笔记目录(部分笔者省略)
Self-paced Contrastive Learning with Hybrid Memory for Domain Adaptive Object Re-ID
arXiv:2006.02713v1 [cs.CV] 4 Jun 2020
域自适应对象Re-ID的具备混合存储的自定进度对比学习
注:限于作者水平,本笔记难免存在不妥之处,欢迎批评指正
Abstract
域自适应目标Re-ID致力于将从有标签源域中学习到的知识转移到无标签目标域中以解决开放类行人重识别问题。
现有的最新基于伪标签方法因为域间差异以及不能令人满意的聚类效果,不能充分利用所有有价值的信息。
本文针对这些问题提出了一个新颖的拥有混合存储的自定进度对比学习框架。
混合存储动态生成source-domain class-level、target-domain cluster-level和un-clustered instance-level的有监督信号以学习特征表述。
不同于常规对比学习,本文框架联合辨别source-domain classes、 target-domain clusters和un-clustered instances。
提出的自定进度方法逐渐产生更多值得信赖的聚类以精炼混合存储和学习目标,这正是本文框架出色表现的关键。
本文方法在多个目标Re-ID域自适应任务优于state-of-arts,甚至在无额外注释源域情况下表现更佳。
本文模型在Market-1501和DukeMTMC-reID benchmarks分别优于最新算法16.2%和14.6%。
1.Instruction
现有的UDA方法使用以下两个阶段的训练模式:
(1)有监督预训练源域
(2)无监督微调目标域
基于伪标签的方法通过聚类目标域实例生成伪类以及用生成的伪类训练网络。通过这种方式,源域预训练过的网络能够适应在拥有伪类标签噪声的目标域中去捕获类内样本关联。
基于伪标签方法的两点限制:
(1)在目标域微调时,由于方法设计的限制源域图片要么不被考虑,要么对最终结果不利。
精确的源域真实标签是有价值的,但在目标域训练时被忽略。
(2)因为聚类过程可能会导致个体异常值,为确保生成伪标签的可依赖性,现有的方法简单地抛弃这些异常值,不在训练阶段使用。
这些异常值在目标域中可能实际上是困难但有价值的样本,简单地抛弃它们可能会严重地损害最终结果。

为解决以上问题,本文提出一个hybrid memory从源域和目标域中编码所有可利用的信息来学习特征。
对于源域数据,其真实类标签可以自然地提供有价值的监督。
对于目标域数据,实施聚类可以获得相对可靠的聚类和非聚类异常值。
