损失函数和优化
1 损失函数
损失函数是用来定量地分析我们的模型预测效果有多糟糕的函数。损失函数输出值越大,代表我们的模型效果越糟糕。
损失函数的通用表示:
假设我们的数据集有N个样本,
其中
是样本图片,
是对应的整数标签;整个数据集的损失就是每个样本的损失之和。
这里介绍两种损失函数
1.1 多分类SVM损失
SVM损失的形式是这样的:
这里的
代表一个边界(margin),即正分类比误分类大的程度,其实这个是可以自由设置的,但是也要依据问题去考虑。
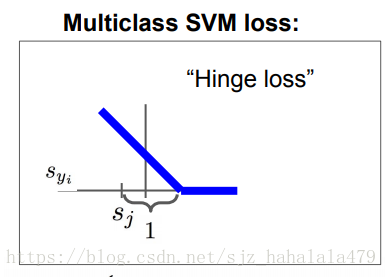
也可以把SVM Loss叫做Hinge Loss,横轴是 ,随着 的增大,HInge Loss是逐渐下降的,最终降为0。

在这个问题中,我们的 就是模型跑到最后,给每个样本image的分类的一个分数值。
关于SVM Loss,有几个问题:
-
损失的最大/最小值分别是什么?
最小值是0,对应全部分类正确的情况;
最大值是无穷大 -
在初始化阶段, 很小,所以所有的 ,这个时候的损失是多少?
答案是 , 代表分类的数量。
,再求平均值,就是 -
如果包含 的情况,所有损失的和应该是多少呢?
损失的和应该会加上 -
如果我们使用平均值而非求和,损失会有怎样的变化呢?
没什么变化,只是缩放而已 -
如果我们使用 ,会有什么变化呢?
这就形成了一个新的损失函数。 -
如果我们找到了一个 ,使得损失为0,那么损失是惟一的吗?
不是, 也能令损失为0。
既然 和 都能使损失降为0,那么我们应该选哪个 呢?
这里我们引入正则
正则项存在的意义,一般是防止过拟合。因为即使我们把损失调到最低,也只是使得模型尽可能地去拟合训练集,但是我们的目标是让模型尽可能拟合测试集。所以过拟合是不好的,我们可以通过增加一个
正则惩罚项,使得模型尽可能地简单。
简单的正则化的例子有L1正则、L2正则;更复杂的有Dropout,批正则,随机深度、fractional pooling。

1.2 softmax损失(多项Logistic回归)
softmax的主要思想是将分类分数的值转化为概率值。

首先是对分数取 的指数,然后归一化;得到概率值。然后对概率值取对数再取负值。
关于softmax也有几个问题:
- softmax的损失的最小值/最大值分别是?
最小值为0,最大值是无穷大 - 最开始的时候,
值是大致相等的,损失是多少呢?
结果是
可以做一个简单的推导,如上图,cat,frog,car有三个类,某一个图像三个类的得分都是