Deep Spatial Feature Reconstruction for Partial Person Re-identification: Alignment-Free Approach
Abstract
Partial 行人重识别是一个挑战,只有身体的一部分能够拿来匹配。现有的研究都不灵活。我们提出一个快速并精准的匹配方式。用FCN产生特定大小的空间特征图,从而像素级别的特征能够一致。(?没看懂是什么意思)。为了能匹配不同尺寸的行人图片,提出DSR(本文采用的方法)从而避免精确的对齐(!精确的对齐不利于Partial识别)。当下流行用字典学习模型来计算不同空间特征图的相似性(!所谓字典学习模型就是一块块去寻找和匹配),这种方法容易产生重建错误,DSP正是探索这个问题。我们期待采用FCN来降低不同行人耦合图像的相似性,并增加相同行人图片的相似性(?FCN常用在分割上,在这里是如何实现这个功能的)。相比其他一些经典的方法,在两个Partial行人数据集(?Partial行人数据集,特定的数据集)中做出实验的结果表明了DSR方法的有效性。另外,他在Market1501上Rank-1的精确度达到83.58%。
1. Introduction
行人重识别在最近几年已经取得和较大的进步,已有的方法都假设每张都是完整行人的图片。然而,在现实世界的运用中,完整的行人图片的假设是很难满足的,我们仅仅得到每个人的一部分去查询。例如,在Fig.1中显示,当一个人被移动的物体(例如,车辆、其他的人)或者固定的遮挡物(如,树、栏杆)遮挡时,常常出现partial行人图片。因此,闭路电视摄像头和视频监控中逐渐增加的识别需求,partial行人重识别引起了重大的科研关注。然而,很少的研究关注于如何识别一个行人图片的任意部分,让partial行人重识别变成一个挑战,在当下的研究中仍然没有解决方案。从这个角度来说,研究parital行人重识别问题是必要的和至关重要的对于科研机构或者实际的检索运用。

当很少的parital行人观察被提供时,已存在的行人重识别方案大多数不能鉴别。具体的,去匹配一个任意大小的行人,有些机构重新排序从而把任意大小的行人片裁剪到固定大小的图片。然而,这个表现将很大的降级,因为不受欢迎的定义(Fig.2(a))。对于这个问题,滑动窗口匹配(SWM)实际介绍了一个可能的方案,设置一个同样大小的滑动窗口作为探测图像,并且整合他在每一个gallery图像中寻找最相似的区域(Fig.2(b))。然而,当探测人物的大小比gallery人物的大小更大的时候,SWM就不能很好的工作了。有一些行人重识别方法考虑基于部分的模型,提供一个可选择的partial行人重识别方案(Fig.2©)。尽管这样,他们的计算代价是相当的大并且他们需要在之前严格的行人对齐。除了这些限制,基于部分的模型和SWM重复的提取分区域的特征,没有分享计算,这浪费了许多的计算效率。

在这篇论文中,我们提出了一种新颖的和快速的partial行人重识别框架,匹配不同尺寸的一对行人图片。在提出的这个框架中,FCN用来产生相应尺寸的空间特征图,这能考虑一个像素级别的特征矩阵。在人脸识别当中字典学习实现很大的成功,收到它的激励,我们运用一种叫做DSR的端到端模型,期待在探寻空间图中的每一个像素都能在整个查询图片的基础上被稀疏的重构。用这种方法,这个模型和像素大小相独立,自然的跳过时间上对齐的步骤。特别的,我们为FCN设计了一个目标函数,从同一个人中提取的空间特征图的重构错误跟小,当从不同ID获得的空间特征图不能很好的重构彼此。概括来说,我们工作的主要贡献总结为一下四点:
- 我们为partial行人重识别问题,提出了一个叫做DSR新方法,这种方法不需要对齐并且 对任意大小的行人图片都合适
- 我们第一次整合稀疏重构学习和深度学习在同一个网络中,通过最小化相同行人的重构错误和最大化不同行人的重构错误,来训练一个端到端的深度模型