来自hybrid memory的所有源域centroids、目标域聚类centroids以及非聚类实例特征能够跨两域为联合学习判别特征表述提供有监督信号。
开发一个统一的框架来动态更新和判别hybrid memory里不同的入口。
因为目标域聚类和非聚类实例被同等视为独立类别,聚类的可靠性将会极大地影响所学习的表述。
因此提出self-paced contrastive learning策略,通过使用拥有最多可靠目标域聚类的hybrid memory来初始化学习进程。
训练时有这些可靠的聚类,特征表述的判别能力逐渐提高,并且通过联合更多的非聚类实例进入新的聚类形成额外的可信赖聚类。
这样的策略可以高效地减缓噪声伪标签的影响,强化特征学习进程。
为正确衡量聚类可靠度,提出新颖的多尺度聚类可靠度标准,基于该标准只有可靠的聚类被保留,其他模糊不清的聚类被分解放回非聚类实例里。
通过这种方式,self-paced contrastive learning策略逐渐产生更多可靠聚类来动态地精炼hybrid memory和学习目标。
3.Methodology
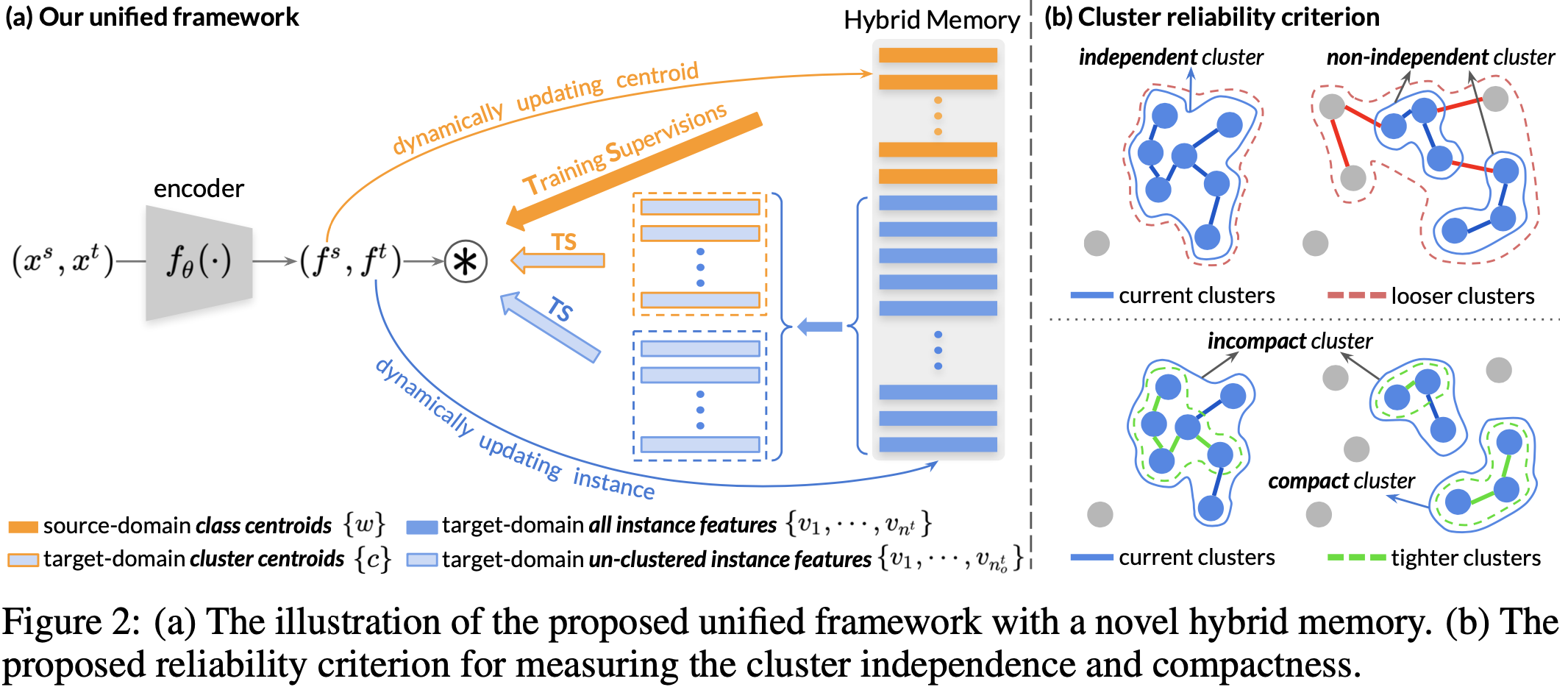
3.1为对比学习构建和更新hybrid memory
