版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_41427758/article/details/80468019
Motivation
- 大规模的数据集是成功应用深度学习的关键,对于很多任务来说,没有大的数据集来学习到通用且鲁棒的特征,同时不同的学者提出了许多小的数据集,能否利用multi-domain learning来利用与同一个任务相关的不同数据集来学习得到更加通用且鲁棒的特征呢?
- 在多领域学习中,因为领域偏差的存在,一个对某个领域有效的神经元可能对其他领域无用,对于一个多领域学习的模型,如何处理这些神经元呢?
Contribution
- 提出了一个从多个领域来学习通用特征表示的pipeline,得到的特征在每个领域表现的都不错
- 提出了Domain Guided Dropout来舍弃对于每个domain没用的神经元(能提高模型的泛化能力)
- 本文的方法在多个数据集上超过了SOTA的方法。
本文对Dropout在多领域学习问题上的应用的改进很有意思,值得思考借鉴
1. Introduction
- domain: 数据集从同一个潜在的数据分布中采样得到
- Multi-domain learning: 解决从针对同一个任务较小的不同domain的数据集中学习好的表示;不同的domain的数据能增加多样性,能提高特征的鲁棒性
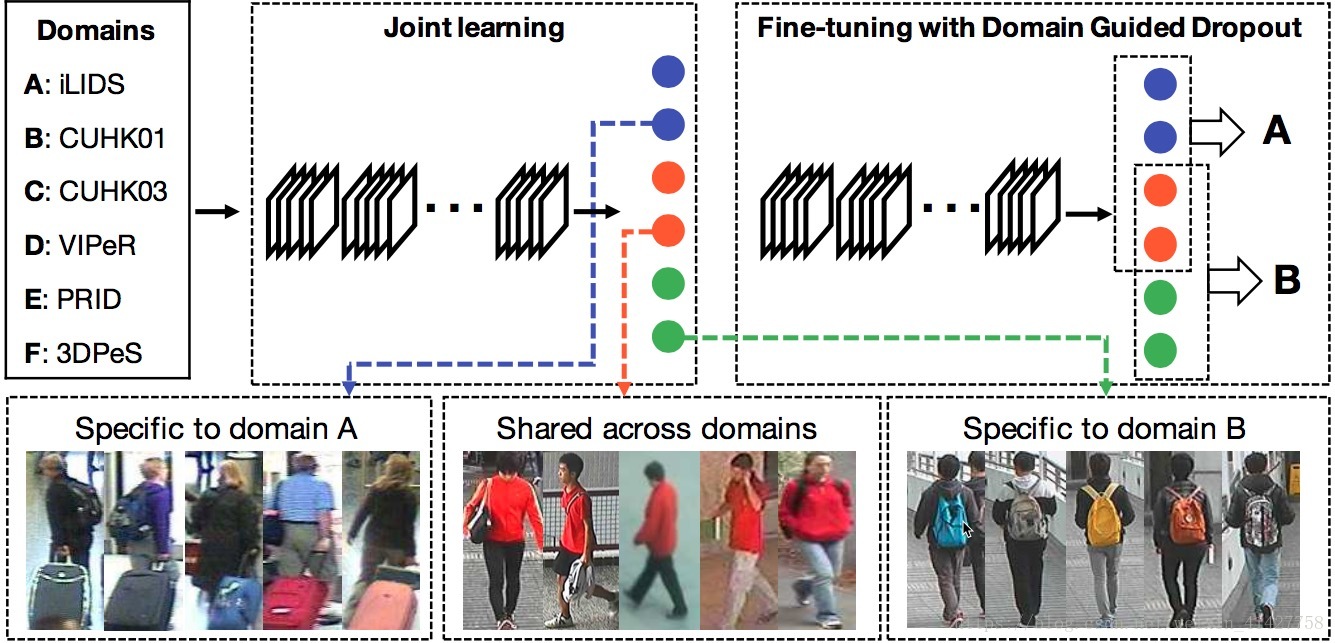
- 如下图为不同domain的数据:
- 动机与贡献

2. Related Work
- 学习domain invariant不变的特征的工作:
- the multiple kernel variant of Maximum Mean Discrepancy来提高网络的正则化
- reversing the gradients of the domain classification loss来降低源数据与目标数据分布的不匹配
