https://github.com/lwplw/re-id_mgn
本文的主要思想就是通过区域分割,来获得不同粒度的特征,比如全局和局部特征以及更细粒度的局部特征,通过一个网络的不同分支得到这些特征,每个分支都对不同的分割块进行特征提取。
论文提出通过融合行人的全局信息以及具有辨识力的多粒度局部信息的思路,为解决ReID问题提供了一个非常不错的思路。
(1)结构精巧:该方案实现了端到端的直接学习,并没有增加额外的训练流程;
(2)多粒度:融合了行人的整体信息与有区分度的多粒度细节信息;
(3)关注细节:模型真正懂得什么是人,模型会把注意力放在膝盖,衣服商标等能够显著区分行人的一些核心信息上。
论文:https://arxiv.org/pdf/1804.01438.pdf
GitHub:https://github.com/seathiefwang/MGN-pytorch
ABSTRACT
全局和部分特征的组合已经成为改善行人重识别(Re-ID)任务中的判别性能的基本解决方案。以前基于部分的方法主要侧重于定位具有特定预定义语义的区域以学习局部表示,这增加了学习难度,但对于具有大差异的场景不具有效率或鲁棒性。在本文中,我们提出了一种将判别信息与各种粒度相结合的端到端特征学习策略。我们精心设计了多粒度网络(MGN),这是一种多分支深度网络架构,包括一个用于全局特征表示的分支和两个用于局部特征表示的分支。我们不是学习语义区域,而是将图像统一划分为多个条带,并改变不同本地分支中的部分数量,以获得具有多个粒度的局部特征表示。在包括Market-1501,DukeMTMC-reid和CUHK03在内的主流评估数据集上做的综合实验表明,我们的方法已经稳健地实现了最先进的性能,并且大大优于任何现有方法。例如,在Market-1501数据集上,单张图片检索模式下,在re-rank后获得了Rank-1 / mAP = 96.6%/ 94.2%的结果。
1. INTRODUCTION
行人重识别是在不同安全摄像头捕获的所有行人图像中检索给定人物的挑战性任务。由于监控视频图像的场景复杂性,行人重识别的主要挑战来自人的较大变化,如姿势、遮挡、衣服、背景杂乱、检测失败等。深度卷积网络的蓬勃发展,对行人图像的识别和鲁棒性提出了更为强大的表现形式,将Re-ID的性能提升到了一个新的水平。最近几个月,一些深层次的Re-ID方法在高识别率和平均精度方面取得了突破。
行人表示的直观方法是从图像中提取全身的辨别特征。 全局特征学习的目的是捕获所有不同的人之间最显著的信息,例如:衣服的颜色,代表行人的身份。然而,在监控场景中捕获的图像的高复杂性通常限制了大规模Re-ID场景中的特征学习的准确性。 对于行人Re-ID训练数据集的有限规模和弱多样性,一些非显著或不常见的细密信息很容易被忽略,并且在全局特征学习过程中对更好的区分没有贡献,这使得全局特征难以适应类似的具有共同属性或大的内部差异的条件。
为了缓解这种困境,已经发现从图像中定位重要的身体部位来表示身份的局部信息是在许多以前的工作中更好地行人重识别的有效方法。每个定位的身体部位区域仅包含来自全身的一小部分局部信息,同时通过定位操作实际上过滤了区域外的其他相关或不相关信息,通过定位操作可以学习局部特征以集中更多关于身份并用作全局特征的重要补充。行人重识别基于局部的方法可以根据其局部定位方法分为三个主要途径:
