论文:https://arxiv.org/pdf/1408.2873.pdf
题目:First-Pass Large Vocabulary Continuous Speech Recognition using Bi-Directional Recurrent DNNs
摘要
我们提出一种仅使用神经网络和语言模型来完成大词汇量连续语音识别的第一步的方法。 深度神经网络声学模型现在在基于HMM的语音识别系统中很普遍,但是构建这样的系统是一项复杂的,针对特定领域的任务。 最近的工作证明了通过直接预测音频中的文字文本来丢弃HMM序列建模框架的可行性。 本文通过两种方式扩展了这种方法。 首先,我们证明简单的递归神经网络体系结构可以实现较高的准确性。 其次,我们提出并评估了一种改进的前缀搜索解码算法。 这种解码方法可以使用语言模型进行第一步语音识别,而基于HMM的系统的繁琐基础结构完全不需要这种语言模型。 实验在《华尔街日报》语料库上证明了其相当有竞争力的单词错误率,以及双向网络重复的重要性。
1.介绍
现代大词汇量连续语音识别(LVCSR)系统很复杂,很难修改。 这种复杂性的大部分源于将单词建模为具有隐马尔可夫模型(HMM)的亚语音状态序列的范例。 基于HMM的系统需要精心设计的训练方法,以连续构造更复杂的HMM识别器。 建立,理解和修改基于HMM的LVCSR系统的总体困难限制了语音识别的进展,并将其与相关领域的许多进步相隔离。
最近,Graves&Jaitly(2014)展示了一种无HMM的方法来训练语音识别器,该方法使用神经网络直接预测给出语音发音的文本字符。这种方法放弃了现代基于HMM的LVCSR系统中存在的许多假设,而是将语音识别视为直接序列转换问题。该方法使用连接器时间分类(CTC)损失函数训练神经网络,该函数通过有效地求和所有可能的输入-输出序列比对来最大化输出序列的可能性。作者使用CTC,能够在《华尔街日报》 LVCSR语料库上训练神经网络,以预测字符误码率(CER)低于10%的测试话语的字符序列。这些结果本身令人印象深刻,但就字错误率(WER)而言,这些结果仍无法与现有的基于HMM的系统竞争。语音识别中良好的单词级的性能通常在很大程度上取决于语言模型,以在可能的单词序列上提供先验概率。
为了在解码过程中整合语言模型信息,Graves&Jaitly(2014)使用其经过CTC训练的神经网络对由基于HMM的最新系统生成的晶格或n最佳假设列表进行评分。 这引入了潜在的混淆因素,因为n最佳列表会很大程度上限制可能的转录集。 另外,它导致整个系统仍然依靠HMM语音识别基础结构来获得最终结果。 相反,我们提出的首遍解码结果使用神经网络和语言模型从头开始解码,而不是对现有假设进行重新排序。
我们描述了一种解码算法,该算法将语言模型与CTC训练的神经网络直接集成在一起,以搜索可能的单词序列空间。 我们的首遍解码算法使受CTC训练的模型可以从语言模型中受益,而无需依赖现有的基于HMM的系统来生成词格。 这消除了对以HMM为中心的语音识别工具包的持久依赖,并使我们仅使用神经网络和n-gram语言模型就可以获得相当有竞争力的WER结果。
深度神经网络(DNN)是用于语音识别的最广泛使用的神经网络体系结构(Hinton et al.,2012)。 DNN是用于分类和回归问题的相当通用的体系结构。 在基于HMM的LVCSR系统中,DNN通过在给定时间点的声学输入的情况下预测HMM的隐藏状态来充当声学模型。 但是,在这种HMM-DNN系统中,有关输出序列的时间推理是在HMM而不是神经网络中进行的。 神经网络的CTC训练迫使网络对输出序列依赖性进行建模,而不是独立于其他时间框架进行推理。 为了更好地处理这种时间依赖性,以前使用CTC的工作使用了长期短期记忆(LSTM)网络。 LSTM是一种神经网络体系结构,最初旨在防止S型DNN或时间递归深度神经网络(RDNN)消失的梯度问题(Hochreiter&Schmidhuber,1997)。
我们的工作使用RDNN代替LSTM作为神经网络体系结构。 RDNN总体上更简单,因为后续层之间只有密集的权重矩阵连接。 这种更简单的体系结构更适合图形处理单元(GPU)计算,从而可以大大减少培训时间。 最近的工作表明,利用整流器非线性,DNN可以在DNN-HMM系统中很好地发挥作用,而在优化过程中不会出现梯度消失的问题(Dahl等人,2013; Zeiller等人,2013; Maas等人,2013)。 这使我们寄希望于具有整流器非线性的RDNN能够与专门设计用于避免梯度消失的LSTM媲美。
2.模型
我们使用CTC损失函数训练神经网络,以给定声学特征作为输入来对字母序列进行最大似然训练。 我们将单个发声作为由声学特征矩阵X和单词转录W组成的训练示例。CTC目标函数使对数概率log p(W; X)最大化。 我们在这里保留了损失函数的完整说明,因为我们的公式完全遵循之前使用CTC预测话语转录特征的工作(Graves&Jaitly,2014; Graves等,2006)。
2.1深度神经网络
固定损失函数之后,我们接下来必须定义如何计算p(c | xt),即在给定音频特征xt在时间t时输出字符c的预测分布。 尽管可以使用许多函数逼近器,但我们选择DNN作为最基本的模型。 DNN使用一系列隐藏层,然后是输出层来计算分布p(c | xt)。 给定输入向量xt,则第一个隐藏层激活是计算为的向量,
h (1) = σ(W(1)T xt + b (1)).
