文章目录
课程视频连接:《 深度学习与自然语言处理(4)》
——————————————————————————
1. 矩阵梯度下降及一些小贴士
1.1 梯度下降
还是上节课的梯度下降,我们首先回顾一下:
这样在计算
时一般时采用如下过程,从中就可以发现,其实需要参与运算的部分不多,其中
表示的是第i个输出的第j个输入上的权重:
1.2注意事项
- 仔细定义你的变量并追踪他们的维度变化。
- 链式法则要注意,注意链式法则的每一步求导。
- 对于softmax函数,首先考虑微分正确类型的函数,其次再考虑微分错误类型的函数。
- 如果你对矩阵计算比较困惑,你可以计算出每一个元素的偏导。
- 使用维度控制,当你计算每一步时,应当从理论上控制每一步中每一个运算的矩阵长宽对应。
1.3 窗口模型中的梯度下降
就像我们上节课所说的那样,在命名实体识别中,使用窗口模型来预测当前窗口中心词是否是实体。在梯度下降更新时,我们对于窗口中每一个词进行更新,如果这个词出现过两次,那么它会被更新2次。
更新时如下:
使用窗口模型可以帮助我们命名实体识别,例如当我们出现 出现在中心词前,那么中心词很有可能就是一个表示地点的实体。
1.4 使用词向量的陷阱
如果我们重新训练我们的词向量在我们的任务中,如果在训练集和测试集中的单词不能够也很好的覆盖,那么可能会出现词汇改变不同步现象。例如在预训练语料中存在TV,telly和Television,这三个词时同义词,其向量位置也很一致。
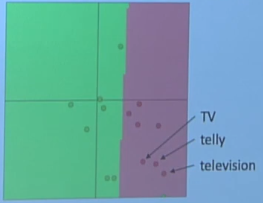
但是,TV和telly出现在训练集中,television只出现在测试集中,那么很有可能出现词向量更新不同步现象。

这种情况对于分类来讲时非常不好的。
所以我们在进行训练时,该怎么做?
Q1我是否应该使用预训练的词向量模型?
答案是在多数情况下当然是这样。因为预训练模型会拥有更多的先验知识,这意味着词向量不仅知道关于你的训练数据中的含义,还知道的更多。那如果数据集中包含极大的数据例如10亿词汇(一般会出现在机器翻译中,常用语言如中文和英文的双语语料很容易找到这么多数据),这时候可能词向量并不够使用,那么更好的建议是随机初始化后再进行训练。
Q2在使用预训练的词向量模型时,我是否应该微调它?
回答时如果你拥有一个小训练集,那么应该固定词向量。如果你同样拥有一个大的数据集,那么你可以进行微调词向量在你的任务中。
2. 计算图模型与反向传播
这里我们详细讲述计算图模型与反向传播过程,这两个是所有深度学习框架的基石。
回到刚开始的例子,我们仍然以此为例:
这四个可以以计算图模型展示出来,其中资源节点是输入,内部结点是操作。
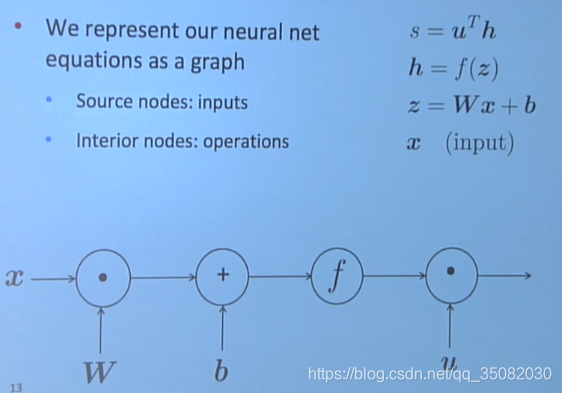
在计算图模型中,数据是以流动的形式完成计算,按照数据流动的方向,我们分为前向传播和反向传播两个部分。