- Dropout:主要作用降低过拟合
- 标准Dropout:固定失活概率
- adaptive dropout scheme:通过binary bilief network来预测每个神经元的失活概率
- 本文工作利用domain信息来引导dropout过程
- Person re-id相关工作:
- 主要集中在特征提取与度量学习
- 目前也有一些工作更注重现实的场景:通过检测算法从图片中得到行人–>不对齐问题
3.Method
- 整体框架如下图:
- 混合所有domain的数据在一起,通过设计的CNN用单一的softmax loss进行训练
- 对每个domain的所有样本,通过前向传播计算每个神经元对目标函数的平均影响
- 将standard Dropout替换成Domain Guided Dropout layer
- 可以通过针对某个领域进行fine-tune得到对应领域的特征表示
3.1. Problem formulation
- domains, 每个domain有 个人的 张图片, 为所有的训练样本, 第i个domain的第j个样本,
- 目标是在上述数据集上学习通用的特征
- 训练阶段:本文采用分类损失
- 测试阶段:比较probe与gallery图片的欧式距离
3.2. Joint Learning objective and the CNN structure
- 由于不同re-id数据集上的行人身份是不同的,本文的做法是将所有数据集的人的身份合并然后重新label。采取单任务,即用一个softmax classifier
与特征提取器
:
- 单任务的方式可以捕捉到domain偏差以及行人的外表以及属性
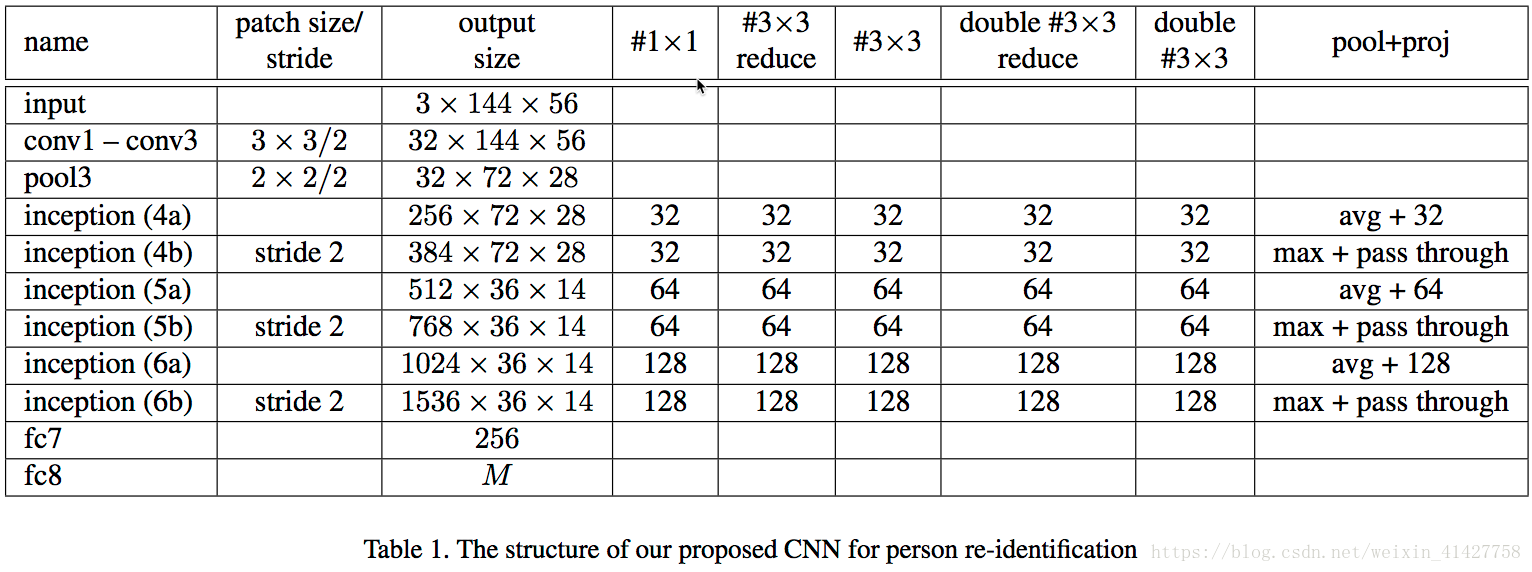
- 行人图片尺寸都相对较小以及不是正方形,不适合直接使用在大量高分辨率且丰富的细节的ImageNet训练的网络,本文借鉴GoogleNet的思想,从头搭建以及训练了一个网络,具体结构如下表:
