Abstract
人眼可以通过一些小的显著区域识别人的身份。然而,当利用现有方法计算图像的相似性时,通常这种有价值的显著信息被隐藏。此外,许多现有方法以有监督的方式学习辨别特征并处理剧烈的视点变化,并且需要为不同的一对摄像机视图标记新的训练数据。在本文中,我们提出了一种基于无监督显著性学习的行人重识别的新视角。在训练过程中不需要身份标签就可以提取出独特的特征。首先,我们应用邻接约束补丁匹配来构建图像对之间的密集响应,这显示了处理由大视点和姿势变化引起的错位的有效性。其次,我们以无监督的方式学习行人的显著性。为了提高行人重新识别的性能,将行人显著性纳入块匹配中以找到可靠且有区别的匹配块。我们方法的有效性在广泛使用的VIPeR数据集和ETHZ数据集上得到验证。
1. Introduction
行人重识别处理非重叠相机视图中的行人匹配和排序。 它在视频监控中具有许多重要的应用,通过节省大量人力来从大量视频序列中彻底搜索行人。 但是,这也是一项非常具有挑战性的任务。 监视摄像机可以在一天内观察公共区域内的数百名行人,其中一些行人具有相似的外观。 在不同摄像机视图中观察到的同一个人经常在视点,姿势,摄像机设置,光照,遮挡和背景方面经历显著变化,这通常使个人内变化甚至比人际变化更大,如图1所示。

图1.人类图像匹配和显著性区域示例。 垂直黑色虚线左侧的图像来自摄像机视图A,右侧的图像来自摄像机视图B.图的上部显示了基于密集响应和加权的显著性值的匹配示例,下部用他们的显著图显示一些图像对。
我们的工作主要体现在三个方面。 大多数现有作品[25,15,8,29,16,24]通过采用监督模型来处理交叉视图变化的问题并提取判别特征,监督模型需要具有身份标签的训练数据。 此外,由于交叉视图变换对于不同的摄像机视图对是不同的,因此大多数需要在摄像机设置改变时标记新的训练数据。 这在许多应用中是不切实际的,特别是对于大规模相机网络。 在本文中,我们提出了一种通过无监督学习方法来学习对行人进行判别和可靠描述的。 因此,它对一般摄像机视图设置具有更好的适应性。
行人重识别中,视点改变和姿势变化导致图像之间不受控制的错对准。例如,在图1中,图像的中心区域(a1)是摄像机视图A中的背包,而它在相机视图B中成为图像(b1)的手臂。因此不能直接比较空间错位的特征向量。 在我们的方法中,应用块匹配来解决错位问题。 另外,基于对行人结构的先验知识,在块匹配中添加了一些约束以增强匹配准确性。 通过块匹配,我们可以在图1中的黑色虚线框中对齐女士手提包上的蓝色倾斜条纹。
行人图像中的显著区域提供有价值的识别信息。但是,如果它们的尺寸很小,则在计算图像的相似性时通常会隐藏显著性信息。在本文中,显著性意味着明显的特征:1)在使人从同伴中脱颖而出时具有辨别力; 2)在不同视图中找到相同的人是可靠的。例如,在图1中,如果数据集中的大多数人穿着类似的衣服和裤子,则很难识别它们。然而,人眼很容易识别匹配对,因为它们具有不同的特征,例如,人(a1 - b1)有一个带有倾斜蓝色条纹的背包,人(a2 - b2)手臂下有一个红色文件夹,而人(a3 - b3)手上有一个红色的瓶子。这些不同的特征在区分方面具有辨别力一个来自其他人,并且在不同的摄像机视图中匹配自己。直观地,如果身体部位在一个摄像机视图中显著,则在另一个摄像机视图中通常也是显著的。此外,我们对显著性的计算是基于与来自大规模参考数据集而非一小部分人的图像的比较。因此,在大多数情况下它非常稳定。然而,现有方法可以将这些不同的特征视为要移除的异常值,因为它们中的一些(例如行李或文件夹)不属于身体部位。衣服和裤子通常被认为是人们重新识别的最重要区域。在块匹配的帮助下,本文采用这些有辨别力和可靠的特征进行行人重识别。
本文的贡献可归纳为三方面。首先,提出了一种无监督框架,用于提取行人重识别的独特特征,而无需在训练过程中手动标记行人身份。其次,块匹配与邻接约束一起用于处理由视点改变,姿势变化和清晰度引起的未对准问题。我们表明,受约束的块匹配极大地提高了行人重识别的准确性,因为它在处理大视点变化时具有灵活性。第三,人类的显著性是以无监督的方式学习的。与一般图像显著性检测方法[4]不同,我们的突出性特别针对行人匹配而设计,具有以下特性:1)它对视点变化,姿势变化和清晰度很强; 2)只有在两个摄像机视图中匹配且不同时,才会将不同的补丁视为突出的补丁;3)人类显着性本身是行人匹配的有用描述。例如,仅具有显著上半身的人和仅具有显著下半身的人必须具有不同的身份。
2. Related Work