矩阵W(1)和向量b(1)是该层的权重矩阵和偏差向量。 函数σ(·)是逐点非线性。 我们使用整流器非线性,因此选择σ(z)= max(z,0)。DNN可以具有任意多个隐藏层。 在第一个隐藏层之后,第i层的隐藏激活h(i)计算为:
h (i) = σ(W(i)T h (i−1) + b (i) ).
为了在一组可能的字符上获得适当的分布,网络的最后一层是形式为softmax的输出层,
其中W(s)k是输出权重矩阵W(s)的第k列,b(s)k是标量偏差项。 给定一个训练示例,我们可以为DNN的所有参数计算次梯度,从而利用基于梯度的优化技术。 请注意,在DNN-HMM模型中通常使用相同的DNN公式来预测senones而不是字符的分布。
2.2循环神经网络
转录W具有DNN可能无法充分捕获的许多时间相关性。 在每个时间步t处,DNN仅使用输入特征xt计算其输出,而忽略先前的隐藏表示形式和输出分布。 为了更好地建模问题中存在的时间依赖性,我们使用RDNN。 在RDNN中,我们选择一个隐藏层j具有时间递归权重矩阵W(f),然后计算该层的隐藏激活为
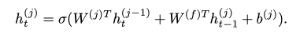
注意,我们现在在时间步t对层j的隐藏激活向量进行区分h(j)t,因为它现在取决于时间t − 1上层j的激活向量。
在使用RDNN时,我们发现使用整流器非线性的修改版本很重要。 修改后的函数选择σ(z)= min(max(z,0),20),该值会裁剪较大的激活值,以防止网络训练期间发散。 将最大允许激活设置为20会导致限幅整流器在除最极端情况以外的所有情况下均充当正常整流器功能。
除了这些更改之外,RDNN的计算与2.1中描述的DNN的计算相同。 像DNN一样,我们可以使用有时称为反向传播的方法为RDNN计算子梯度。 在我们的实验中,我们总是在整个时间范围内完全计算梯度,而不是截断以获得近似的次梯度。
2.3 双向循环神经网络
前向循环连接反映了音频输入的时间特性,而BRDNN可能是更强大的序列转导模型,它可以同时保持向前和向后的状态。 当进行每个预测时,这样的模型可以整合来自输入特征的整个时间范围的信息。 通过再次选择时间递归层j,我们将RDNN扩展为BRDNN。 BRDNN创建向前和向后的中间隐藏表示,分别称为h(f)t和h(b)t。 我们使用时间权重矩阵W(f)和W(b)分别将h(f)t在时间上向前传播和h(b)t在时间上向后传播。 我们通过方程式更新前进和后退分量,
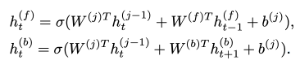
请注意,递归的前向和后向隐藏表示完全彼此独立地计算。 与RDNN一样,我们使用修改后的非线性函数σ(z)= min(max(z,0),20)。 为了获得该层的最终表示h(j)t,我们将两个时间递归分量相加,
h (j) t = h (f) t + h (b) t .
除了对递归层的更改之外,BRDNN还使用与RDNN相同的公式来计算其输出。 至于其他模型,我们可以直接为BRDNN计算一个子梯度,以执行基于梯度的优化。
3.解码
假设输入的长度为T,则对于t = 1,神经网络的输出将为p(c; xt),t=1,…,T。 同样,p(c; xt)是在给定音频输入xt的情况下,包括空白符号的字母表全集中可能字符的分布。 为了从神经网络的输出中恢复字符串,作为第一近似,我们在每个时间步长采用argmax。 令S =(s1,…,sT)为字符序列,其中st = argmaxc∈Σp(c; xt)。 通过折叠重复字符并去除空白,可将序列S映射到字母表。 这给出了可以使用CER和WER对参考转录进行评分的序列。
这种第一近似值缺乏包含词典或语言模型约束的能力。 我们提出了一种通用算法,该算法能够纳入这些约束。 将X作为时间T的声音输入,我们寻求一个转录W,该转录使概率最大,
pnet(W; X)plm(W).
