版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/linwh8/article/details/78573634
刚刚看完这篇论文,整理了一下思路。这篇论文基于神经元在学习不同特征时活跃程度不同而提出DGD的方法,也是666的
论文:https://arxiv.org/abs/1604.07528
代码:https://github.com/Cysu/dgd_person_reid
论文解析
- 文章一开始,作者解释了为什么要使用多个数据集进行训练:
- Learning generic and robust feature representations with data from multiple domains for the same problem is of great value, especially for the problems that have multiple datasets but none of them are large enough to provide abundant data variations.
- 即当一个问题所对应的数据集中没有一个能够提供足够的信息时,可以考虑使用多个训练集进行训练,有点类似于“互补”。
- 包括一些背景的补充:
- In computer vision, a domain often refers to a dataset where samples follow the same underlying data distrubution.
- 一个域通常指一个数据集,该数据集中的样本符合某种数据分布。
- It’s common that multiple datasets with different data distributions are proposed to target the same or similar problems.
- 带有不同数据分布的数据集都是为了解决同一个或者相似的问题。
- Multiple-domain learning aims to solve the problem with datasets across different domains simultaneously by using all the data they provide.
- 多个域的学习问题就是利用多个数据集去解决某个问题。
- The success of deep learning is driven by the emergence of large-scale learning. Many studies have shown that fine-tuning a deep model pretrained on a large-scale dataset.
- 深度学习的发展是受到large-scale leaning的驱使。有很多研究都是使用一个大训练集对模型进行与训练,然后在使用特定的训练集对模型进行微调以得到最终的模型。
- However, in many specific areas, there is no such large-scale dataset for learning robust and generic feature representation.
- 然而,并不是在每个领域都会有大训练集可以用于学习具有鲁棒性的特征。所以很多研究团队提出了很多小训练集。
- 所以,作者认为:
- It is necessary to develop an effective algorithm that jointly utilize al of them to learn generic feature representation.
- 多域学习除了学习具有鲁棒性特征的方面以外,还有:
- Another interesting aspect of multi-domain learning is that it enriches the data variety because of the domain discrepancies.
- 域间的差异也是很重要的。
- Limited by various condtions, data collected by a research group might only include certain types of variations.
- Each of such datasets is biased and contains only a subset of possible data variations, which is not sufficient for learning generic feature representation. Combining them together can diversify the training data, thus makes the learned features more robust.
- 以上也是对为什么使用多个训练集进行训练的原因进行补充。
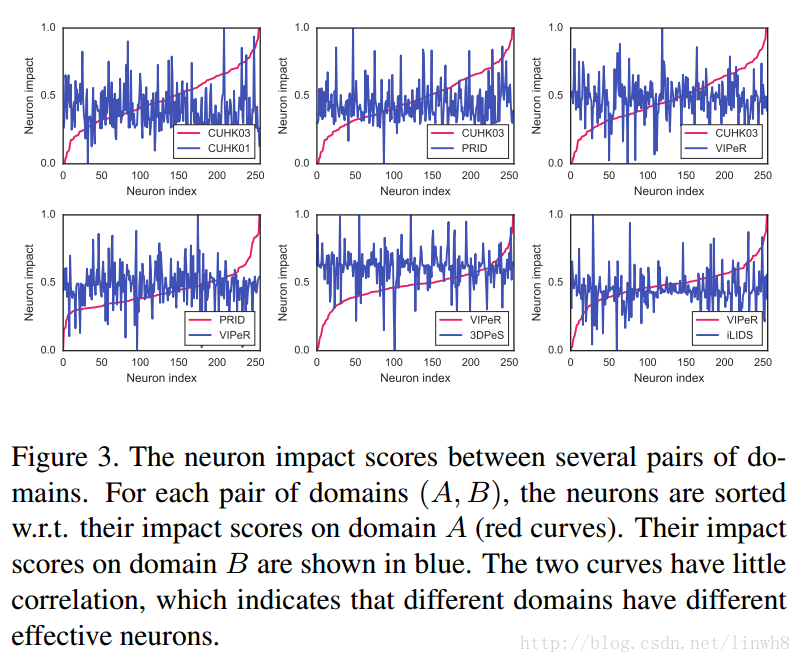
- 接着作者基于他们实验中观察到的现象:
- When training a CNN with data from all the domains, some neurons learn representations shared across several domains, while some others are effective only for a specific one.