Xt是无标签目标域训练样本
Xs是有标签源域样本
Xtc是目标域有聚类伪标签数据
Xto是目标域无聚类实例
Xt=Xtc∪Xto
两域整个训练集为Xs∪Xtc∪Xto
最新UDA方法简单地抛弃了所有源域数据和目标域无聚类实例,只利用目标域伪标签使网络适应目标域。
本文设计一个新颖的对比损失通过将所有源域类、目标域聚类、目标域非聚类实例视为独立类来充分开发可利用数据。
3.1.1统一对比学习

3.1.2Hybrid Memory
hybrid memory提供源域类质心{w1, … , wns}、目标域聚类质心{c1, …, cntc}、目标域无聚类实例特征{v1, …, vnto}。
为持续存储和更新以上三个类型的入口,提出同时在hybrid memory里高速缓存源域类质心{w1, … , wns}和所有目标域实例特征{v1, …, vnt}。
注意nt≠ntc+nto。
假定无聚类特征在{v}中的下标为{1, …, nto},而其他聚类特征在{v}中的下标为{nto+1, …, nt},{vnto+1, …, vnt}动态地形成聚类质心{c}而{v1, …, vnto}仍然为无聚类实例。
存储初始化
最初的源域类质心{w}由每个类别的平均特征向量获得,初始的目标域实例特征{v}直接由fθ编码得出。
