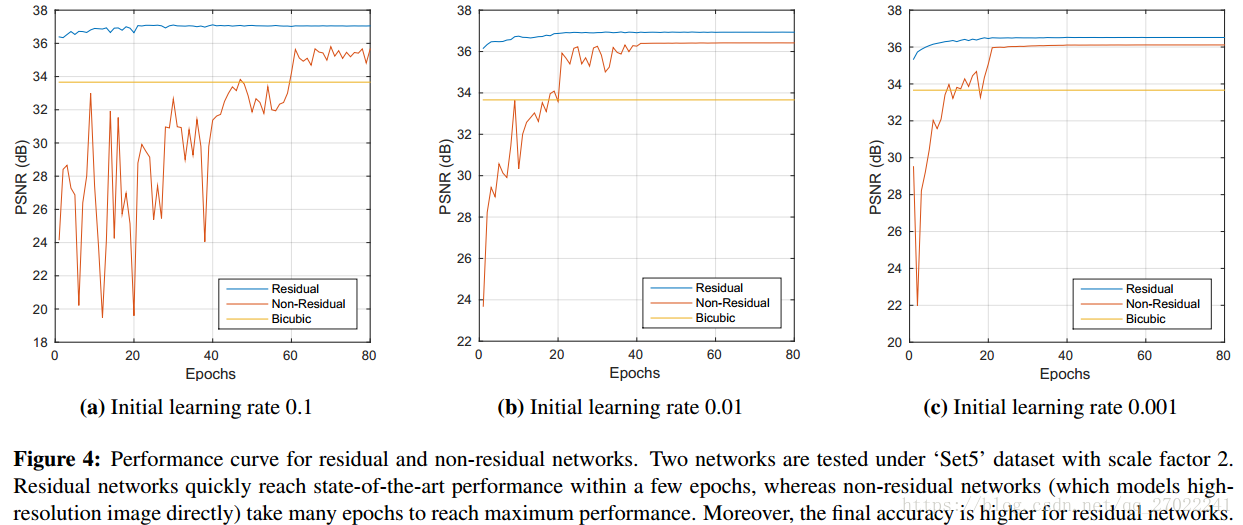
1)残差学习(Residual-Learing)
为了解决梯度弥散/梯度爆炸问题(vanishing/expoding gradients problem);
定义残差图像:r=y-x;
损失函数定义为:

f(x)是网络预测;
损失层有三个输出:残差估计;网络输入(interpolated low-resolution)图像和基准HR图像。
2)高学习率(High Learning Rates for Very Deep Networks)
简单的设置高学习率会导致梯度弥散,因此使用梯度裁剪(gradient clipping)来最大化加速网络收敛并抑制梯度弥散。
3)可调梯度裁剪(Adjustable Gradient Clipping)

4)多尺度(MutiScale)
We train a multi-scale model whose parameters are shared across all predefined scale factors. Training datasets for several specified scales are combined into one big dataset.
Data preparation:
Input patch size is now equal to the size of the receptive field
Images are divided into sub-images with no overlap.
A mini-batch consists of 64 sub-images, where sub-images from different scales can be in the same batch.
4. Understanding Properties
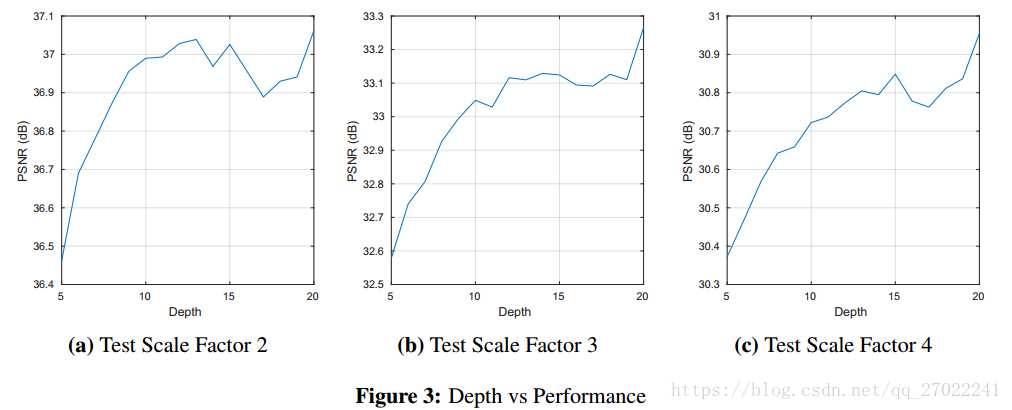
4.1 越深越好(The Deeper, the Better)
4.2 残差学习(Residual-Learning)
4.3 Single Model for Multiple Scales
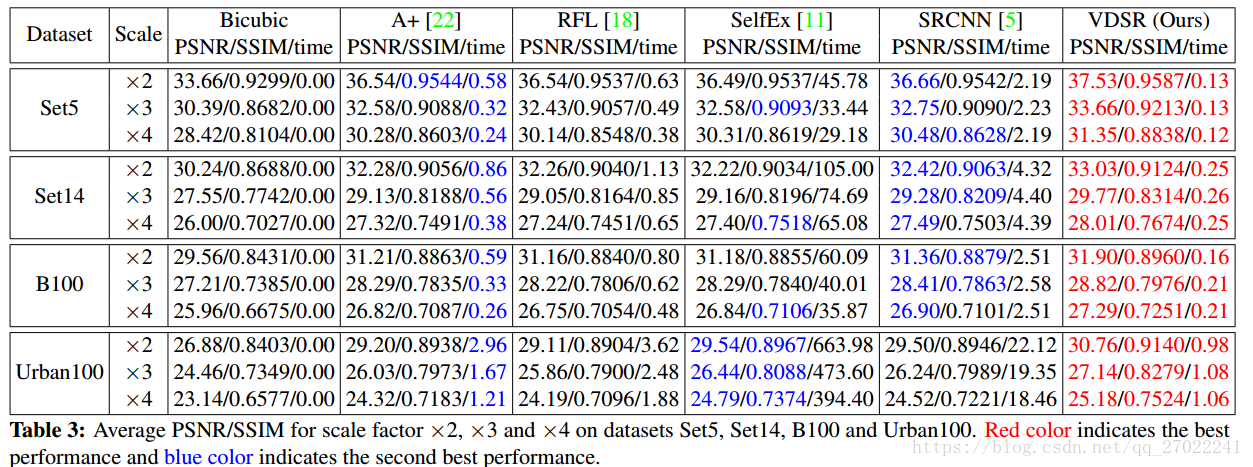
利用单一尺度训练的网路不适用于处理其他尺度,在一些测试中,甚至比插值算法要差。
当利用尺度2,3,4数据训练时,对于每一个尺度的测试结果与单一尺度训练好的模型测试结果相当。
对于较大尺度,如3,4,多尺度网络性能优于单尺度网络。