最近在对卷积神经网络(CNN)进行学习的过程中,发现自己之前对反向传播算法的理解不够透彻,所以今天专门写篇博客记录一下反向传播算法的推导过程,算是一份备忘录吧,有需要的朋友也可以看一下这篇文章,写的挺不错的:http://www.cnblogs.com/lancelod/p/4164231.html,本文也大量参考了这篇文章。本文在推导过程中忽略了偏置的存在,这样做是为了更简单明晰的阐述BP算法的操作过程,并不是说偏置不重要,希望不会引起误会。
我们知道,神经网络大多采取正向传播预测,反向传播误差的结构。反向传播算法是运用在神经网络中进行网络权重等最优值计算算法,其核心就是梯度下降 + 链式法则求偏导,下面就对反向传播算法进行一下简单的推导:
在下面的推导过程中,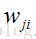
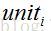
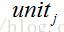
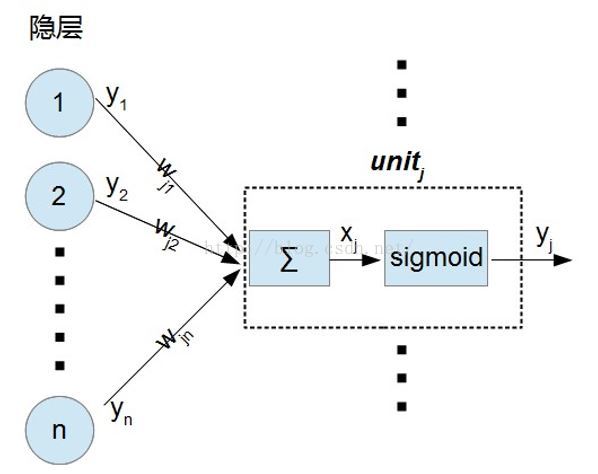
对于输出层神经元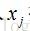
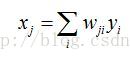
可以看到它的输入等于前一层所有神经元的输出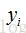
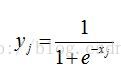
对于有监督训练, 期望输出即样本类标签d和实际输出y都是已知的, 可以定义误差或者loss function为:
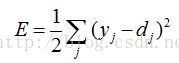

这样,我们就可以根据最后求出的误差来对权重进行更新,这种误差反向传递的方式就是反向传播算法的精髓所在。
处理完输出层神经元,我们再来看一下输出层之前的一层神经元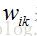
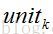

相信大家已经看出误差反向传导的内涵了,每一层所产生的误差会逐渐向之前的层次传播,而各层的权重根据梯度下降算法不断地优化。总之,反向传播算法的核心就是梯度下降 + 链式法则求偏导,虽然看起来很繁琐并且计算复杂度有点高,但是实际上BP算法的精确性和易用性是很难被其他算法替代的,这也是现在比如CNN等很火的深度学习算法普遍采用BP算法的原因。
出处https://blog.csdn.net/shenxiaoming77/article/details/54894138补充关于BP算法的详细博客链接
https://www.cnblogs.com/charlotte77/p/5629865.html
关于BP算法代码的博客链接
http://www.cnblogs.com/fuqia/p/8982405.html