文章目录
一、BP算法理解
① BP算法全称 (Error) Back Propagation 算法,中文名曰:误差反向传播算法。
②该算法是干嘛的?
计算梯度。更简单点,求(偏)导。对于简单的函数如下:
我们使用肉眼就可以看出其导数为
但是对于特别复杂的多元函数(例如下图),计算偏导数就会非常麻烦,在高等数学(下),我们通常是引入新的变量构造复合函数进行简化(成常见的 可以直接得出导函数的形式),然后利用链式求导法则。
在前馈神经网络中,我们将引入新变量和链式求导结合起来,使用一种新的更加清晰的方式呈现-->计算图(Computation Graph),最终从后向前推导得到多元函数(在机器学习中,该函数通常是目标函数或称为Loss Function)在特定点下的梯度。
计算梯度的目的是为了最小化损失,也就是使得目标函数值最小。这里利用的原理是:函数值在梯度的反方向下降最快。

二、BP算法数据模型
在BP算法的模型中,与感知器算法相似, a i a_i ai
- 在每个输入与隐藏层的每个神经元都相连并且存在权重 v i h v_ih vih
- 每个隐藏层神经元中都存在阈值 γ h \gamma_{h} γh和激活函数f(x)
- 在每个隐藏层与输出层直接都相连并存在权重 ω h j \omega_{hj} ωhj
- 在每个输出层神经元中都存在阈值 θ j \theta_{j} θj和激活函数f(x)
三、误差反向传播
在上面我们获得了这一组数据的输出 o u t p u t output output,我们需要根据均方误差公式调整BP算法中的参数:
输出层阈值 θ \theta θ隐藏层到输出层的权重 ω \omega ω 隐藏层阈值 γ \gamma γ输入层到隐藏层v。
均方误差计算公式:
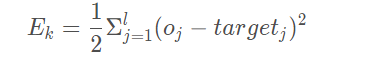
因此对于给定的学习率 η \eta η,更新BP算法的参数。η ∈ ( 0 , 1 ), η \eta η值 过大则容易引起震荡,过小则容易收敛速度过慢。通常设置 η = 0.1 \eta=0.1 η=0.1,在更新参数 θ θ \thetaθ θθ、 ω \omega ω与参数 γ \gamma γ、v中的 η \eta η值并不相同
算法中所有的参数parameters都是同样的更新方式





代码实现
import numpy
import matplotlib.pyplot as plt
import csv
import pandas
import random
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#定义画图函数
def draw_Eks(array):
plt.plot(range(1,len(array)+1),array,label = '累计均方误差')
plt.xlabel("训练次数")
plt.ylabel("数据集单次训练累计均方误差")
plt.legend()
plt.show()
#BP神经网络学习算法
class BP_net(object):
#设置学习率,训练次数,隐藏层神经元个数
def __init__(self , eta , n_inter , q ):
self.eta = eta
self.inter = n_inter
self.q = q
#我们以这个函数为求指数e
#p.exp()的参数传入的是一个向量时,其返回值是该向量内所以元素值分别进行e的指数求值
def Sigmoid(self,x):
return 1.0/(1+numpy.exp(-x))
#隐藏层输入
def input_hide(self,x):
#dot()矩阵点乘函数,v.T表示v的转置,v是输入层的权重
return numpy.dot(x , self.v.T)
#隐藏层输出
def output_hide(self,x):
Alpha = self.input_hide(x)
#Gamma表示隐藏层的神经元阈值
Al_Gam=Alpha - self.Gamma
#bh为隐藏层中第h个神经元的输出
self.bh = self.Sigmoid(Al_Gam)
return self.bh
#输出层输入
def input_out(self,x):
bh = self.output_hide(x)
return numpy.dot(bh,self.W.T)
#输出层输出
def predict(self, x):
beta = self.input_out(x)
#Theta表示输出层神经元阈值
bet_Thet = beta - self.Theta
return self.Sigmoid(bet_Thet)
def fit(self , x , y):
'''初始化输入层到隐藏层的权值
假设单个训练样本xi有3个属性,隐藏层神经元有4个
权重
Vih = [
[v1 , v2 , v3 ]
[v4 , v5 , v6 ]
[v7 , v8 , v9 ]
[v10 , v11 , v12]
]
X = [
[x1 , x2 , x3]
...........