像SVM和boosting[25,13,15]这样的判别模型被广泛用于特征学习。 Prosser等人[25]将行人重识别作为排序问题,并使用整合的RankSVM来学习成对相似性。Gray等人[13]通过boosting来结合当地特征的空间和颜色信息。Schwartz等人[26]提取包括颜色,梯度和纹理的高维特征,然后利用偏最小二乘(PLS)进行降维。另一个方向是使用度量学习算法[29,8,24,16]学习特定任务的距离函数。 Li和Wang [17]将两个摄像机视图的图像空间划分为不同的配置,并为不同的局部对齐的共同特征空间学习了不同的度量。Li等人[18]提出了一个转移的度量学习框架,用于学习各个查询候选设置的特定度量。在所有这些监督方法中,需要具有身份标签的训练样本。
一些无监督的方法也被开发用于行人重识别[10,21,22,19]。 Farenzena等人[10]提出了对称驱动的局部特征累积(SDALF)。 他们利用行人图像中的对称性,获得了良好的视角不变性。Ma 等人[21]开发了BiCov描述符,它结合了Gabor滤波器和协方差描述符来处理光照变化和背景变化。 Malocal等人[22]采用Fisher Vector编码局部特征的高阶统计量。 所有这些方法都集中在特征设计上,但数据集中样本分布的丰富信息尚未得到充分利用。我们的方法利用了人物图像之间的显著性信息,可以推广使用这些特征。
几种处理姿势变化的方法[27,11,1,7]被开发。 Wang等人[27]提出了形状和外观上下文来模拟外观相对于身体部位的空间分布,以便提取对未对准有力的辨别特征。 Gheissari等人[11]拟合三角形视图模型。 Bak等人[1]和Cheng等人[7]采用基于部件的模型来处理姿势变化。但是,这些方法不够灵活,只有在姿势估计器准确工作时才适用。 我们的方法与它们的不同之处在于,采用补丁匹配来处理空间错位。
来自周围人的语境视觉知识被用来丰富人类的鲜明特征[28]。 刘等人 [19]使用基于属性的加权方案,它与我们在寻找独特和固有的外观属性方面具有相似的原理。 他们以无监督的方式对原型进行聚类,并学习了基于属性的特征加权功能。 他们的方法基于全局特征。 他们加权了不同类型的特征而不是本地补丁。 因此,它们无法获得显著区域,如图1所示。实验结果表明,我们定义的显著性更有效。
3. Dense Correspondence
密集的相关性已应用于人脸和场景对齐[23,20]。 继承了基于部分和基于区域的方法的特征,细粒度方法(包括像素级中的光流,关键点特征匹配和局部补丁匹配)通常是更稳健对齐的更好选择。 在我们的方法中,考虑到远场监控摄像头捕获的行人图像的中等分辨率,我们采用中级局部补丁进行匹配。 为了确保匹配的稳健性,在每个图像中对局部补丁进行密集采样。 与一般的补丁匹配方法不同,对搜索匹配的补丁强加了简单但有效的水平约束,这使得补丁匹配在行人重识别时更具适应性。
3.1. Feature Extraction
Dense Color Histogram. 每个行人图像被密集地分割成局部块的网格。 从每个块中提取LAB颜色直方图。 为了稳健地捕获颜色信息,还在下采样的尺度上计算LAB颜色直方图。 为了与其他特征组合,所有直方图都是L2标准化的。
Dense SIFT. 为了处理视点和光照变化,SIFT描述符用作颜色直方图的补充特征。 与提取密集颜色直方图的设置相同,在每个人类图像上采样密集的块网格。 我们将每个块分成4×4个单元,将局部梯度的方向量化为8个区间,并获得4×4×8 = 128维的SIFT特征。 筛功能也是L2标准化。
密集颜色直方图和密集SIFT特征被连接为每个块的最终多维描述符向量。 在我们的实验中,特征提取的参数如下:在具有网格步长4的密集网格上对大小为10×10像素的块进行采样; 分别在L,A,B信道中计算32个bin颜色直方图,并且在每个信道中,使用3个下采样级别,其中缩放因子为0.5,0.75和1; SIFT特征也在3个颜色通道中提取,因此为每个块生成128×3特征向量。 总之,每个块最终由具有长度32×3×3 + 128×3 = 672的判别描述符向量表示。我们将组合的特征向量表示为dColorSIFT。
3.2. Adjacency Constrained Search
为了处理错位,我们进行邻接约束搜索。行人图像中的dColorSIFT特征表示为
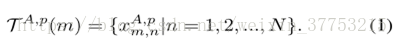
在中所有的块和来自于摄像头B的图像q有相同的搜索集S:
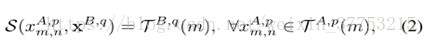
其中,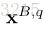
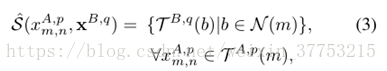
其中,