- 除此之外,我们用block水平的取代了像素级重构,并且发展一个多尺度合成模型去增强表现
- 实验结果证明我们提出的方法在Partial-REID和Partial-iLIDs两个数据集上实现很好的结果,无论在精度上还是在效率上。
这篇论文的剩余的部分如下组织。在Sec.2,我们回顾了关于FCN,SRC,和已存在的partial行人重识别算法的相关工作。Sec.3 介绍了深度空间特征重构的具体技术细节。Sec.4介绍了实验结果并分析了计算效率和精度上的表现。最后在Sec.5,总结了我们的工作。
2. Related work
由于身体部分被遮挡或者只拍摄到身体的一部分,造成身体的一个部分与整体之间的比较。如果采用传统的方式去对齐比较,必然会降低这一部分图片的准确度。
对于这些图片进行处理,精度上必定能有较大的提升。
因为提出的模型是一个基于FCN和SRC(Sparse Representation Classification)的深度特征学习方法,我们在这一节简要的回顾相关的工作。
2.1 Fully Convolutional Network
2.2 Partial Person Re-identification
Partial Person ReID以往的方法
有些方法是将这些遮挡的部分调整到固定大小,然后提取固定长度的特征向量去匹配(2014年的论文)。这种方法会造成不想要的形变。另外一种方法,提出局部的匹配,AMC+SWM模型,前者是局部层次的匹配,后者提供全局的匹配,但开销太大(2015年的论文)。还有一种方法是借鉴人脸的部分识别,提出了一个MKD-SRC模型,提取人脸特征,在重新变换。但是这种基于关键点的变换并不顶用。(2013年的论文)。本文提出一个快速和精准的方法,深度空间特征重构,去处理partial行人图片。
3. The Proposed Approach
3.1 Fully Convolutional Network
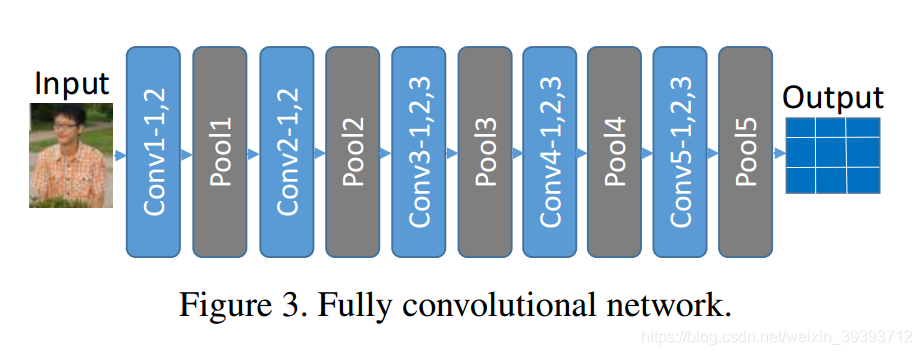
在视觉分类任务中,CNNs作为特征提取器,需要一个固定大小的输入图像。然而,因为partial 行人图片的大小不定,不能给CNNs一个固定大小的输入。实际上,这个需求来自全连接层,它需要固定大小的输入。(?)。卷积层用一个滑动窗口的方式操作,产生一个相应大小的输出。要处理一个任意大小的行人图像,我们抛弃了所有的全连接层去执行全连接网络,这里只有卷积层和池化层保留。(这里的全连接网络并不是我开始所想的FCN,那种产生Mask的,就是把最后的全连接层去掉,就成了全连接网络)。因此,FCN仍然保留空间坐标信息,能够从任意大小的输入中提取空间特征图。在Fig.3中展现了所提出的FCN网络,它包含13个卷积层和5个池化层,最后的池化层产生身份特征图。
3.2 Deep Spatial Feature Reconstruction(DSR,本文最重要的一个部分了)
在这一部分,我们将介绍如何测量一对不同尺寸行人图片的相似度。假设给我们一对行人图片,一个是行人图片的任意尺寸I,另一个是完整的行人图片J。相应大小的空间特征图
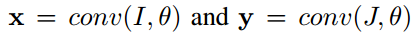
从FCN中得到,theta代表了FCN中的参数。X代表一个矢量化的w *h * d张量,w,h,d分别代表宽、高和x的通道数目。如Fig.3所示,我们把X 分成N个blocks xn,n = 1,…,N,N= w * h,每个block的大小是1 * 1。
3.3 Fine-tuning on Pre-trained FCN with DSR
3.4 Multi-scale Block Representation
4. Experiments
在这些数据集中我们关注5个方面,(1)探索行人图片形变的影响(2)多尺度块表示的的好处(3)同其他parital行人重识别方法的比较(4)和其他方法相比的计算时间(5)用DSR微调的效率