3.3. Domain Guided Dropout
- 特定神经元的重要性:在移除该神经元损失的增加
- impact score的公式:
- 对于每个domain ,通过其所有样本上的 期望得到平均impact score
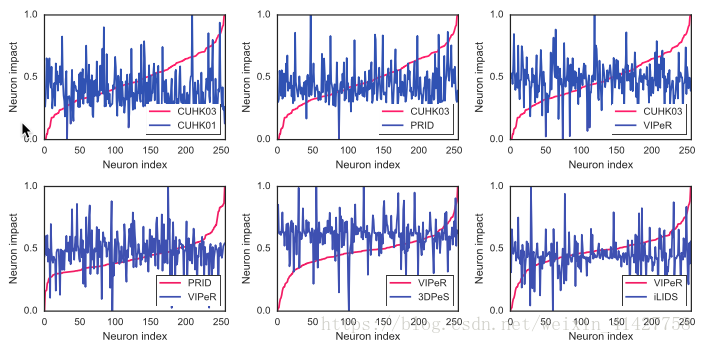
- 下图展示了在不同领域间的神经元影响分数
- 原始的计算所有impact值得方法需要 前向传播,当 很大时候计算开销很大,本文采用 的二阶泰勒展开式近似
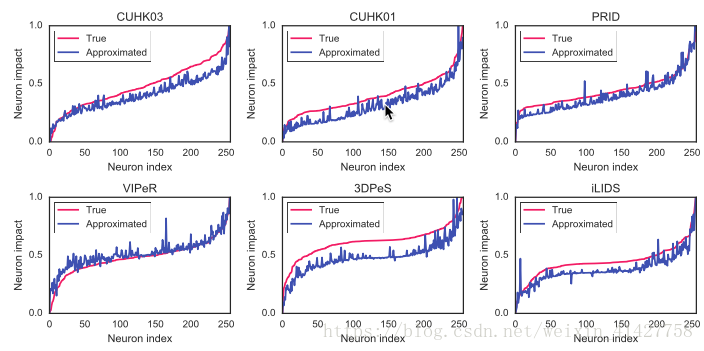
- 下图展示了fc7层近似值与真实值的差异
- 得到所有的
后,通过impact得分来引导dropout继续训练10个epoch的CNN(消除domain bias),学习率采用多项式衰减(初始0.01, 多项式参数为0.5)对于不同的domain,根据impact得分
得到二进制mask
- 确定式:
- 不确定式:
- 为控制 影响失活概率的温度,当 ,等价于确定式,当 ,等价于标准0.5失活概率的Dropout
- 确定式:
- 在测试阶段,对于确定式,影响因子小于0的神经元会被抛弃,对于不确定式,保留所有的神经元的响应并通过 来缩放
4. Experiments
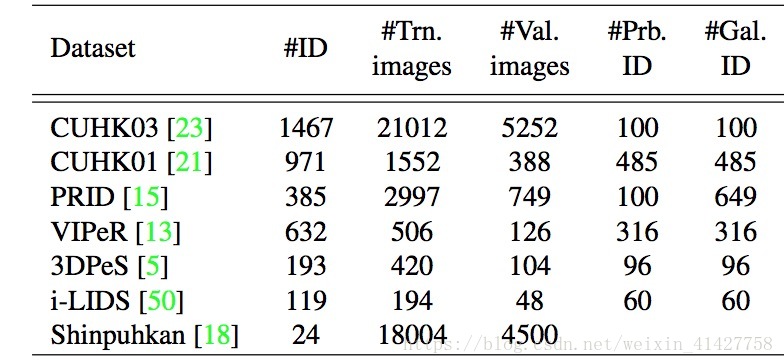
4.1. Datasets and protocols
- CUHK03
- CUHK01
- PRID:2 camera各有385、749个行人,其中200个同时出现在两个摄像头中
- Shinpuhkan:16个摄像头,24个行人,22000张照片,具有很大的类内差异
- VIPeR
- 3DPeS:193个行人
- iLIDS:机场监控下119个行人,会产生由其他行人以及行李带来的遮挡问题
- 细节:
- 同时使用了CUHK03中的手工框以及检测框
- 在PRID上对训练集上每个行人从视频中采样10张图片
- CMC评价指标
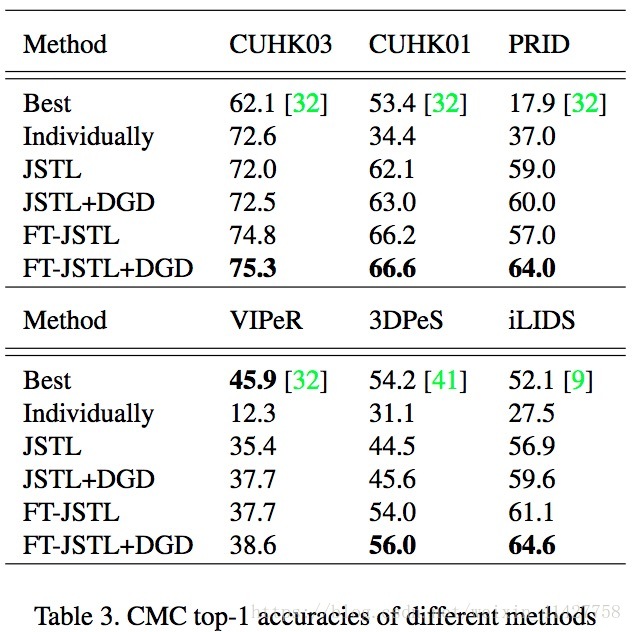
4.2. Comparison with state-of-the-art methods
- 方法:
- baseline:在每个domain上训练网络
- 合并所有domain,jointly with a single-task leanring objective(JSTL)从头训练
- 将上述方法训练好的模型通过deterministic Domain Guided Dropout(JSTL+DGD)继续训练几个epoch
- 在每个domain用stochastic Domain Guided Dropout微调(FT-JSTL+DGD)
- 另外一个baseline:在每个domain上用standard dropout微调JSTL model
- 结果如下表:
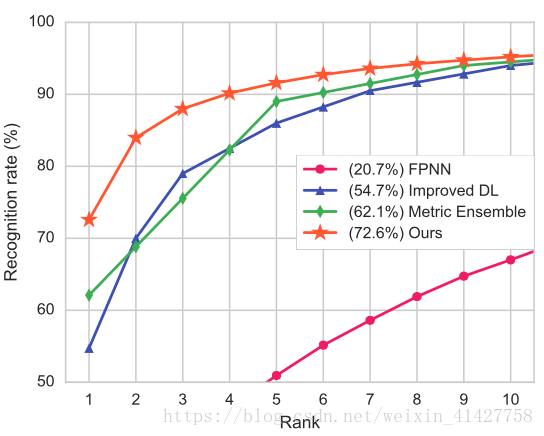
CNN structure:对本文网络模型有效性的验证 - 在CUHK03上72.6%,超过SOTA方法10%,超过之前DL方法18%
- 当数据集足够大时,使用分类损失更容易训练CNN
- CMC曲线如下:
Joint Learning:
- 从多个domain学习到的特征对所有domain更具有通用性
- CUHK03的性能相比单独训练下降了,说明学习到的特征对于不同数据集更加鲁棒,但是在单独的较大数据集上判别力降低了
- 本文对于mini-batch没有平衡不同领域的数据,对于较小的数据集数据给与更多的权重可以进一步降低过拟合
Domain Guided Dropout:
- 相比JSTL,JSTL+DGD对所有domain提升了大于0.5%–2.7%,说明了DGD在训练不同领域网络时的正则效果