[Xn-2 , Xn-1 , Xn ]
]
隐藏层输入
Alpha = [X[0]*Vih[0] , X[0]*Vih[1] , X[0]*Vih[2] , X[0]*Vih[3]]
隐藏层输出
bh = Sigmoid(Alpha - Gamma)
隐藏层到输出层权值,设隐藏层神经元为4个
W = [
[w1 , w2 , w3 , w4]
[w5 , w6 , w7 , w8]
[w9 , w10 , w11 , w12]
]
输出层输入
beta = [W[0]*bh , w[1]*bh , w[2]*bh ]
输出层输出
y = Sigmoid[beta - Theta]
'''
#初始化输入层的权重
self.v = numpy.random.rand(self.q , x.shape[1])
#初始化隐藏层神经元阈值
self.Gamma = numpy.random.rand(self.q)
#初始化隐藏层到输出层权值
self.W = numpy.random.rand(1,self.q)
#初始化输出层神经元阈值
self.Theta = numpy.random.rand(1)
#创建总均方误差统计数组
self.Eks = []
#执行self.inter次训练
for N in range(self.inter):
#单次训练错误次数初始化为0
Ek= []
#从训练集中抽取单个训练样本
for xi , target in zip(x,y):
#获得输出层输出
self.y=self.predict(xi)
#计算单次输出均方误差
Ek_ = self.y-target
Ek.append(Ek_)
#调整隐藏层到输出层权值和阈值
gj = self.y*(1-self.y)*(target-self.y)
#计算Δθ
Delta_Theta = (-1)*self.eta*gj
#更新θ
self.Theta +=Delta_Theta
#计算Δw
Delta_w = self.eta*gj*self.bh
#更新W
self.W += Delta_w
#调整输入层到隐藏层的权值和阈值
#计算各个ΣWhj_gj的值
Sigma_W_g = self.W*gj
Sigma_W_g = Sigma_W_g[0]
#计算隐藏层各个神经元的eh
eh=[]
for n in range(len(Sigma_W_g)):
eh_ = self.bh[n]*(1-self.bh[n])*Sigma_W_g[n]
eh.append(eh_)
#计算Δγ
Delta_Gamma = [self.eta*eh[i] for i in range(len(eh))]
Delta_Gamma = numpy.asarray(Delta_Gamma)
Delta_Gamma = Delta_Gamma[0]
#更新阈值γ
self.Gamma -=Delta_Gamma
#计算Δv
for n in range(len(self.v)):
Delta_v = self.eta*eh[n]*self.v[n]
self.v[n] +=Delta_v
self.Eks.append(numpy.average(0.5*sum(numpy.square(Ek))))
#为数据集
iris = load_iris()
#数据集的数据
x= iris['data']
#数据集的标签
y = iris['target']
#转换成一列
y = y.reshape(-1,1)
#归一化特征到一定区间的函数,MinMaxScaler模型输入数据必须是二维数据
MinMaxScaler = MinMaxScaler(feature_range=(0,1))
x = MinMaxScaler.fit_transform(x)
y = MinMaxScaler.fit_transform(y)
#划分训练集和测试集
x_train ,x_test,y_train ,y_test = train_test_split(x,y,test_size = 0.3)
#设置学习率,训练次数,隐藏层神经元个数
bp_net =BP_net(eta = 0.01 , n_inter = 2000 , q =8)
#训练样本
bp_net.fit(x_train,y_train )
#画图
draw_Eks(bp_net.Eks)
#仿真输出和实际输出对比图
netout_target = []
for i in range(len(y_test)):
netout_target.append(bp_net.predict(x_test[i]))
print(netout_target)
#逆缩放
y_test = MinMaxScaler.inverse_transform(y_test)
netout_target = MinMaxScaler.inverse_transform(netout_target)
print(netout_target)
for i in range(len(y_test)):
if netout_target[i]<=0.66:
netout_target[i]=0
elif netout_target[i]>0.66 and netout_target[i]<=1.32:
netout_target[i]=1
else:
netout_target[i]=2
#画出实际值和预测值折线图
plt.plot(netout_target, marker = 'o', label = '预测值')
plt.plot(y_test, marker = 'x', label = '实际值')
plt.xlabel('样本')
plt.ylabel('类别')
plt.title('预测类别与实际类别对比图')
plt.legend()
plt.show()
#画出误差率饼图
correctN = 0
wrongN =0
for i in range(len(y_test)):
if netout_target[i]==y_test[i]:
correctN+=1
else:
wrongN+=1
cor_and_wrong=[]
cor_and_wrong.append(correctN)
cor_and_wrong.append(wrongN)
label=["正确","错误"]
plt.pie(cor_and_wrong,labels=label,autopct="%.2f%%")
plt.title('错误率饼图')
plt.legend(loc="best")
plt.show()