1)定位具有强结构信息的部分区域,例如关于人体的经验知识或基于强学习的姿势估计;
2)使用区域建议region proposal方法定位部分区域;
3)通过中层注意突出部分middle-level attention on salient parts来增强特征。
但是,明显的局限性阻碍了这些方法的有效性。首先,姿势或遮挡变化会影响局部表示的可靠性。其次,这些方法几乎只关注具有固定语义的特定部分,但不能涵盖所有的判别部分。最后但同样重要的是,大多数这些方法都不是端到端的学习过程,这增加了学习的难度。

在本文中,我们提出了一种结合不同粒度的全局和局部信息的特征学习策略。如图1所示,从左到右是人体部分从粗粒度到精细粒度的过程。不同数量的分区条带引入了多种粒度:我们定义的Global Branch只包含一个整体分区,其中全局信息是最粗略的情况。随着分区数量的增加,局部部分的特征可以更集中于每个部分条带中更精细的判别信息,并在其它条带上过滤信息。由于深度学习机制可以从整个图像中捕获对主体的近似关注,因此还可以捕获从不同部分区域提取的局部特征的更集中的显着性偏好。基于这个想法,我们设计了多粒度网络(MGN),这是一个多分支网络架构,分为一个全局和两个局部分支,其中包含来自ResNet-50[13]网络骨干的第四个残差阶段的精细参数。在MGN的每个局部分支中,我们将全局合并的特征映射划分为不同数量的条带作为部分区域,以独立地学习局部特征表示,参考[36]中的方法。
与以往的基于部分的方法相比,我们的方法仅使用等分的部分进行局部表示,但性能优于以往所有方法。此外,我们的方法是完全端到端的学习过程,易于学习和实施。大量实验结果表明,而即使在没有额外的外部数据或re-ranking[50]操作的情况下,我们的方法可以在几个主流的Re-ID数据集上实现最先进的性能。
结合全局与局部特征是提高提取行人关键可分辨信息的重要方法。之前的局部特征提取的方法专注在基于位置的显著信息提取,导致训练难度提高,同时在复杂场景的鲁棒性并不尽如人意。而作者新设计了一个多分支的端到端的深度网络,使得不同级别的网络分支能够关注不同粒度的分辨信息,也能够有效兼顾整体信息。损失函数部分,作者表示为了充分体现网络的真实潜力,该文章中只使用了在深度学习中非常常见的Softmax Loss与Triplet Loss。
2. RELATED WORKS
随着深层学习的蓬勃发展,利用深层网络进行特征学习已经成为person Re-ID任务的一种普遍做法。[20]首先将深度孪生网络架构(deep siamese network)引入Re-ID中,结合人体部位特征学习,实现了比现代手动设计的方法更高的性能。[47]提出ID-discriminative Embedding (IDE)与简单的ResNet-50骨干作为现代深度Re-ID系统性能水平的基线。在[1,37]中,计算图像对的中级特征(mid-level features of image pairs),以便用精心设计的机制描述局部部分的相互关系。 [39]引入了Domain Guided Dropout,以提高不同行人场景领域的泛化能力。[50]将重新排序策略re-ranking引入Re-ID任务中,以改近排名结果以提高精度。