目标域聚类质心{c}依据{v}的每个聚类的平均特征向量进行初始化。

存储更新


3.2具备可靠聚类的自定进度学习
聚类的独立性
由于密度的差异,使用聚类质心和外类样本间的距离衡量聚类独立性是不可靠的。
本文使用以下标准衡量聚类独立性:
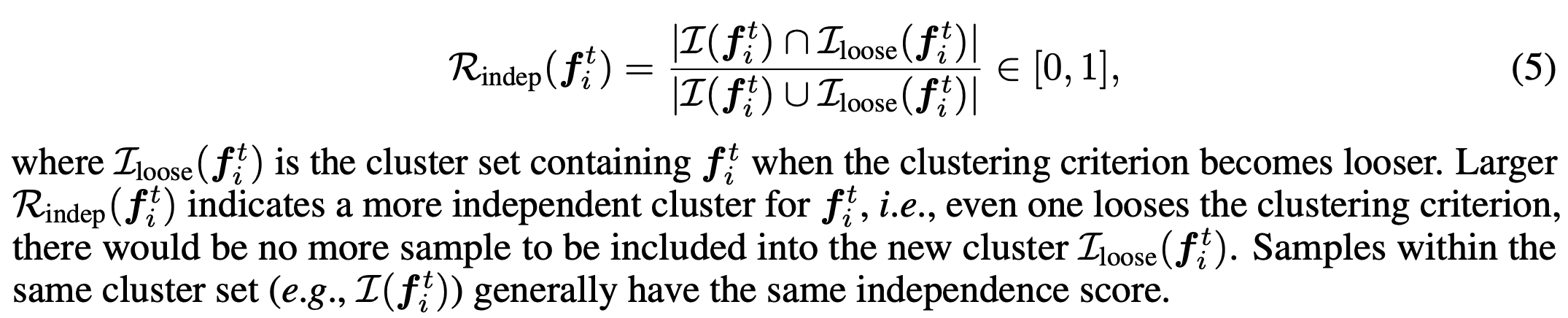
当放宽聚类标准,也不会有新的样本添加进去。
聚类的紧凑性

当聚类标准更为严格,聚类也不会被拆分为不同的聚类。
依据以上标准,设置α和β分别作为独立性和紧凑性的下限。
Rindep>α和Rcomp>β的具有紧凑数据点的独立聚类被保留,其余数据则被视为非聚类异常值实例。
随着编码器fθ和来自hybrid memory的目标域实例特征{v}的更新,产生更多的可信赖聚类以提升特征学习。
4.Experiments
4.2实施细节
使用ImageNet预训练的ResNet-50作为编码器fθ的骨干。
在每一epoch前使用DBSCAN做聚类,在DBSCAN中最重要的参数即两邻点最大距离在本文的自定进度学习策略中被微调为loosen和tighten聚类。
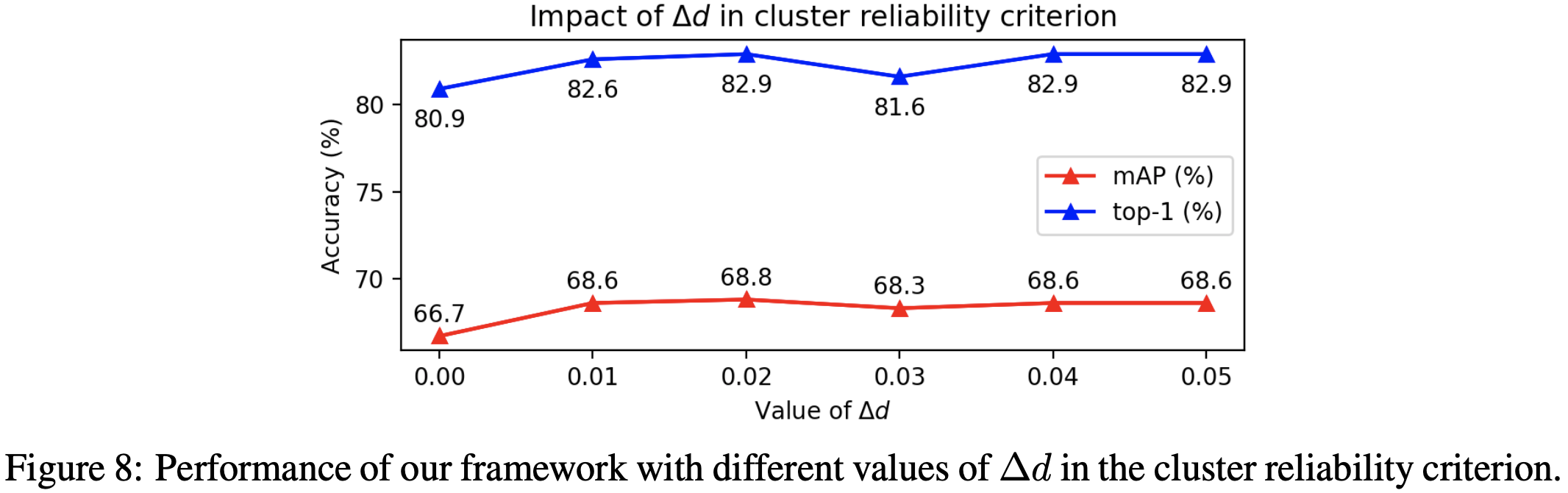
使用不变量下限α和动态下限β验证具有最紧凑点的独立聚类作为可依赖性标准。
