周志华的西瓜书机器学习被誉为是机器学习的入门宝典,但是这本书对于深度学习的知识介绍非常少,仅仅只是在第五章《神经网络》中对其进行简单的概括。
这一章对于深度学习的介绍非常浅显,没有很深入的对其中的知识进行挖掘,也没有很复杂的数学推导。
博主在这里对反向传播算法进行数学推导,这里我使用的方法和周老师有些不同,或许更方便一些。
一、反向传播算法概述
误差反向传播算法又称为BP算法,是由Werbos等人在1974年提出来的,我们熟知的Hinton也对该算法做出非常巨大的贡献。这是一种在神经网络中最为有效的训练算法,直到现在还在深度学习中发挥着极其重要的作用。
它是利用输出后的误差来估计输出层前一层的误差,再用这个误差估计更前一层的误差,如此一层一层地反传下去,从而获得所有其它各层的误差估计。这是一种属于有监督学习的方式,可以对网络中的连接权重做动态调整。
反向传播算法和正向传播算法相对应,一起构成了神经网络的整个过程:
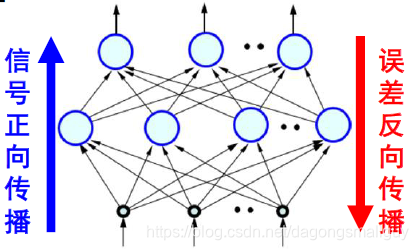
二、数学推导
在这里,为方便对模型的理解和数学推导,我们没有采用西瓜书中的模型表示方式,而是用下图来对其进行简化:
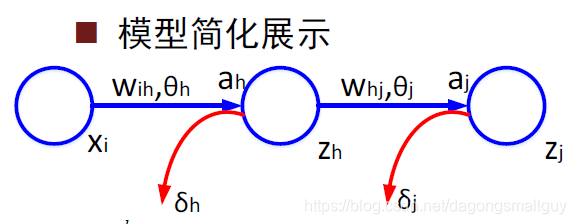
- 与输入层相关的变量和参数:下标
i
- 与隐含层相关的变量和参数:下标
h
- 与输出层相关的变量和参数:下标
j
- 激励函数的输入:
a
- 激励函数的输出:
z
- 节点误差:
δ
则输入隐藏层和输出层的量分别为:
ah=i=1∑dwihxi+Θh
aj=i=1∑dwhjxi+Θh
隐含层和输出层的的输出分别是:
zh=f(ah)
zj=f(aj)
函数的误差损失为:
Ek=21j=l∑(tj−zj)2
BP算法是基于梯度下降的策略,以目标的负梯度方向对参数进行调整,所以我们用链式法则求出误差的梯度为:
∂whj∂E=∂zj∂E∂aj∂zj∂whj∂aj
由前文我们得到的关系有:
∂whj∂aj=zh
∂zj∂E∂aj∂zj=∂aj∂E=−(tj−zj)f′(aj)
所以,综上所得,我们有:
g(h)=∂whj∂E=∂zj∂E∂aj∂zj∂whj∂aj==−(tj−zj)f′(aj)zh
对于误差
Ek,当我们给定学习率为
η时有:
Δwhj=−η∂whj∂Ek
将
g(h)和
b(h)带入后有:
Δwhj=ηg(h)b(h)
则得到上式之后,则我们根据
v←v+Δv进行参数更新。
至此,反向传播算法的推导过程全部完成,其他参数的更新与上文相同,这里不再赘述,读者感兴趣可以用这种方法自己来完成。