Adjacency Searching. 广义块匹配是计算机视觉中非常成熟的技术。 许多现成的方法[2,3]可用于提高性能和效率。 在这项工作中,我们只是对在参考集中的每个图像的搜索集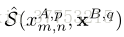
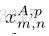
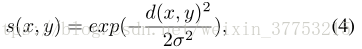
其中,

图2.邻接搜索的示例。 (a)来自VIPeR数据集的测试图像。 密集采样局部块,不同身体部位的五个样本块用红色框显示。(b)每个参考图像的一个最近邻通过邻接搜索返回左边的每个块,然后N个最近邻从N张参考图像已排序。 显示了前十个最近邻块。 请注意,十个最近邻居来自十个不同的图像。
4. Unsupervised Salience Learning
通过密集的对应,我们用无监督的方法学习行人的显著性。 在本文中,我们提出了两种学习人类显著性性的方法:K-最近邻(KNN)和one-class SVM(OCSVM)。
4.1. K-Nearest Neighbor Salience
Byers等人[5]发现KNN距离可用于去除簇。 为了将KNN距离应用于行人重识别,我们在密集对应的输出集中搜索测试块的K最近邻。 通过这种策略,显著性更适合于重新识别问题。 遵循异常检测和显著性检测的共同目标,我们在我们的任务中重新定义了显著的块,如下所示:
Salience for person re-identification: salient patches are those possess uniqueness property among a specific set.
行人重识别的显著性:显著的块是特定集合中具有独特性的那些。
用Nr表示参考集中的图像数量。在测试图像和参考集中的图像之间建立密集对应之后,为每个测试块返回参考集的每个图像中最相似的块,即,每个测试块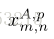
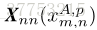

其中,
我们在[5]中将类似的方案应用于每个测试块
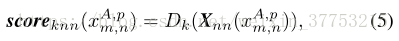
其中,Dk表示第k个近邻的距离。如果参考集的分布很好地解决了测试场景,那么显著的块只能找到视觉上相似的近邻的有限数量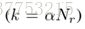
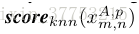

图3 .显著块分布的图示。显著的块分布在远离其他块的地方。
Choosing the Value of k. 行人重识别的显著性检测的目标是识别具有独特外观的人。 我们假设如果一个人具有这种独特的外表,那么参考集中超过一半的人与他/她不同。通过这个假设,在我们的实验中使用k = N r / 2。为了寻求更有原则的方法来计算行人显著性,在4.2节讨论了one-class SVM显著性。
为了与复杂的监督学习方法进行定性比较,图4(a)显示了由偏最小二乘法(PLS)估计的特征加权图[26]。 PLS用于降低维度,第一投影矢量的权重显示为每个块中特征权重的平均值。 我们的无监督KNN显著性的结果显示在ETHZ数据集的图4(b)和VIPeR数据集的4(c)上。 突出分数被分配到块的中心,并且显著图被上采样以便更好地可视化。 我们的无监督学习方法更好地捕获了显著区域。