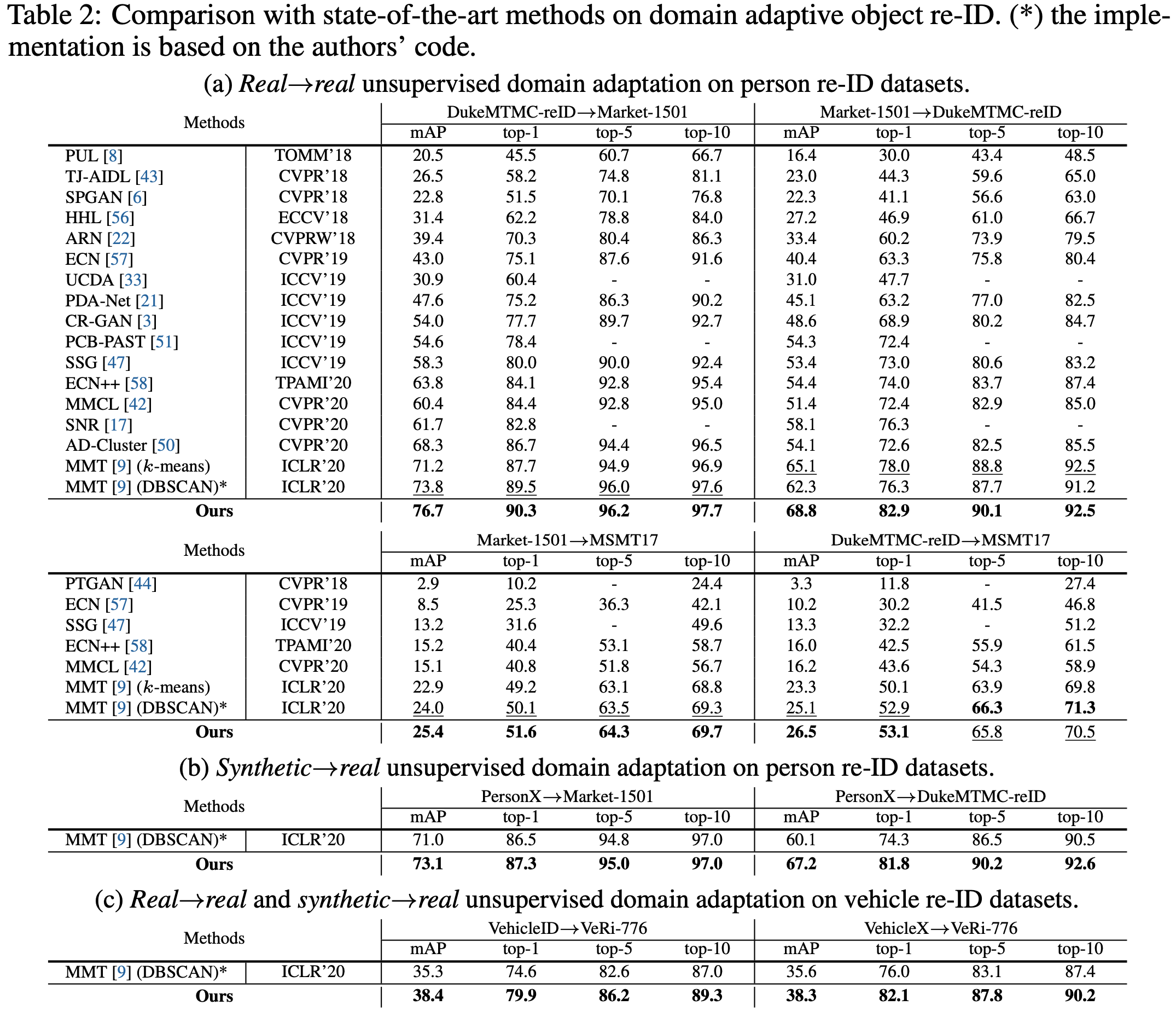
4.3与State-of-the-arts的比较
在目标域上的UDA表现
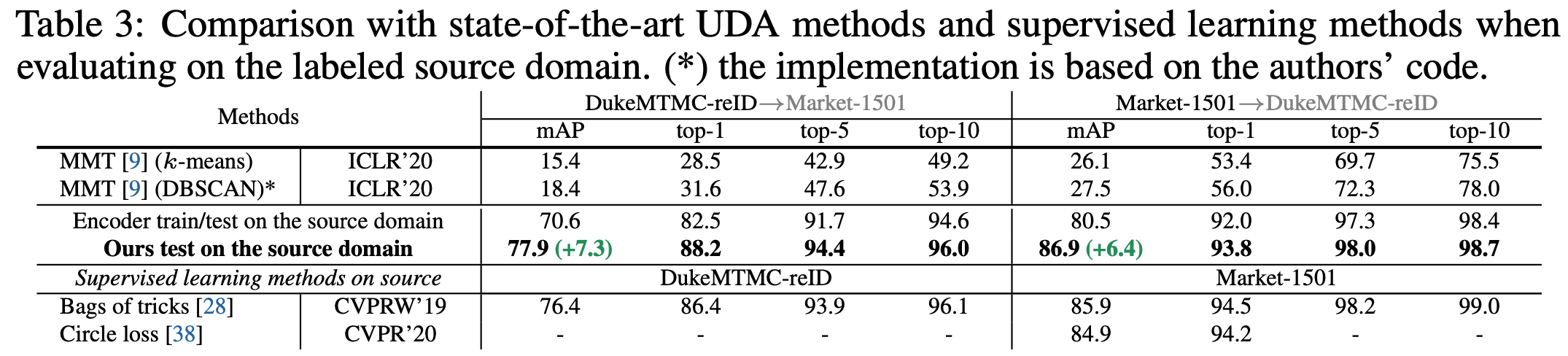
在源域上的进一步改善
无任何有标签训练数据的无监督Re-ID
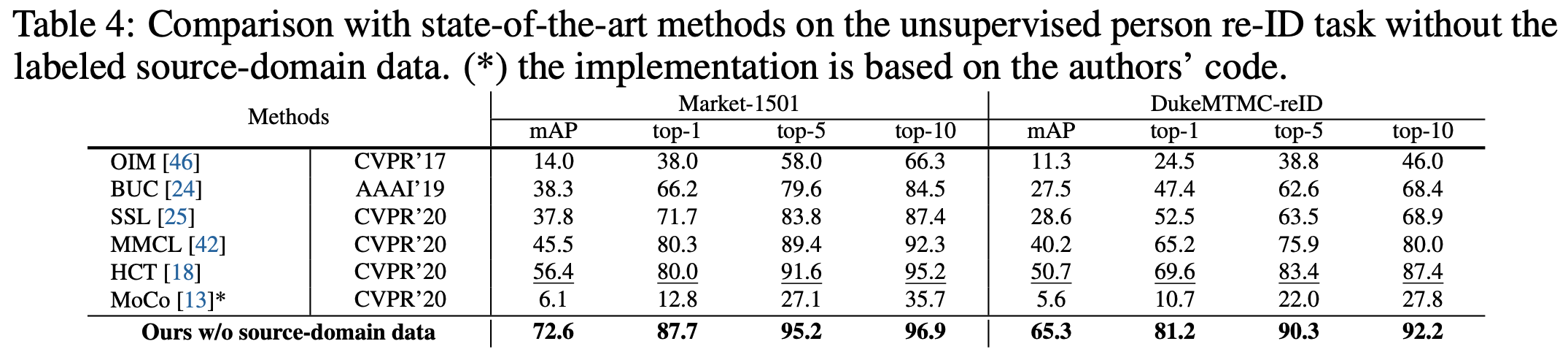
4.4Ablation Studies
本文采取无参数类质心来监督源域特征学习,但常规方法普遍采取一个可学习的分类器用于有监督学习。
因此Src.class→Src.learnable weights用来验证使用源域类质心进行训练来匹配目标域训练监督语义的重要性。
Oracle指的是目标域聚类完美即采用目标域真实标签情况的表现,用以验证本文模型的优越性。
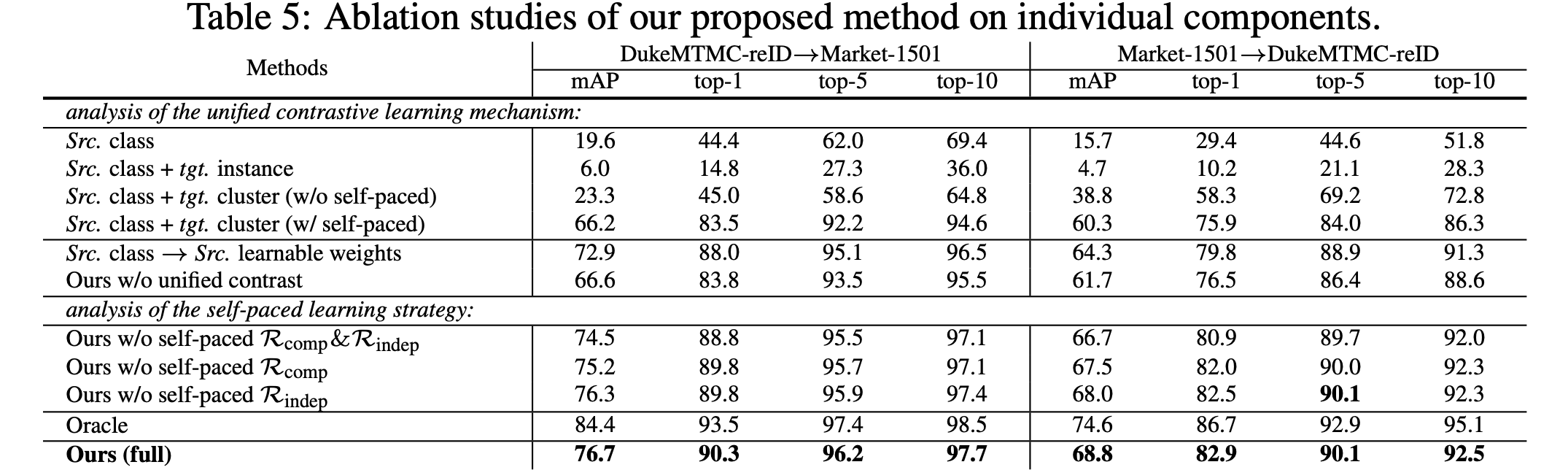
自定进度学习策略
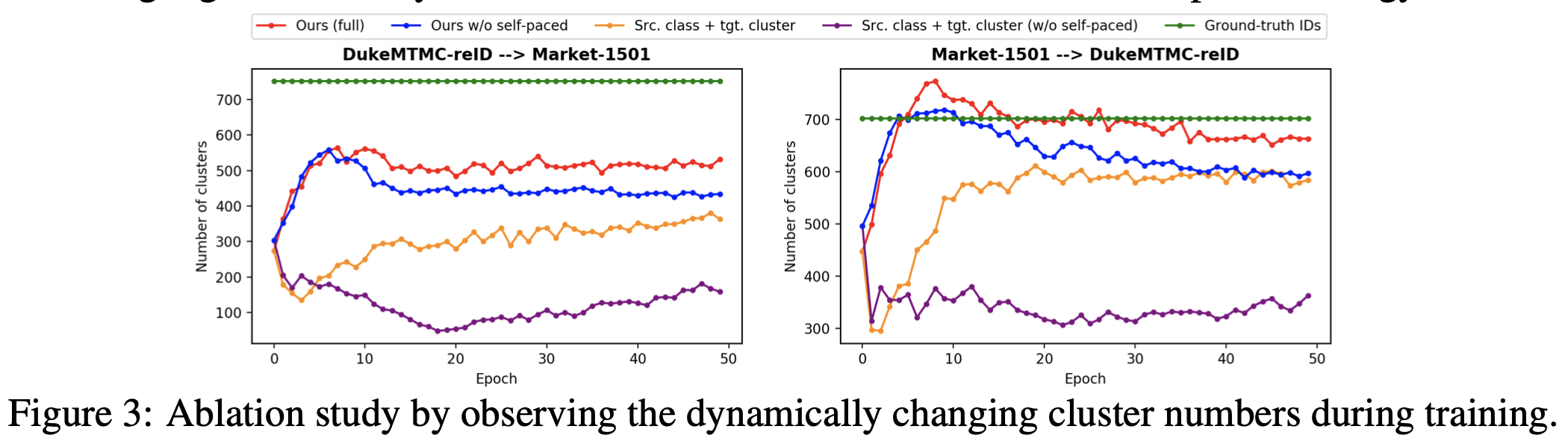
C.3目标域聚类

5.Discussion and Conclusion
前景:尽管实验结果非常优秀,距离Oracle还是存在一定差距,这表明即使拥有自定进度策略,得到的伪类标签可能还不够令人满意,还需进行进一步的研究加以完善。