- Neurons that are effective for one domain could be useless for another domain because of the presence domain biases.
- 意思就是说,他们发现在训练CNN的过程中,不同特征的学习,神经元的活跃程度是不一样的。举个例子,我把神经元简单的化成两个group(当然实际中不是这个样子,这里只是为了举例说明),对于特征A的学习,group1比较活跃,而group2比较低迷;但是对于特征B的学习,group2比较活跃,而group1比较低迷。
- 他们观察到这个现象的依据:
- 提出了他们的方法:
- Based on this important observation, we propose a Domain Guided Dropout algorithm to improve the feature learning procedure.
- Domain Guided Dropout — a simple yet effective method of muting non-related neurons for each domain.
- 不难想到,这个方法就是能在学习特征时抑制对该特征不活跃的神经元,并促进对该特征活跃神经元的工作,这样在一定程度上能减少训练的参数,以提高程序的性能
- Dropout is one of the most widely used regularzation method in training deeo neural networks, which significantly improves the performance of the deep model.
- Dropout就是一种正规化方法,可以用于提高深度学习模型的性能。
- 而且,这个方法与Standard Dropout是不一样的:
- Different from the standard Dropout, which treats all the neurous equally, our method assigns each neuron a specific dropouts rate for each domain according to its effectiveness on that domain.
- Standard Dropout对神经元是一视同仁的,而作者的方法是根据实际情况进行操作的。
- 作者的方法有两种模式:
- A deterministic scheme
- A stochastic scheme
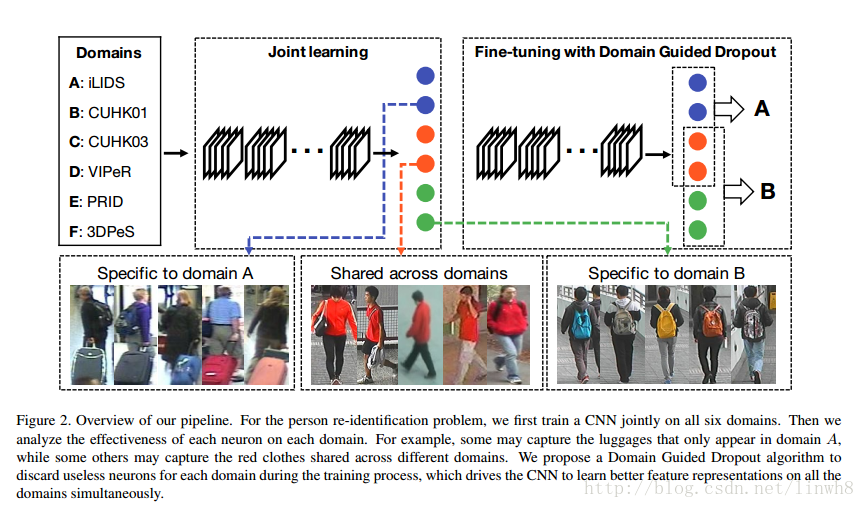
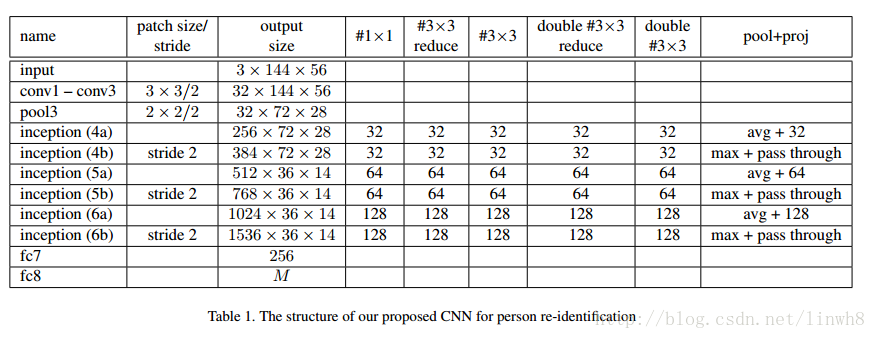
- 下面介绍一下他们整个方法的流程:
- We first mix the data and labels from all the domains together, and train a carefully designed CNN from scratch on the joint dataset with a single softmax loss.