图4.显著性的定性比较。(a)显示了通过偏最小二乘估计的特征加权图[26]。(b)显示我们的KNN显著性估计。红色表示大权重。
4.2. One-class SVM Salience
one-class SVM [14]已被广泛用于异常值检测。 在训练中仅使用正样本。 one-class SVM的基本思想是使用超球面来描述特征空间中的数据,并将大部分数据放入超球面。 该问题被定义为一个目标函数如下:
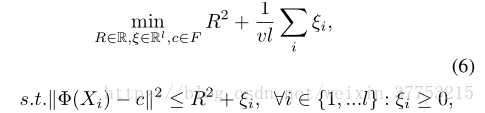
其中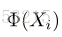

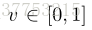
其中
其中,d是块特征之间的欧式距离。
我们的实验显示了两种显著性检测方法在行人重识别中的非常相似的结果。在某些情况下,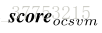
5. Matching for re-identification
第3节和第4节中描述的密集对应和显著性用于行人重识别。
5.1. Bi-directional Weighted Matching
设计双向加权匹配机制以将显著性信息结合到密集对应匹配中。 首先,我们考虑一对图像之间的匹配。 如4.1节所述,在搜索范围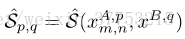

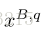
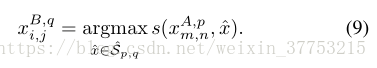
然后,在集合中搜索最佳匹配的图像可以形式化为寻找最大相似性得分。
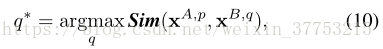
其中,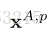
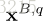

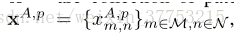

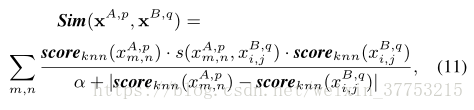
其中,α是控制显著性差异惩罚的一个参数。还可以在更原则的框架中更改显著性得分以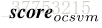
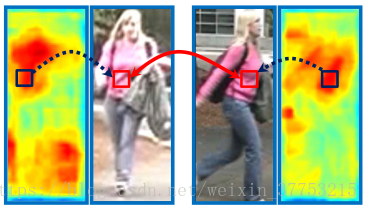
图5. 块匹配的双向加权的例证。 红色方框中的色块与深蓝色方框中的块在相应显著性分数的指导密集对应。
5.2. Combination with existing approaches
我们的方法是对现有方法的补充。为了将现有方法的相似性得分与等式(11)中的相似性得分相结合,两图像之间的距离可以计算如下:
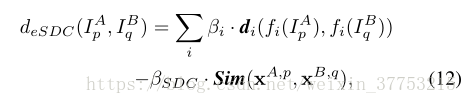
其中,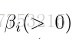
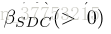

