绪论:随着计算能力和数据量的提高,出现PASCAL和ImageNet高质量的数据集,使得神经网络成为可能(训练)
一,KNN图像分类算法
- python+Numpy基础
可参看https://zhuanlan.zhihu.com/p/20878530?refer=intelligentunit - 图像分类任务是很困难的
- 运用数据集CIFAR10,实现最邻近算法分类(缺点:训练时间很短,但测试时间很长)
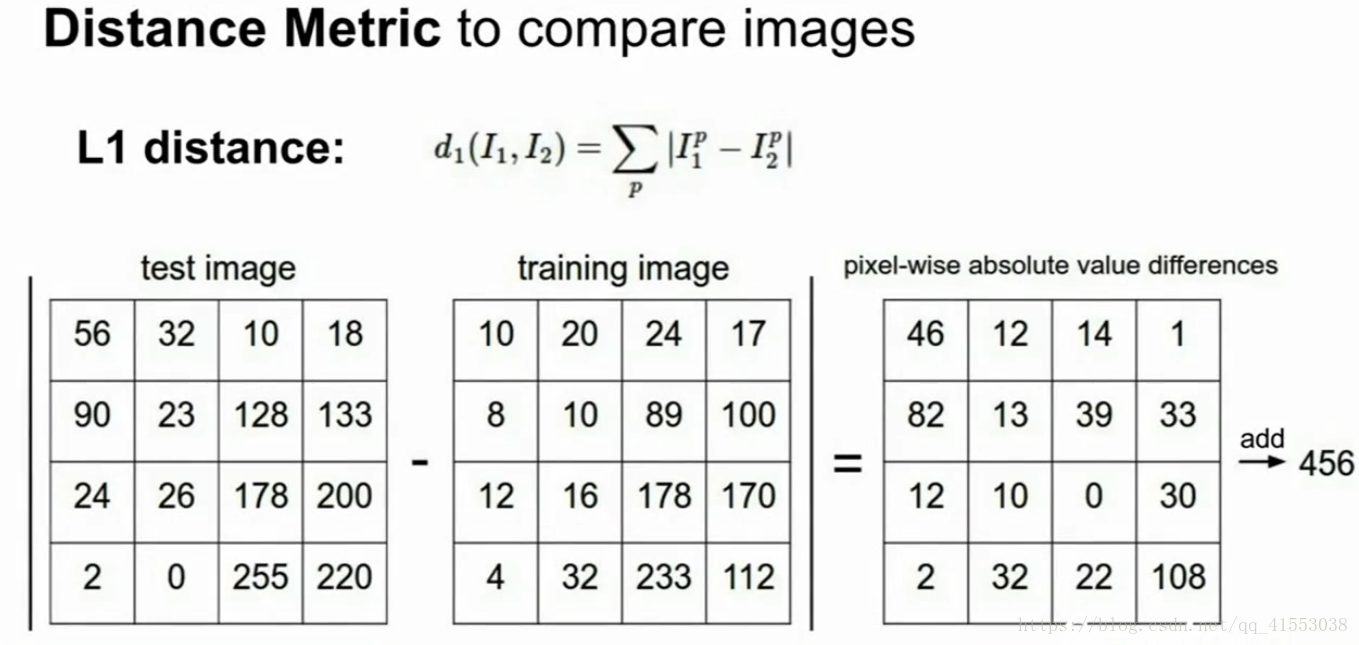