所谓的前向传播则是按照给定的输入,从左到右依次计算即可,就像我们正常的计算一样。
而反向传播,则是神经网络的独特之处,它自右向左依次求偏导后将误差传播回各个部分以更新参数(图中蓝色箭头所指)。

这些偏导我们在上节课中都已经讲过了,根据链式法则求导即可。
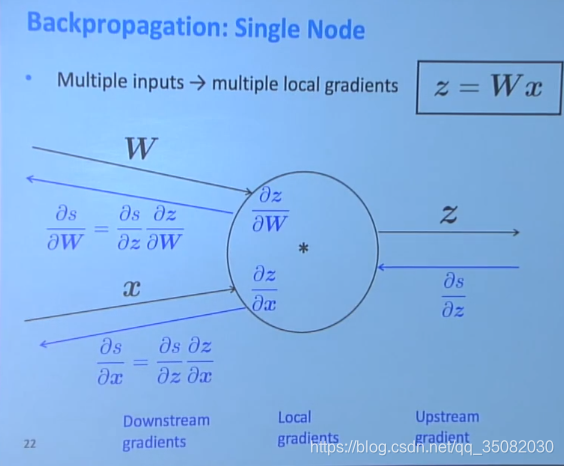
2.1 单个结点的反向传播
单个节点的梯度分为3个部分,上游梯度(upstream),局部梯度(local)和下游梯度(downstream),他们之间的关系是:

对于有多个输入而言,则是分别计算其偏导即可。
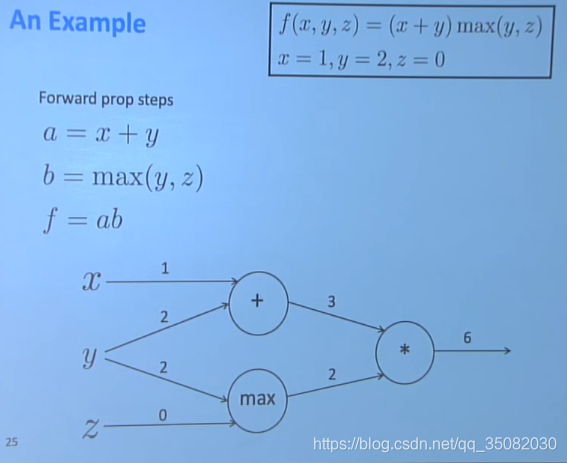
2.2 一个具体的例子
这里以一个具体的例子来详细描述一下如何进行反向传播。
原式为:
根据链式法则,该式就可以转换为以下3个式子:
其计算图如下所示,其中x=1,y=2,z=3:
其局部梯度分别为:
根据我们刚才单个节点的公式,可以获得以下梯度:

在计算梯度时遵循一下3个法则:
- 如果遇到像y一样的时候,它的梯度有2个来源,甚至多个来源时,将这些梯度进行相加获得总梯度。
- 如果遇到像y和z这种二选一的时候,则只需传播已选中的节点梯度。
- 所有的相互连接的梯度都使用乘法进行传播。
还是像我们之前说的那样,运用链式法则,我们会尽可能的减少重复计算量。
2.3 自动求导
一般的,计算图模型中我们需要对于节点的运算进行求导。对于简单的表达式,都会自动的求导。而如果是比较复杂的式子,可能需要你手动指出该式的导数。下面我们使用具体的例子来说明如何求导。
一般的一个计算图模型的代码如下所示:
class ComputationalGraph(object):
#...
def forward(inputs):
# 1. [pass inputs to input gates...]
# 2. forward the computational graph:
for gate in self.graph.nodes_topologically_sorted():
gate.forward()
return loss # the finnal gate in the graph outputs the loss
def backward():
for gate in reversed(self.graph.nodes_topologically_sorted())):
gate.backward()
return inputs_gradients
这里的代码有些部分可能比较难懂,不过没关系,我们会在接下来的Keras源码分析中进行一一解答。
其中一个gate的形式如下所示:
class MultiplyGate(object):
def forward(x,y):
z=x*y
self.x=x #must keep these around!