结合了多通道的全局和局部特征,并学习了具有改进的triplet loss函数的判别式表示。 [24,25,38,43,19,22]利用嵌入内的注意信息来改善对身体局部部分的代表性区分。 [42,32]使用人体地标的结构信息来获得准确的语义局部区域建议(region proposals)。
近几个月来,相比以前的系统,一些deep Re-ID方法将性能提高到了一个新的水平。[40]在训练阶段引入基于部分的校准匹配,利用最短路径规划及相互学习,提高度量学习性能。[3,34]将输入图像的特征映射等分为垂直方向的多条条纹。[3]将部分特征切片与LSTM网络进行融合,并结合分类度量学习得到的全局特征。相反,[34]直接连接局部部分的特征作为最终表示,并应用改良的部件池化来修改部分特征的映射验证。然而,根据[40]的观点,这些系统只是达到了与人类相似的性能。
3. MULTIPLE GRANULARITY NETWORK
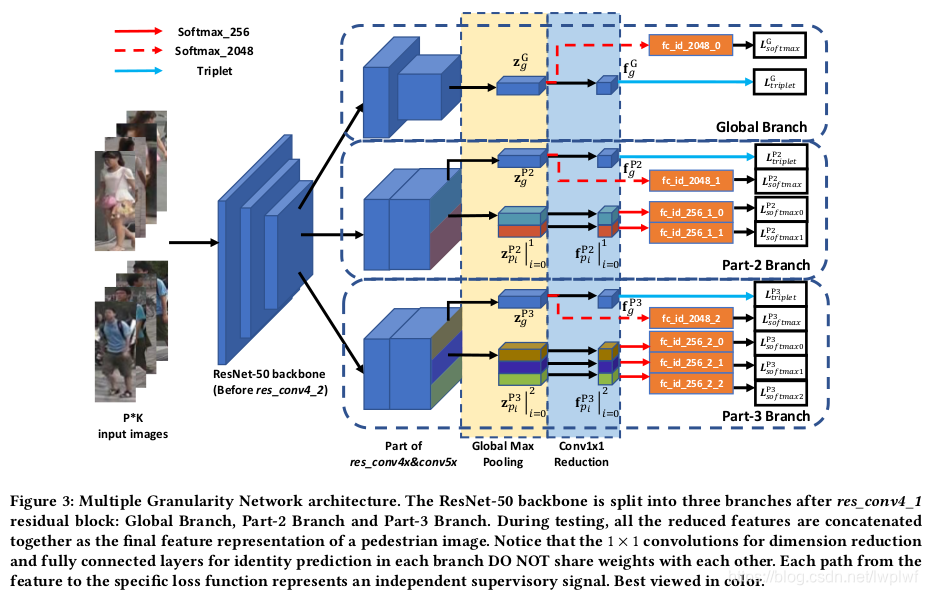
图2显示了从IDE baseline model[47]和基于IDE的part-based model中提取的特定图像的特征响应图。我们可以观察到,即使没有施加明确的注意机制来增强对某些显著成分的偏好,深层网络仍然可以根据其内在的语义意义来学习不同身体部位的反应偏好的初步区别。然而,为了消除复杂度高的行人图像中不相关模式的干扰,较高的响应仅仅集中在行人三元组的主体上,而不是任何具有语义模式的具体身体部位。当我们缩小表示区域的面积并将其作为分类任务来训练以学习局部特征时,我们可以观察到局部特征图上的响应开始聚集到一些显著的语义模式上,这些语义模式也随着表示区域的大小而变化。
该观察结果反映了图像内容的体积,即区域的粒度,以及深度网络关注于表示的特定模式的能力之间的关系。我们认为,这一现象来自限制区域信息的限制。一般来说,与全局图像相比,从局部区域识别行人的身份是非常困难的。分类任务的监督信号迫使特征被正确地分类为目标身份,这也促使了学习过程在有限的信息中探索有用的细粒度细节。
实际上,在以往基于局部特征的学习方法中,无论是否具有经验先验知识,都为整个特征学习过程引入了划分的基本粒度多样性。假设存在适当的粒度级别,具有最多区别信息的细节可能几乎集中在深层网络上。基于以上观测和分析的启发,我们提出多粒度网络(MGN)体系结构,将全局和多粒度局部特征学习结合起来,以实现更强大的行人表示。
3.1. Network Architecture
图3是多粒度网络的结构,基础网络部分为ResNet-50。作者对ResNet-50进行了修改,使用ResNet-50前三层提取图像的基础特征,将res_conv4_1之后的后续部分划分为3个独立的分支,即在高层次的语义级特征作者设计了3个独立分支。
如图所示,第一个分支负责整张图片的全局信息提取,第二个分支会将图片分为上下两个部分提取中粒度的语意信息,第三个分支会将图片分为上中下三个部分提取更细粒度的信息。这三个分支既有合作又有分工,前三个低层权重共享,后面的高级层权重独立,这样就能够像人类认知事物的原理一样即可以看到行人的整体信息与又可以兼顾到多粒度的局部信息。