- K最近邻算法,找出K个最近点(曼哈顿距离或欧氏距离),选取投票最多的,K&Distance是超参数
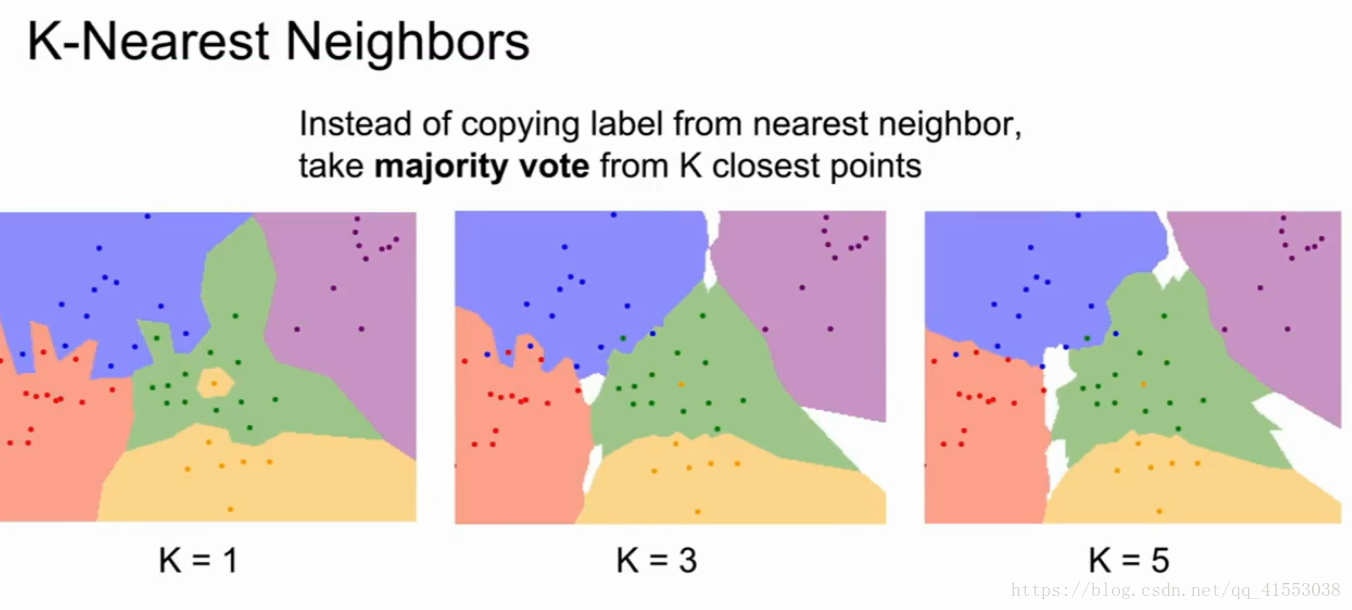
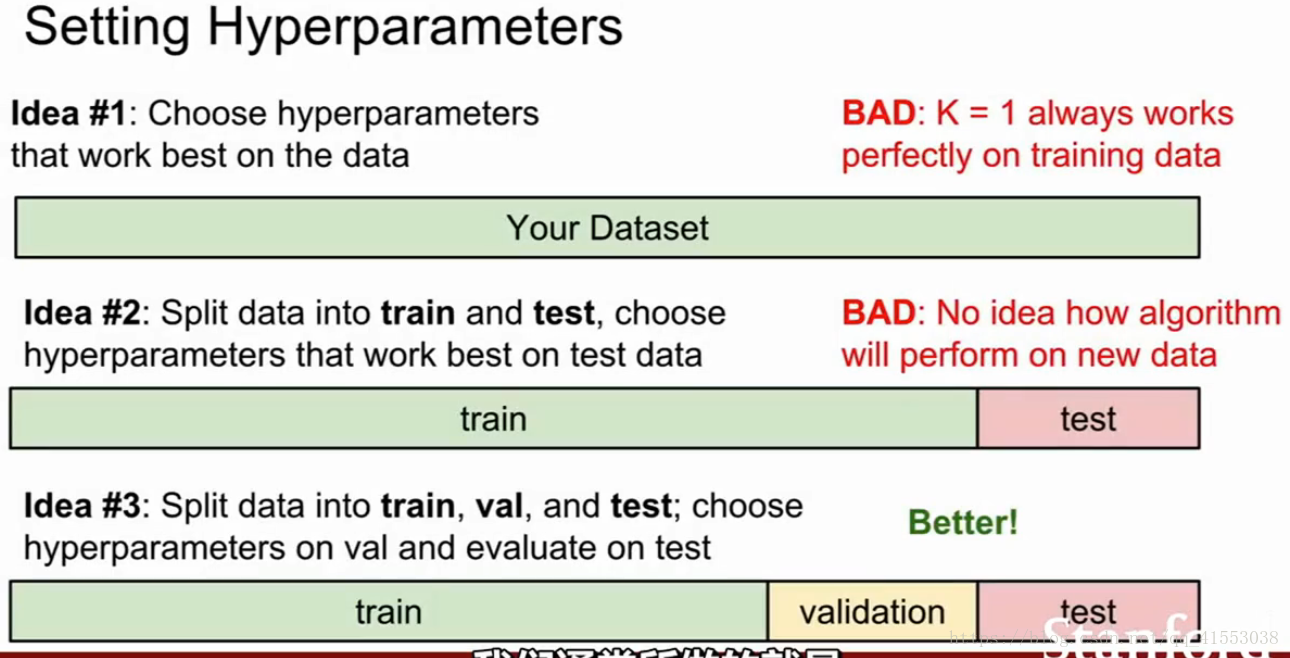
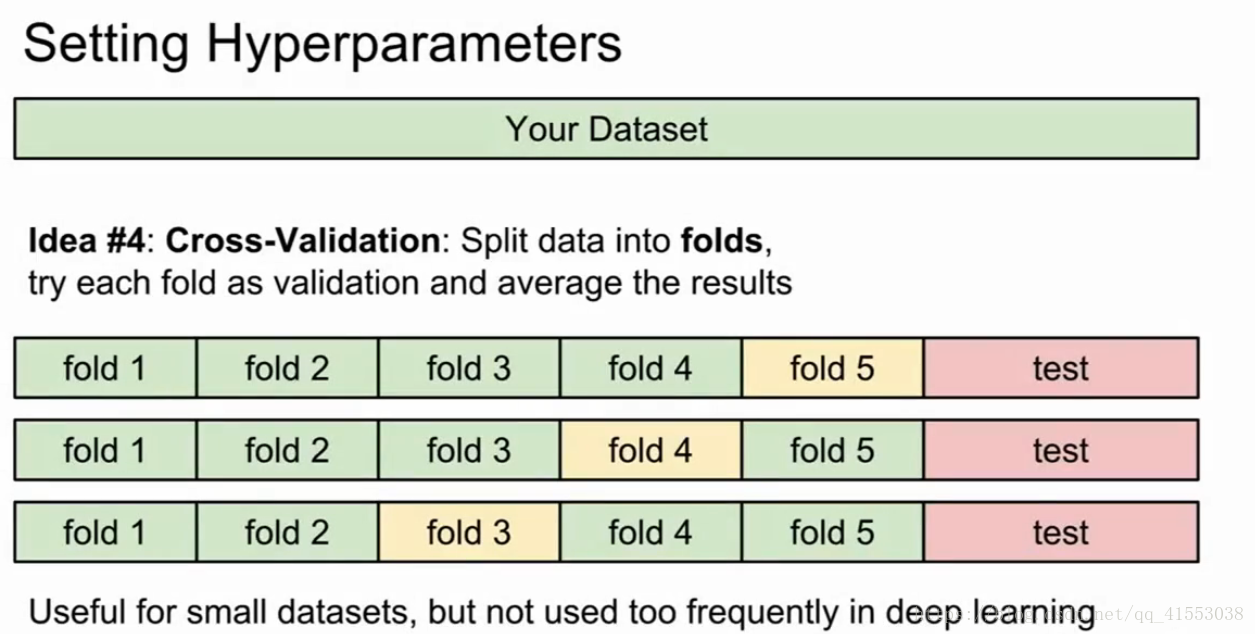
如何选取K和距离指标
#在图像上KNN不常用,测试时间长,向量化距离用于比较图像不常用