self.y=y
return z
def backward(dz):
dx=self.y * dz # [dz/dz * dL/dz]
dy=self.x * dz # [dz/dy * dL/dz]
return [dx, dy]
最后友情提醒的是,尽管我们使用了数学手段实现了反向传播过程,但是我们仍然需要来检验我们是否做的正确。一般的,对于一个较小的
,其导数计算可以约等于如下公式:
当然,这只是一种验证手段,在早期的时候,人们都是这样做的。但是现在人们都不会这样做了,因为人们早已经证明这个是正确的,并且编写了如Tensorflow和Pytorch这种库能够进行调用。
现在的深度学习框架都已经可以自动求梯度,如果考虑Keras,完全可以连一些基本的计算图模型都不需要掌握就可进行实验。那么我们为什么要了解这些关于梯度的细节呢?
- 可以更好的理解整个架构。
- 可以更好的调试和改进模型。
- 对于后来的教程如RNN的时候还会有所提及。
3.其他一些注意事项
3.1 正则项
在我们的模型汇中,有大量的参数,这时候,需要使用正则项来防止过拟合遐想的发生。所谓的过拟合现象指的是当我们的训练错误不断减少时,测试错误则是先下降后上升,如图所示。
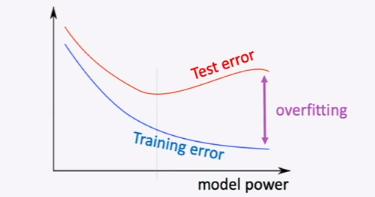
解决这个方法通常使用正则项,一般的使用L1正则和L2正则,L1正则项取决于保留较少且更重要的参数,L2正则项取决于保留较小的参数,使得模型泛化性更好。
有很多参考说L1相较于L2更好,这里考虑的是最终解的形式,一般的,L1具有稀疏解,它可以找到更加重要的参数和特征。但是正是因为L1具有稀疏解,因此它并没有解析解,需要依靠稀疏算法进行求解,这就使得L1的算法并没有L2算法更加高效。其他更多关于L1和L2的细节请看《L1正则和L2正则比较》。
L1正则公式如下:
L2正则公式如下:
3.2 向量矩阵化
使用矩阵化可以使用数学方法在GPU/CPU中分布式加速运算,一般的都可以达到10倍以上的加速效果。其向量矩阵化运算具体细节详见《向量化运算》。
3.3 激活函数
在上一讲中,我们就叙述了为什么要使用激活函数。在此处,我们列举一些常见的激活函数。
sigmoid激活函数
tanh激活函数
硬tanh激活函数
ReLU函数
还要Leakly ReLU和Parametric ReLU等,尽管sigmoid和tanh等在某些情况下仍然被使用,但是一般的我们使用ReLu函数作为常用函数。具体的图像和详细的解析可以看《常用激活函数总结》。
3.4 优化器
在初始化参数时,一般使用随机初始化,但是不能够太大或者太小。
在选择优化器时,一般使用SGD即可,其他情况下可用的优化器包括(Adagrad, RMSprop, Adam,SparseAdam)等,现在常用的主要是Adam,详情可以看《优化器详解》。
优化器和学习率相关。一般的优化器如SGD不会对学习率进行改变,此时学习率是一个较小的值如lr=0.001。太大有可能会发散或根本不收敛。太小的话可能没办法尽早的收敛。
我们手动可以调节学习率,使得在刚开始时学习率大一些,因为此时我们离最终目标可能会很远,然后随着不断逼近目标,我们减小我们的学习率(这有点像打高尔夫球)。而其他的一些优化器如Adam等都会对于学习率进行动态调节。