表1列出了这些分支的设置。在上分支中,我们在res_conv5_1块中采用stride=2的卷积层进行下采样,在对应的输出特征图上执行global max-pooling (GMP) [2]操作,并使用有batch normalization的1×1卷积 [17]和ReLU将2048维的特征减少到256维。该分支在没有任何分区信息的情况下学习全局特征表示,因此我们将此分支命名为全局分支Global Branch。
中间和下级分支都与Global Branch共享类似的网络架构。但在res_conv5_1块中没有再使用下采样操作,并且每个分支中的输出特征图在水平方向被均匀地分割成若干条带,在其上独立的执行global max-pooling操作去学习局部特征表示。我们称这些分支为Part-N分支,其中N表示未导出的特征映射上的分区数量,例如,图3中的中下分支可以命名为Part-2和Part-3分支。
在测试时,将256维的所有特征串联作为最终特征,无需使用2048维的特征,使用欧氏距离作为两个行人相似度的度量。
三个分支最后一层特征都会进行一次全局MaxPooling操作global max-pooling(GMP),然后再将特征由2048维降为256维。最后256维特征同时用于Softmax Loss与Triplet Loss计算。另外,作者在2048维的地方添加一个额外的全局Softmax Loss,该任务将帮助网络更全面学习图片全局特征。
3.2. Loss Functions
softmax loss
batch-hard triplet loss – original semi-hard triplet loss的改进版
对于基本的辨别学习,作者认为识别任务是一个多类别的分类问题。对于第i个学习特征fi,softmax loss被表述为:
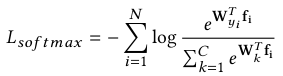
其中:
Wk -- k类的权重向量;
N -- mini-batch;
C -- 训练集中的类数。
与传统的softmax loss不同,作者根据[38],放弃了线性多级分类器中的偏差项,这有助于提高识别性能。
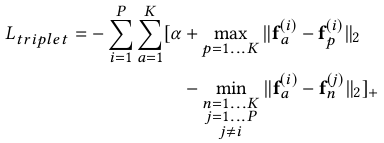
其中:
fa、fp、fn -- 分别是从anchor、positive、negative样本中拿到的特征;
α -- 边距margin超参数,用于控制内部和内部距离的差异。
候选三元组由最不像的正样本和最像的负样本对构建,即具有P个行人每个人K张图片的mini-batch中最难的正负样本对。这种改进的triplet loss增强了度量学习的稳健性,同时进一步提高了性能。
在MGN架构中,为了避免损失权重调整问题和收敛困难,将softmax loss应用在降维之前的2048维特征(LG/softmax、LP2/sotfmax、LP3/softmax),以及应用在Part-2和Part-3分支降维之后的256维局部特征(LP2/softmax0、LP2/softmax1和LP3/softmax0、LP3/softmax1、LP3/softmax2)。对所有分支降维成256之后(非局部),也计算batch-hard triplet loss(LG/triplet、LP2/triplet、LP3/triplet)。