二,线性分类器
单独的线性边界划分


三,线性分类器损失
①优化,正则化R(W)【----选取合适的W函数—,-尽可能考虑每个一个元素,将W权重分布扩展开】,和Loss损失函数
②svm,softmax分类熟悉,选择合适的线性分类器(svm具有额外的稳定型,分数变化影响不大,反之softmax就不一样,所有样量变化都要考虑)
③注意两个超参数,步长(学习速率),权重正则化参数lambda
④优化方法,用SGD或momtain等方法找到使损失最小的W值(x给定,y为标签)
四,反向传播
- 倒推出每一个链路(如输入x,y)对最终的结果(输出z)影响有多大
- 正梯度,负梯度(损失随它的增大而减小),所有梯度相乘的过程叫反向传播
- 链式法则:局部梯度和最后一层梯度相乘
- 正向传播存储大量数据,反向传播用掉
- 深度学习框架(如Caffe,torch等)就是一个大的运算门的集合(层),并记录所有层之间联系的计算图!!
- 采样数据,通过前馈得到损失,反馈得到梯度,通过对梯度的使用完成权值更新,这就是神经网络的训练过程
- 问题,雅克比矩阵中的特殊结构如何求得?
五,神经网络
- 实例:逻辑回归二层神经网络训练函数
- 使用权重w和偏差值biase计算出第一个隐含层h,然后计算损失,评分,进行反向传播回去
- 多种常用激活函数(一般默认max(0,x)),如sigmoid函数具有饱和区梯度0,非零点中心,计算x复杂等缺点,max(Relu)函数也有缺点(非中心对称,初始化不佳(如-10)无法激活,注意学习速率不要太高),leaky Relu优化max(0.01x,x),其中0.01为α修正参数可调,maxout集合Lrelu,Relu的优点,只是参数变多了。
- 少量数据可用L-BFGS优化,数据量大的一般用不到
- 神经网络的深度(层数,数据越复杂越多越好,简单则不需要太多)和宽度(各层神经元数)
part2
-
列**. 数据预处理**PCA,SVD等方法
. 权重初始化,待深入,很重要,如Batch Nomalization -
神经网络隐藏层(hidden layer)
-
训练数据要过饱和Overfit
-
超参数调整学习速率,正则化参数(以及差量),更新方式
-
Track the ratio of weight updates / weight magnitudes:

训练神经网络的四个步骤(样本(标准化,初始化权重等),向前传播(得到损失),向后传播(得到每个权重的梯度),用梯度更新【梯度下降】参数(w等))

– 激活函数提供了更多的非线性的数据存储(处理)方式。
下面所讲

– 1,其他参数更新方法,针对SGD更新较慢(y轴快水平慢,波动式前进),但一般还是默认用SGD
- 1,moumentum更新,收敛更快(mu为超参数,v为速度(可初始化为0))好
- 2 nestero momentum (Nag)好好
3,adaGrad update(一般在凸问题中用,回停止学习-0)
针对不同方向的梯度调整快慢(补偿)–通过分母(梯度平方),大慢小快
3.2改进版(不会停止学习)
1e-7是平滑因子,只是未来防止它变0
4,另一种
5,Adam更新(结合MOMENTEUM和RMSprop-like)很好,可以经常采用







beta是超参数0.9,0.995

1.2,优化学习速率(超参数,可用衰减函数控制(一阶函数))

其他优化方法
二阶函数,求出梯度(碗的曲率),知道怎么走就不需要学习速率更新就知道怎么到达最低点了,收敛(但hessian矩阵太大求逆计算量巨大,而基本不采用)
再优化(数据集不大时可用)一般也不用