- 相比FT+JSTL,FT + JSTL + DGD提了大约3%,说明DGD提升了特征的通用性
4.3. Effectiveness of Domain Guided Dropout
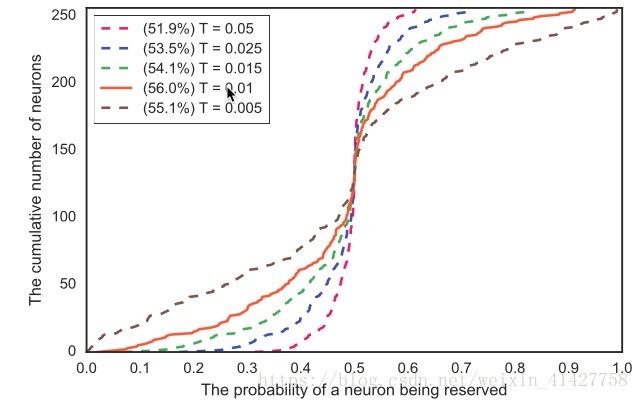
Temperature
: 不同T对于stochastic Domain Guided Dropout的行为与性能影响较大,通过实验来确定
的取值,实验结果如下图:
Deterministic vs. stochastic: 对比了两种方法在JSTL + DGD以及FT-JSTL + DGD阶段的效果,如下图:
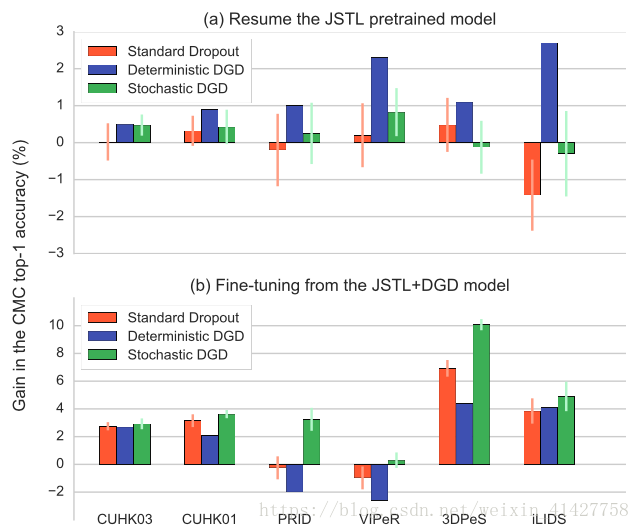
- 结论
- deterministic DGD更适合联合所有domain训练CNN
- stochastic DGD更适合在某个domain微调
Standard Dropout vs. Domain Guided Dropout:
- 在JSTL模型上继续训练:
- 因为已经收敛,Strandard Dropout并不能带来提升
- deterministic Domain Guided Dropout策略能够提升所有domain的性能
- 上图(b)中橙色与绿色的条验证了在微调CNN模型stochastic Domain Guided Dropout的有效性,利用Domain信息来更好的正则化网络
- 下图反应了不同domain提升与负影响神经元之间的关系:小数据集有更多的无用神经元
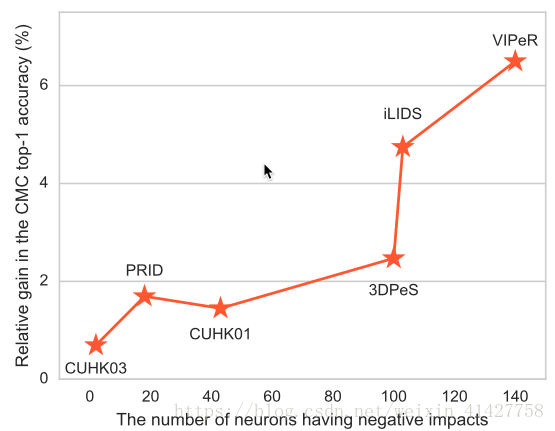
5.Conclusion
- 提出了一个从多个domain学习通用且鲁棒特征的有效pipeline
- 使用Domain Guided Dropout算法促进特征学习过程
- 在多个Re-id数据集上进行了实验验证了本文方法的有效性,性能超过了许多SOTA的方法