这里,转录的总体概率被建模为两个因素的乘积:网络给定的pnet和语言模型事先给定的plm。 在实践中,当由n-gram语言模型给出时,先前的plm(W)过于受限,因此我们降低了权重,并将单词插入罚分(或加分)包括为
pnet(W; X)plm(W) α |W| β .
Alogrithm 1尝试找到一个使上面等式最大化的字串W。该算法为每个前缀pb(ℓ; x1:t)和pnb(ℓ; x1:t)维护两个独立的概率。 在给定音频输入X的前t个时间步长的情况下,这分别是前缀ℓ以空白结尾或不以空白结尾的概率。
集合Aprev和Anext分别在上一个时间步和下一个时间步维护一个活动前缀列表。 请注意,Aprev的大小永远不会大于光束宽度k。 前缀的总概率是单词插入项与空白和非空白结尾概率之和的乘积,
p(ℓ; x1:t) = (pb(ℓ; x1:t) + pnb(ℓ; x1:t))|W(ℓ)| β ,
其中W(ℓ)是序列ℓ中的一组单词。 当采用Anext的k个最可能的前缀时,我们使用上面等式给出的概率对每个前缀进行排序。
变量ℓend是标签序列ℓ中的最后一个字符。 函数W(·)将ℓ转换为字符串,在每个空格字符处分割序列并截断最后一个空格后面的所有字符。
每当算法建议在ℓ上添加空格字符时,我们都通过包括概率p(W(ℓ+)| W(ℓ))来合并词典或语言模型约束。 如果将W(ℓ+)的最后一个单词放在词典中,则将p(W(ℓ+)| W(ℓ))设置为1,否则将其设置为0,则该概率就成为了一种约束,迫使所有字符串仅包含词典中的单词。 此外,p(W(ℓ+)| W(ℓ))可以通过仅考虑W(ℓ)中的最后n-1个单词来表示n元语法模型。
4.实验
算法1
前缀波束搜索:该算法将前一组前缀Aprev初始化为空字符串。 对于当前在Aprev中使用的每个时间步长和每个前缀ℓ,我们建议在字母Σ之前添加一个字符。 如果字符为空白,则不扩展前缀。 如果字符是空格,我们将合并语言模型约束。 否则,我们扩展前缀并合并网络的输出。 所有新的活动前缀都添加到Anext。 然后,我们将Aprev设置为仅包含Anext的k个最可能的前缀。 输出是最可能的转录本1,尽管可以很容易地将其扩展以返回n个最佳列表。

我们在81小时的《华尔街日报》(WSJ)新闻文章口述语料库(在LDC目录中以LDC94S13B和LDC93S6B提供)中评估了我们的方法。我们的培训内容来自包含37,318种发音的81个小时的演讲。将LDC发布的语料库转换成训练和测试子集的基本准备工作遵循的是Kaldi语音识别工具包的s5配方(Povey等,2011)。但是,我们没有将用于准备成绩单以训练HMM系统的大部分文本标准化应用。取而代之的是,我们只是简单地删除不必要的成绩单,例如词汇重音,保留抄录的单词片段和首字母缩写标点符号。我们可以放心地放弃很多这种规范化,因为我们的方法不依赖于词典或发音词典,而词典或发音词典会引起问题,尤其是对于单词片段。我们的语言模型是WSJ语料库发布的标准模型,没有进行词法扩展。我们将“ dev93”评估子集用作开发集,并在“ eval92”评估子集上报告了最终测试集的性能。两个子集使用相同的20k单词词汇。用于解码的语言模型仅限于相同的20k单词词汇。
输入的音频被转换为具有23个频率段的log-Mel滤波器组功能。 连接+/- 10帧的上下文窗口以形成大小为483的最终输入向量。我们没有执行其他特征预处理或特征空间说话者自适应。 我们的输出字母表包括32个类,即空白符号“”,26个字母,3个标点符号(撇号,. 和-)以及用于噪声和空格的标记。
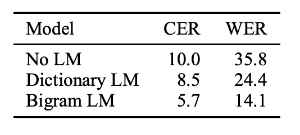
表1:使用CTC损失功能训练的BDRNN的单词错误率(WER)和字符错误率(CER)结果。 作为基线(无LM),我们通过在每个时间步选择最可能的标签并执行CTC培训中执行的标准折叠来进行解码。 我们使用基线与字典约束和二元语言模型经过修改的前缀搜索解码器进行比较。
4.1语言模型第一步解码