此外,不会在局部特征上使用triplet loss。 由于不对齐或其他问题,局部特征的内容可能会发生巨大变化,这使得triplet loss往往会在训练期间破坏模型。
3.3. Discussions
在我们提出的多粒度网络架构中,有一些问题值得我们单独讨论。 在本段中,我们具体讨论了以下问题:
根据我们对多分支架构的最初动机,在一个分支中同时学习全局和局部表示似乎是合理的。该方法可以直接对res_conv5_3提取的同一最终特征图进行不同条数的分割,并应用相应的监督信号。然而,我们发现这种设置对于进一步的性能改进不是有效的。借用[34]中的思想,原因可能是共享相似网络体系结构的分支(主要是ResNet-50的第四个剩余阶段)仅仅响应关于图像的不同级别的详细信息。多个粒度的混合单分支的学习特性可能会削弱详细信息的重要性。此外,我们尝试在较浅或更深的层次上分割骨干网络,也没有达到更好的性能。
粒度的多样性在我们的网络体系结构中的三个分支实际上学习用不同的偏好来表示信息。具有较大接收区域和全局最大池化的全局分支捕捉来自行人图像的整体但粗略的特征,并且Part-2和Part-3分支学习的特征没有跨步卷积和条纹分割的部分趋向于局部但很精细。具有更多分区的分支将学习行人图像更精细的表示。学习不同偏好的分支可以协作地向公共骨干部分补充低级别的区分信息,这是在任何单个分支中性能提升的原因。
4. EXPERIMENT
4.1. Implementation
4.2. Datasets and Protocols
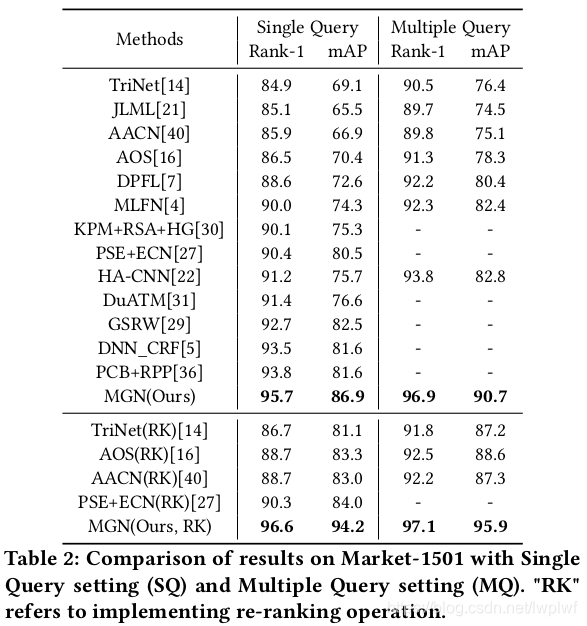
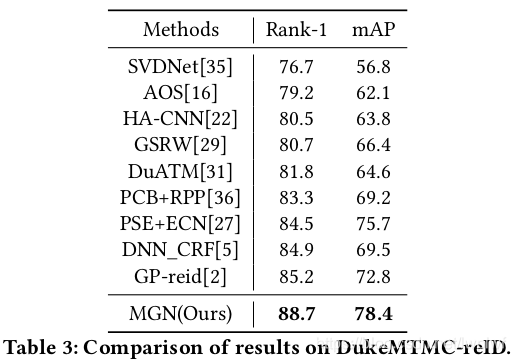
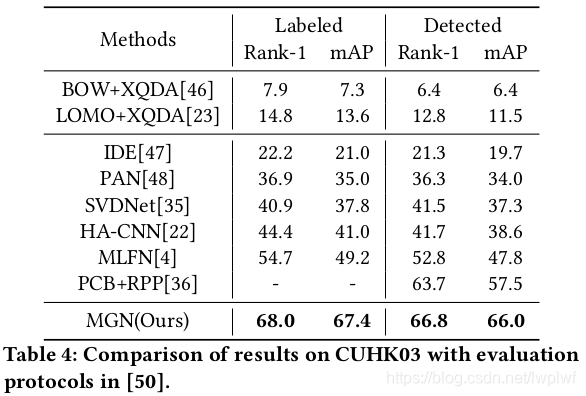
4.3. Comparison with State-of-the-Art Methods
4.4. Effectiveness of Components
5. CONCLUSION
在本文中,我们提出了多粒度网络(MGN),这是一种新颖的多分支深度网络,用于学习行人重识别任务中的判别表示。 MGN中的每个分支都用特定的粒度分区来学习全局或局部表示。该方法直接在水平分割的特征条上学习局部特征,是完全端到端的,并且不引入区域建议或姿势估计等局部定位操作。大量实验表明,我们的方法不仅可以在几个主流行人重识别数据集上获得了最先进的结果,而且与现有方法相比,还可以将性能提升到一个优异的水平。
Reference:
https://blog.csdn.net/gavinmiaoc/article/details/80648754
https://blog.csdn.net/Gavinmiaoc/article/details/80840193
https://zhuanlan.zhihu.com/p/35296881