行人重识别之局部识别(CVPR2019)
Perceive Where to Focus: Learning Visibility-aware Part-level Features
for Partial Person Re-identification
原文链接:https://arxiv.org/abs/1904.00537
这篇文章的核心思想是:
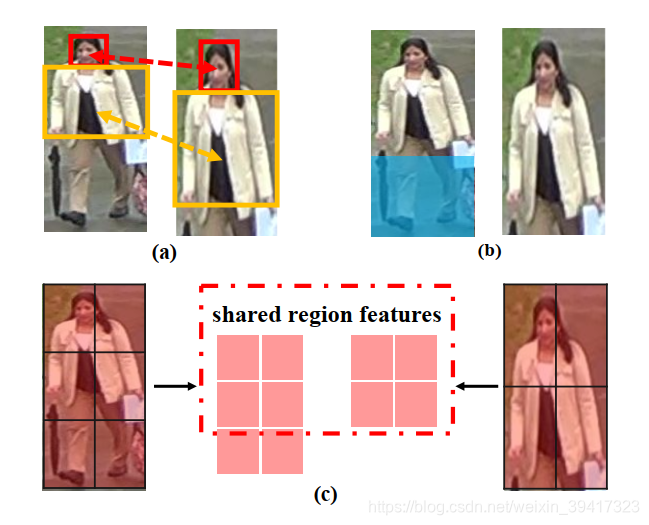
如下图(a),两幅图的空间位置失配。如图(b),左侧图片多出来的腿部,不能有助于识别,甚至成为了信息干扰。所以,如©所示,与左边的完整图片相对应,作者希望能够让模型自动识别出右侧残缺图片包含的部分,然后仅利用包含的部分,进行识别。接下来,对实施过程进行介绍。
总体框架:
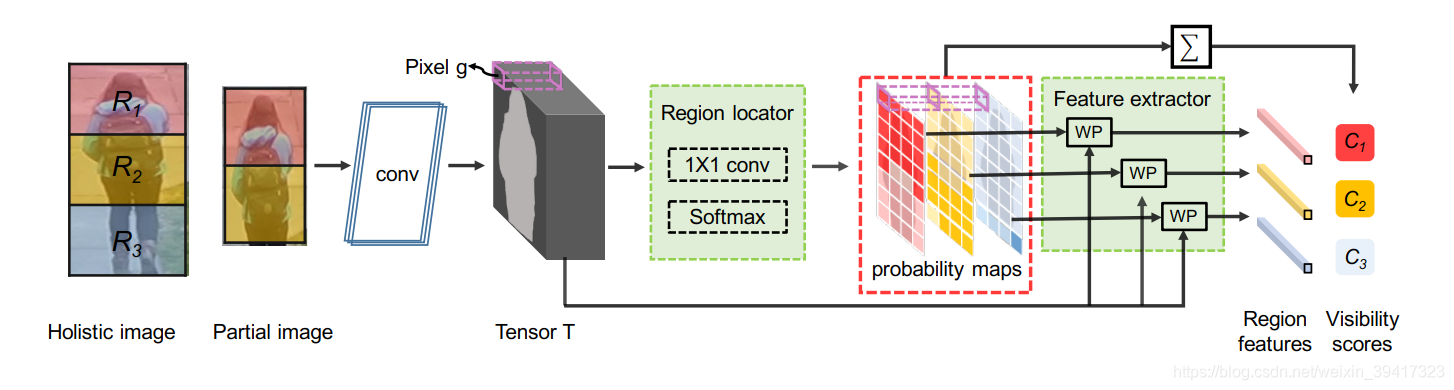
如上图(假设把完整图片分为了三部分,实际中可以设置为任意部分,好比第一幅图中的六部分),通过卷积层获得特征向量T,再经过1x1卷积和softmax分类器,获得三张(与三部分对应)概率map。相当于对T中的每一个像素进行预测,属于哪一个部分。利用T和map加权计算,得到每一个部分获得的特征向量。将每一张map求和,获得分数C,C越大就代表残缺图片含有这个部分的概率越大。
如何训练?
将对应的完整图片提前设计好分为几个部分。这样特征向量T中的每一个像素g就可以赋予标签(属于哪一个部分),从而进行训练。
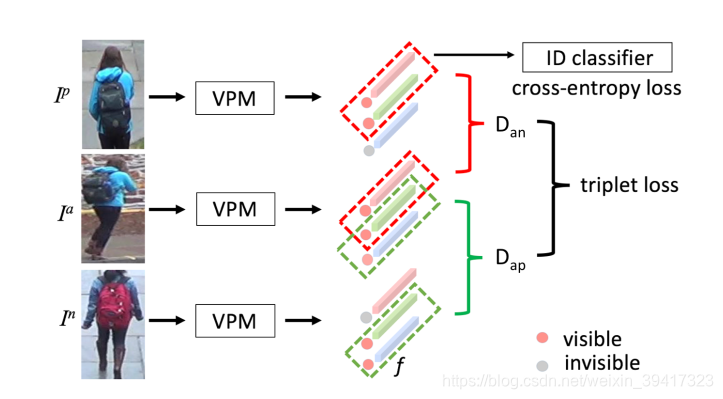
总共有三个损失函数:每一个像素的分类损失(交叉熵)、使用每一个部分的特征向量单独预测人物身份的分类损失(交叉熵)、triplet loss。
如下图所示,只使用残缺图片中包含的部分对应的特征向量计算第二个和第三个损失函数。
如何分类?
用以下公式计算图片k和图片l的距离:
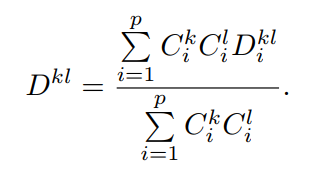
Ci是包含第i部分的概率,Di是两个图片第i部分的距离。可以看出来,只要有一张图片不含有第i部分(Ci很小),那么Di对于距离的贡献就非常小了,这样便实现了这篇文章的核心思想。
最后用可视化结果进行直观感受:
上面八张图是模型的分割结果,可以看出,有三张图有缺失的时候,模型只分割了四个部分。图片完整时,就可以进行六部分的分割了。
总结:作者赋予了模型观察力,去发现图片是否有缺失,从而在一定程度上解决空间失配和图片不完整的问题。局部行人重识别是一个较新的课题,利用残缺图片识别,增加了难度,有较大研究空间。两个专门做局部行人重识别的数据库:Partial-REID和Partial-iLIDS。
完
欢迎讨论 欢迎吐槽
