BP算法简单的来说就是根据神经网络实际的输出和目标输出(也就是输入样本对应的标记)之间的误差计算神经网络各个权值的过程。
下面的推导过程参考了《神经网络设计》 Martin T. Hagan等著 戴葵等译。
采用BP算法从输出层、经过隐层再到输入层进行层层计算的原因是如果直接计算误差函数相对于各权值的偏导很难得到显式的表达函数(最小均方算法或Widrow-Hoff学习算法),采用从后向前递推的方式大幅度的利用了前期的计算值,也使得网络具备了更多的灵活性。
使用均方误差作为性能指数,那么优化算法的目标就是调整网络的参数使得均方误差最小化。那么根据最速下降算法的原理,第k次迭代计算得到的权值和偏移如下:
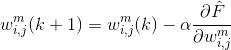
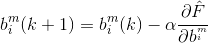
其中,m是层序号,i是神经元在层中序号,j则是一个神经元的输入的序号,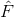
前面就提到了,求这两个偏导是很困难的事情,因此可以使用链式法则从最后一层向前计算。根据链式法则,可以将偏导分解如下:
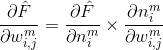
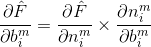
其中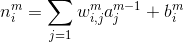
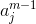
乘号后面的偏导数很容易求得,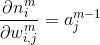
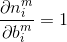
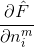
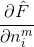
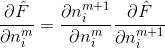
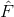
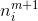
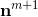
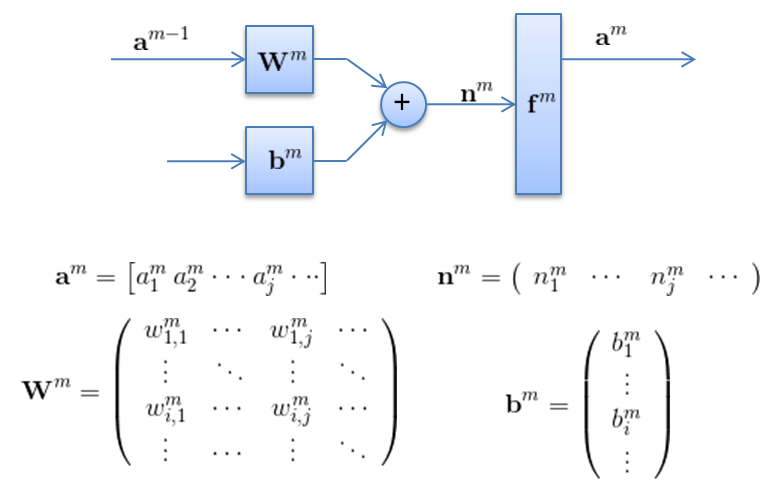
因此,采用矩阵的表示方法来表示神经元的计算,如下面这个图所示。
经过一系列推导可以得到,敏感性(《神经网络设计》这本书中的例子)
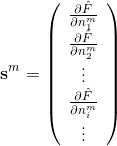
的表达式(注意这是个向量),应该是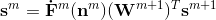
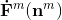
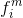
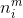
对于BP算法来说,最后一层的计算(第M层)是所有计算的开始。其矩阵形式的表达式为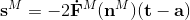
因此如果用矩阵形式表示,那么权值和偏置值更新的表达式是:
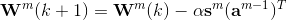
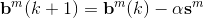
因此,总的说来,反向传播算法需要用到的数据是:
1. 学习率
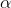
2. 激活函数相对于其输入的导数,用于计算
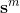
3. 上一层神经元的输出
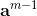
4. 每次迭代的权值和偏移