今天分享一篇发在今年NIPS上的一篇论文,论文全称如下:
FD-GAN: Pose-guided Feature Distilling GAN for Robust Person Re-identification(想要论文的留言~)
这篇论文的工作主要是不用姿势辅助信息,提出只学习身份相关的特征,而不用姿势无关的特征,从而不需要额外的pose information也减少了计算量,从而降低了复杂程度。核心是这个工作用了一个二分支siamese网络来学习多个判别式模型,此外,领完一个工作是除了identity discriminator以及pose discriminator之外,本文还提出了一种same-pose loss,主要是根据siamese网络最小化两个生成的fake image之间的pose loss。这样也就使得两个相同的图片的两个生成图片更加相似。
看下面的网络架构图能更好的的明白全文的工作:
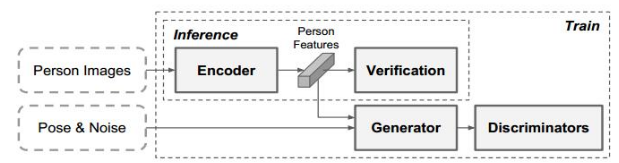
上图是siamese分支网络中的一个分支,利用位pose引导的图像发生器和鉴别器,学习鲁棒的与身份相关和与姿态无关的表示。在推理过程中,不需要姿态信息和额外的计算成本。
下图是整个Siamese分支网络架构:
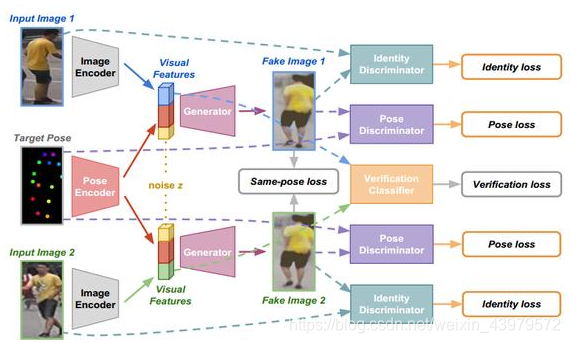
从上图可以清晰地看到这篇文章所做的工作,在损失函数方面,作者一共考虑了五种损失函数的计算,在下文详细讲解。看一下每个模块的具体架构:
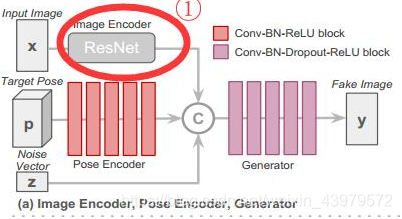
(1) 上图是生成器G和图像编码器E的网络架构,即输入一张图X1经过Resnet网络编码特征,得到一个2048维的向量,同时设定的Target pose也会经过pose encoder进行编码到128维向量,最后再加入256维的noise,将三者融合共同输入generator网络得到fake image y,对于另一张图片X2亦是如此。
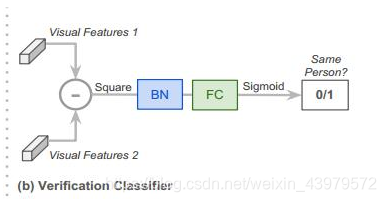
(2)上图是验证分类器的网络架构,即对应图②中绿色和蓝色部分的特征
损失函数定义如下(binary cross-entropy loss):
损失函数之一
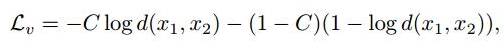
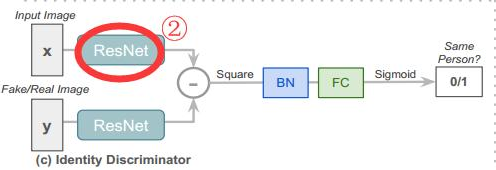
(3)上图是身份判别器的网络架构,即判断输入图像与生成的图像是否是同一人,注意上图图中圈出的②与(1)中的①不共享权重,因为在①中的目的是学习姿态无关的特征,②是用于区分真假图
在这里产生一个identity loss…即输入图x1与生成图y之前的损失如下,当生成的image为真时表示成Let yk’ represent the real person image having the same identity with input image xk and the target pose p(引文有两个分支,所以x1,x2表示一开始输入image)
损失函数之二
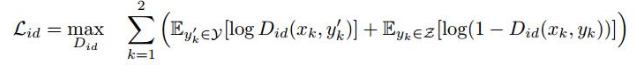
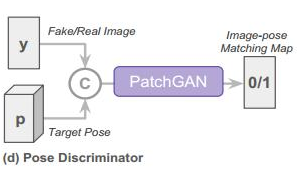
(4)上图是姿态判别器的网络架构,即生成图像与原目标pose之间的一个衡量,验证生成图yk是否与target pose匹配,损失函数定义如下:
论文之FD-GAN: Pose-guided Feature Distilling GAN for Re-id
损失函数之三
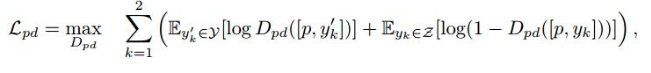
(5)作者还考虑了生成的真假图之间的损失,即Reconstruction loss,定义如下:
损失函数之四
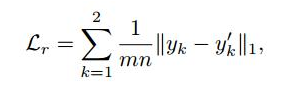
其中mn是真实/虚假图像中的像素数,(当输入图像X1,X2和目标POSE p没有对应的ground truth图像yk’时,这个损失就没有被利用。)
(6)图像发生器G的作用是帮助图像编码器只提取与位置无关的信息。作者将同一个人的两幅不同的图像和相同的目标姿态输入到Siamese网络的两个分支中,如果这两个分支中的条件视觉特征真的只是与身份相关,那么生成的两幅图像在外观上应该是相似的。因此,提出了一个相同的姿态损失(如下),称为Same-pose loss,以最小化两个生成的图像之间的相同的人与目标的姿态的差异
论文之FD-GAN: Pose-guided Feature Distilling GAN for Re-id
损失函数之五
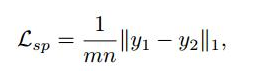
整体损失定义:

实验部分:
三个数据集:Market-1501, CUHK03 , 以及 DukeMTMC-reID .
看一下实验对比:
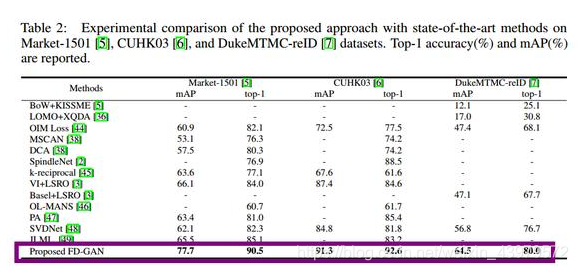
作者提出的FD-GAN还是取得了很好的效果,代码打算这几天研究一下复现看看效果。有兴趣的可以留言讨论~