- Our goal is to learn a generic feature extractor g(·) that has similar outputs for images of the same person and dissimilar outputs for different people.
- softmax loss:
- During the test phase, given a probe pedestrian image and a set of gallery images, we use g(·) to extract features from all of them, and rank the gallery images according to their Euclidean distances to the probe image in the feature space.
- 看到作者使用欧式距离,我第一反应是感到很困惑。一般来说,将欧式距离作为metric,并不能得到很好的结果,但作者在后面补充了使用欧式距离的原因:
- … and use the Euclidean distance directly as the metric, which stresses the quality of the learned features representation rather than metrics.
- 即作者使用欧式距离是为了强调学习到的特征的质量,而不是将它作为一种度量。
- 看到作者使用欧式距离,我第一反应是感到很困惑。一般来说,将欧式距离作为metric,并不能得到很好的结果,但作者在后面补充了使用欧式距离的原因:
- Next, for each domain, we perform the forward pass on all its samples and compute for each neuron its average impact on the objective function. Then we replace the standard Dropout layer with the proposed Domain Guided Dropout layer , and continue to train the CNN model for several more epochs.
- the impact of a particular neuron: the gain of the loss function when we remove the neuron
- With the guidance of which neurons being effective for each domain, the CNN learns more discriminative features for all of them.
- the impact of a particular neuron: the gain of the loss function when we remove the neuron
- At last, if we want to obtain feature representations for a specific domain, the CNN could be further fine-tuned on it, again with the Domain Guided Dropout to improve the performance.
- 注意,以上的第二、第三步骤分别使用的是Domain Guided Dropout的两个模式:deterministic scheme、stochastic scheme。
- After the baseline model is trained jointly with datasets of all the domains, we replace the standard Dropout with the deterministic Domain Guided Dropout and resume the training for several epochs.
- 接着使用Domain Guided Dropout的deterministic scheme进行再次训练
- We further fine-tune the net with stochastic Domain Guided Dropout on each domain separately to obtain the best possible results.
- 最后再使用Domain Guided Dropout的stochastic scheme进行训练微调。
- 对于Domain的Guidence,不同模式采取的方式是不一样的
- 对于deterministic模式:
- 当神经元的impact score > 0时,使该神经元active;
- 当神经元的impact score <=0时,使该神经元inactive。
- 对于stochasic模式:
- 根据impact score与Temperature T计算该神经元活跃的概率
- T controls how significantly the score s would affect the probabilities.
- 也就是说T决定了impact score对p的影响大小
- 对于deterministic模式:
- We first mix the data and labels from all the domains together, and train a carefully designed CNN from scratch on the joint dataset with a single softmax loss.
- 实验部分:
- 首先介绍了各个数据集的特点
- 接着与state-of-the-art method进行了对比
- 检验DGD的有效性
最后作者做了总结。
再谈一下,作者认为他们的贡献在于三个方面:
- First, we present a pipeline for learning generic feature representations from multiple domains that perform well on all of them.
- Second, we propose Domain Guided Dropouy to discard useless neurons for each domain, which improves the performance of the CNN.
- At last, our method outperforms state-of-arts on multiple person reidentification datasets by large margins.
- 以上便是对该论文的解析
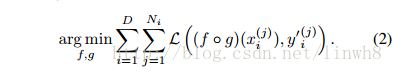
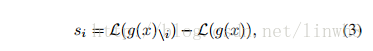
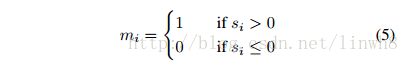
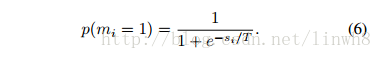
以上内容皆为本人观点,欢迎大家提出批评和指导,我们一起探讨!