行人重识别之cross domain
Instance-Guided Context Rendering for Cross-Domain Person Re-Identification (ICCV2019)
原文链接
最近写了很多cross domain的文章,打算用这篇文章来收尾。没想到这篇文章给我带来了十足的惊喜。文章基于GAN转换图像风格,效果非常好。如下图所示(忽略baseline),给定source和target的图像,就可以生成source的行人+target背景的新图像。也就是说,target中有多少种背景,一张source中的图像就可以生成多少张新的图像。这可以为模型的训练提供巨大的数据量。接下来,我们看一看这个效果是如何实现的。

模型的框架如下图所示:
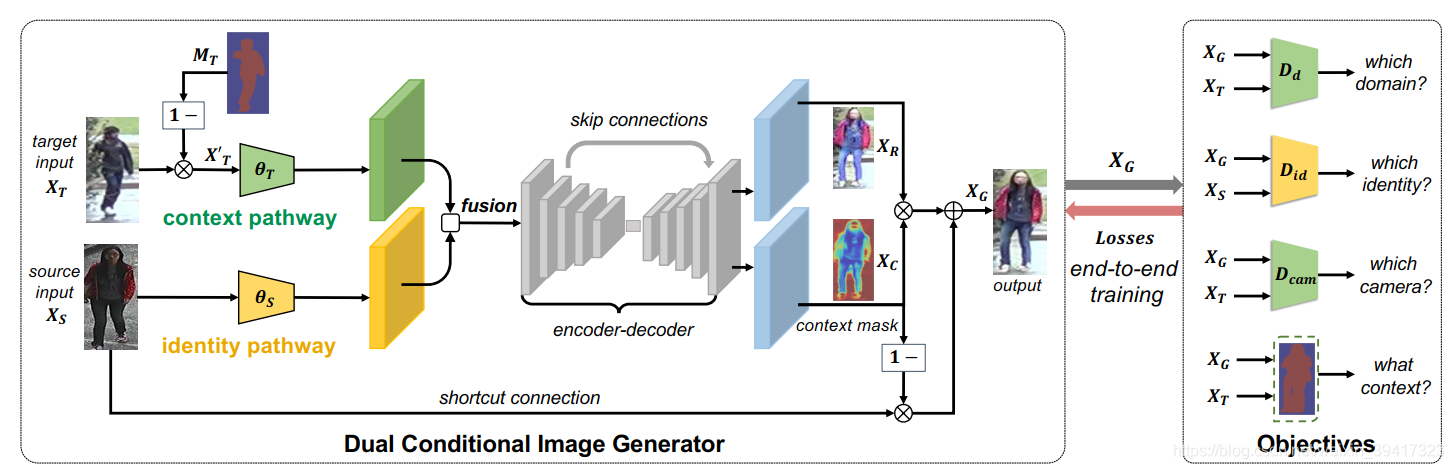
使用target图像的背景mask MT提取XT的背景,将其和Xs分别输入到绿色和黄色的网络中提取特征。进一步,将两者的特征进行融合并输入到U-net中(灰色部分)。最后生成了XR和Xc。直接使用XR作为生成的图像会丢失Xs中的信息,所以Xc作为混合XR和Xs的权重mask。如公式所示。
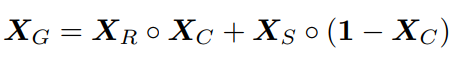
在网络训练拟合后,就可以输入任意的source和target图像生成和source身份相同和target背景相同的图像。用source加生成数据训练ResNet-50就获得了最终的测试模型。
接下来,说一下如何控制模型的训练。为了简单明了,引用文中的图片进行定性说明,如下图所示。

(a)判别器判断生成图像的真实性,注意,这个真实性是和XT比较。因为网络希望最终生成的图像风格和target相似。
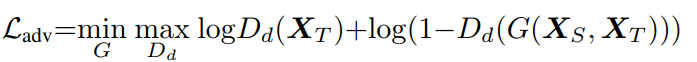
(b)提前训练一个轻量级网络识别摄像头角度,对生成图像的摄像头角度进行识别。其中yc是XT的摄像头角度。如下所示。

(c) 作者希望XG的前景和Xs相同,XG的背景和XT相同,如下所示。
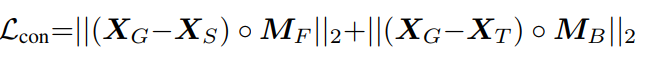
其中MF和MB分别为Xs的前景和背景mask。用前半部分说明,想计算XG的前景和Xs前景的差异,我们将两者相减,然后用MF过滤掉背景部分,最后就获得了前景相减的结果。
(d)这个最容易理解,约束XG和Xs的行人身份相同。
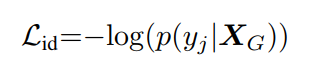
yj是Xs的身份标签。
总结:这篇文章不仅在图像合成上大有作为,而且作者启发我们,在cross domain问题中,图像生成方法和特征学习方法所做的努力是“正交”的,也就是说将两个途径的方法结合起来会有很好的效果。所以,从工程角度来说,也许百花齐放会带来意想不到的优秀效果。
完
欢迎讨论 欢迎吐槽