我们训练了具有5个隐藏层(共1824个隐藏单元)的BRDNN,总共有20.9M个自由参数。网络的第三个隐藏层具有循环连接。网络中的权重是根据权重矩阵的输入和输出层大小缩放的均匀随机分布进行初始化的(Glorot等,2011)。如Sutskever等人所述,我们使用Nesterov加速梯度优化算法。 (2013),初始学习率为10−5,最大动量为0.95。每次完全通过训练集后,我们将学习率除以1.2,以确保总体学习率随时间降低。我们通过训练集对网络进行了总共20次训练,使用我们的Python GPU实现大约需要96个小时。对于使用前缀搜索的解码,我们使用200的波束大小并使用保留集进行交叉验证,以找到参数α和β的良好设置。表1列出了使用该受训BRDNN进行解码的多种方法的单词和字符错误率。
但没有任何语言限制的情况下,CER相当低,WER仍然很高。 这与我们的观察结果一致,即当一个单词看起来大多正确但不符合高度不规则的英语拼字法时,在字符级别会发生许多错误。 在可能的字符序列上使用20k单词词汇作为前缀的前缀搜索解码可显着改善WER,但对CER的更改相对较小。 再次比较no LM和字典LM方法的CER,这表明没有LM时,字符大部分是正确的,但分布在许多单词上,从而增加了WER。 当我们使用二元流LM解码时,CER和WER都会发生较大的相对下降。 bigram LM模型的性能表明,受CTC训练的系统无需依赖现有语音系统生成的点阵或n最佳列表即可获得有竞争力的错误率。
4.2循环连接的影响
先前使用DNN-HMM系统进行的实验发现,DNN声学模型中的重复连接带来的好处很小。 很自然地想知道递归,尤其是双向递归是否是我们体系结构的重要方面。 为了评估循环连接的影响,我们比较了DNN,RDNN和BRDNN模型的训练和测试CER,同时大致控制了模型中自由参数的总数。 表2显示了每种架构类型的结果。
递归模型的两种变体都显示出与非递归DNN模型相比,测试集CER有了实质性的改进。 请注意,我们报告的DNN总参数仅为16.8M,该性能小于RDNN和BRDNN模型中使用的参数总数。 我们发现较大的DNN在测试集上的表现较差,这表明DNN可能更倾向于过度适合该任务。 尽管BRDNN的参数少于RDNN,但它在训练和测试集上的表现都更好。 同样,这表明体系结构本身可以提高性能,而不是自由参数的总数。 相反,由于双向递归和单次递归之间的间隔相对于非递归DNN小,因此使用单个递归网络进行在线语音识别可能是可行的,而不会过度损害性能。
表2:无递归深度神经网络(DNN),具有正向时间连接的递归深度神经网络(RDNN)和双向递归深度神经网络(BRDNN)的训练和测试集字符错误率(CER)结果。 所有模型都有5个隐藏层。 DNN和RDNN在每个隐藏层中均具有2,048个隐藏单元,而BRDNN每个隐藏层中均具有1,824个隐藏单元,以使其自由参数总数与其他模型相似。 对于所有模型,我们在每个时间步长选择最可能的字符,然后应用CTC折叠以获得字符级别的笔录假设。

5.结论
我们提出了一种解码算法,该算法可通过带有CTC训练的神经网络的语言模型实现首遍LVCSR。 这种解码方法消除了对先前工作中基于HMM的系统的持久依赖。 此外,首遍解码演示了CTC训练系统的功能,而没有通过提供的网格修剪搜索空间带来的潜在影响的混杂因素。 尽管我们的结果并没有超过WSJ语料库上最好的基于HMM的系统,但它们证明了基于CTC的语音识别系统的前景。
我们使用BRDNN进行的实验进一步简化了创建基于CTC的语音识别系统所需的基础架构。 BRDNN总体上来说不如LSTM复杂,并且可以相对容易地使其在GPU上运行,因为大型矩阵乘法主导着计算。 但是,我们的实验表明,循环连接对于良好的性能至关重要。 双向递归不仅可以帮助单向递归,而且在需要低延迟在线语音识别的情况下可以牺牲掉。 结合以前基于CTC的LVCSR的工作,我们相信,在没有基于HMM的基础架构复杂的情况下,高质量LVCSR的发展方向令人振奋。