行人重识别之cross domain
Self-similarity Grouping: A Simple Unsupervised Cross Domain Adaptation Approach for Person Re-identification (ICCV2019)
核心思想:两个数据库之间,图像风格迥异。如果将图像进行分割,那么每一块之间的风格差异或许会小一点。这样,也就学到了鲁棒性更强的特征。
本文的框架如下图所示:模型在Source上经过了有监督的预训练。
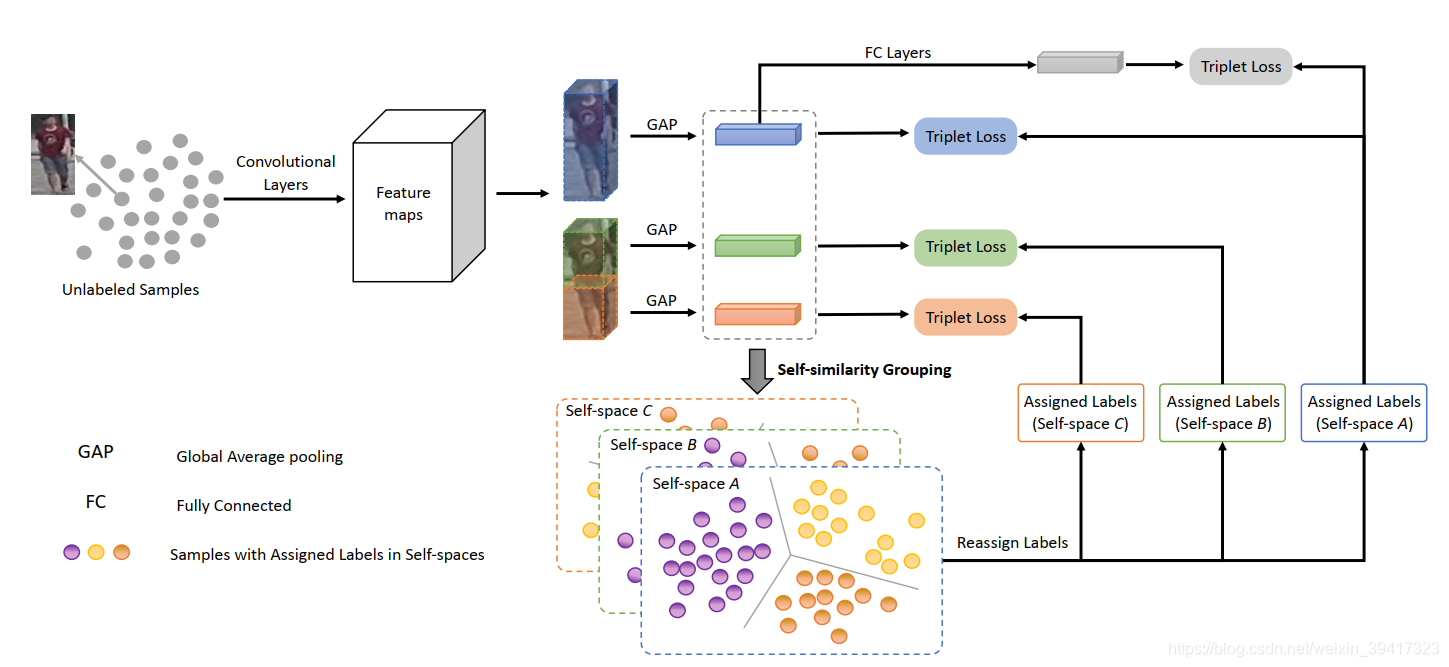
蓝色、绿色、红色分别代表了整个图像,上半图像和下半图像。分别提取出各自的特征向量。灰色的是将三者连接在一起。
对蓝色、绿色、红色三类特征向量分别进行聚类,每一个特征向量就获得了对应的标签。灰色的标签直接和蓝色的保持一致。所以,一个人的上半身、下半身、全身对应的标签可能是不一样的。这就与开头的思想相对应,学习的过程中不会拘泥于整个图像的标签,更具有灵活性。
有了标签之后,对每一类特征向量分别使用最难三元组损失对模型进行训练。
本文的另外一个创新点如下图所示:
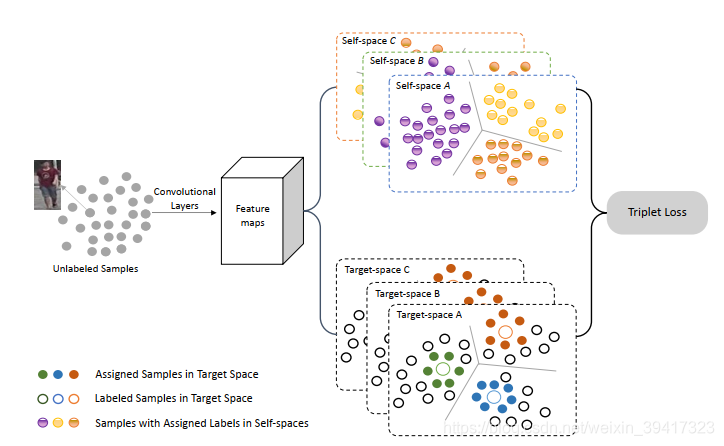
上半部分我们已经介绍过,重点介绍下半部分。
对整张图像的特征向量聚类结束后,总共分为了N类。从每一类中随机挑选一张图像,共N张,分别提取该图像的全局、上半部分、下半部分的特征向量,作为字典。在采样的过程中,对被采到的图像提取三类特征向量,每一类分别和上述提到的N张图像对应类别的特征向量比较,距离最小的,就和其保持相同的标签。在此基础上,再进行最难三元组损失。
总结:可以看出,cross domain问题往往会涉及到聚类算法赋予图像假标签。所以聚类算法的设计至关重要。另外,分块的思想居然可以应用于该问题中,确实很有启发意义。
完
欢迎讨论 欢迎吐槽