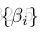

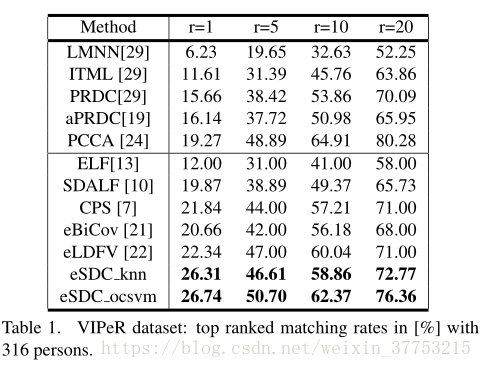
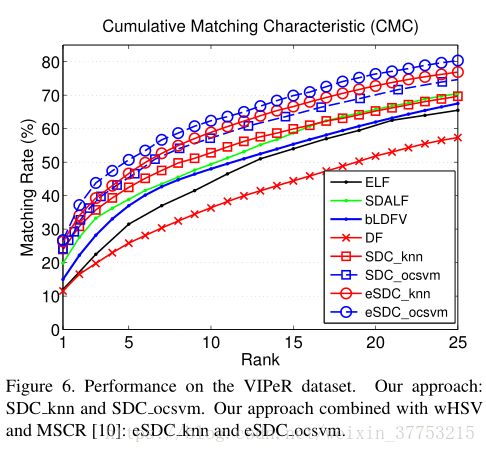
6. Experiments
References
[1] S. Bak, E. Corvee, F. Brémond, M. Thonnat, et al. Person
re-identification using spatial covariance regions of human
body parts. In AVSS, 2010.
[2] C. Barnes, E. Shechtman, A. Finkelstein, and D. Goldman.
Patchmatch: a randomized correspondence algorithm for
structural image editing. TOG, 2009.
[3] C. Barnes, E. Shechtman, D. Goldman, and A. Finkelstein.
The generalized patchmatch correspondence algorithm. In
ECCV, 2010.
[4] A. Borji and L. Itti. Exploiting local and global patch rarities
for saliency detection. In CVPR, 2012.
[5] S. Byers and A. Raftery. Nearest-neighbor clutter removal
for estimating features in spatial point processes. Journal of
the American Statistical Association, 1998.
[6] Y. Chen, X. Zhou, and T. Huang. One-class svm for learning
in image retrieval. In ICIP, 2001.
[7] D. Cheng, M. Cristani, M. Stoppa, L. Bazzani, and
V. Murino. Custom pictorial structures for re-identification.
In BMVC, 2011.
[8] M. Dikmen, E. Akbas, T. Huang, and N. Ahuja. Pedestrian
recognition with a learned metric. ACCV, 2011.
[9] A. Ess, B. Leibe, and L. Van Gool. Depth and appearance
for mobile scene analysis. In ICCV, 2007.
[10] M. Farenzena, L. Bazzani, A. Perina, V. Murino, and
M. Cristani. Person re-identification by symmetry-driven ac-
cumulation of local features. In CVPR, 2010.
[11] N. Gheissari, T. Sebastian, and R. Hartley. Person reidentifi-
cation using spatiotemporal appearance. In CVPR, 2006.
[12] D. Gray, S. Brennan, and H. Tao. Evaluating appearance
models for recognition, reacquisition, and tracking. In PETS,
2007.
[13] D. Gray and H. Tao. Viewpoint invariant pedestrian recogni-
tion with an ensemble of localized features. ECCV, 2008.
[14] K. Heller, K. Svore, A. Keromytis, and S. Stolfo. One class
support vector machines for detecting anomalous windows
registryaccesses. InWorkshoponDataMiningforComputer
Security (DMSEC), 2003.
[15] M. Hirzer, C. Beleznai, P. Roth, and H. Bischof. Person
re-identification by descriptive and discriminative classifica-
tion. Image Analysis, 2011.
[16] M. Hirzer, P. Roth, M. Köstinger, and H. Bischof. Relaxed
pairwise learned metric for person re-identification. ECCV,
2012.
[17] W. Li and X. Wang. Locally aligned feature transforms
across views. In CVPR, 2013.
[18] W. Li, R. Zhao, and X. Wang. Human reidentification with
transferred metric learning. In ACCV, 2012.
[19] C. Liu, S. Gong, C. Loy, and X. Lin. Person re-identification:
What features are important? In ECCV, 2012.
[20] C. Liu, J. Yuen, and A. Torralba. Sift flow: Dense correspon-
dence across scenes and its applications. TPAMI, 2011.
[21] B. Ma, Y. Su, and F. Jurie. Bicov: a novel image representa-
tion for person re-identification and face verification. 2012.
[22] B. Ma, Y. Su, and F. Jurie. Local descriptors encoded by
fisher vectors for person re-identification. 2012.
[23] K. Ma and J. Ben-Arie. Vector array based multi-view face
detection with compound exemplars. In CVPR, 2012.
[24] A. Mignon and F. Jurie. Pcca: A new approach for distance
learning from sparse pairwise constraints. In CVPR, 2012.
[25] B. Prosser, W. Zheng, S. Gong, T. Xiang, and Q. Mary. Per-
son re-identification by support vector ranking. In BMVC,
2010.
[26] W. Schwartz and L. Davis. Learning discriminative
appearance-based models using partial least squares. In XXII
BrazilianSymposiumonComputerGraphicsandImagePro-
cessing (SIBGRAPI), 2009.
[27] X. Wang, G. Doretto, T. Sebastian, J. Rittscher, and P. Tu.
Shape and appearance context modeling. In ICCV, 2007.
[28] W. Zheng, S. Gong, and T. Xiang. Associating groups of
people. In BMVC, 2009.
[29] W. Zheng, S. Gong, and T. Xiang. Person re-identification by
probabilistic relative distance comparison. In CVPR, 2011.