1、
文章的AACN=PPA+AFC
- 其中PPA用来产生part attention,用来去除背景干扰
AFC用来对特征进行对齐,用产生的attention来对齐特征
传统方法用part来辅助行人ReID,都是通过矩形框去框人体部位,这样会造成很大的误差,如果能学出一种attention自动关注到对应的身体部位效果会更好
2、
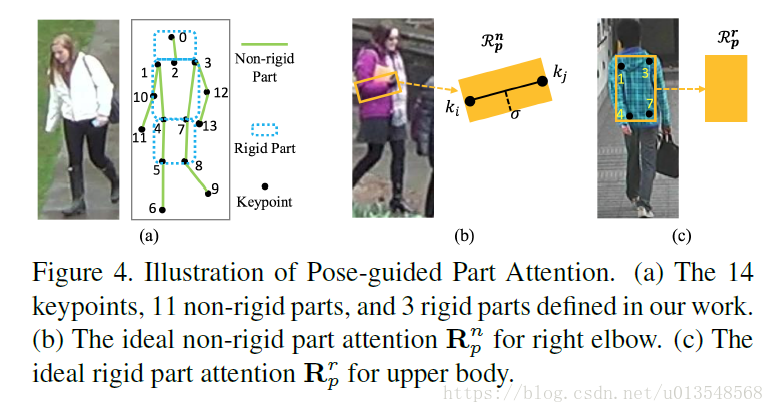
对于PPA部分,作者用了三个分支来学习总体的特征
- 第一个分支是关键点分支
- 第二个分支是non-rigid肢干分支,用PAF实现
- 第三个分支是rigid肢干分支,主要包括头-颈,肩膀-臀部,臀部-膝部
整体网络框架如下
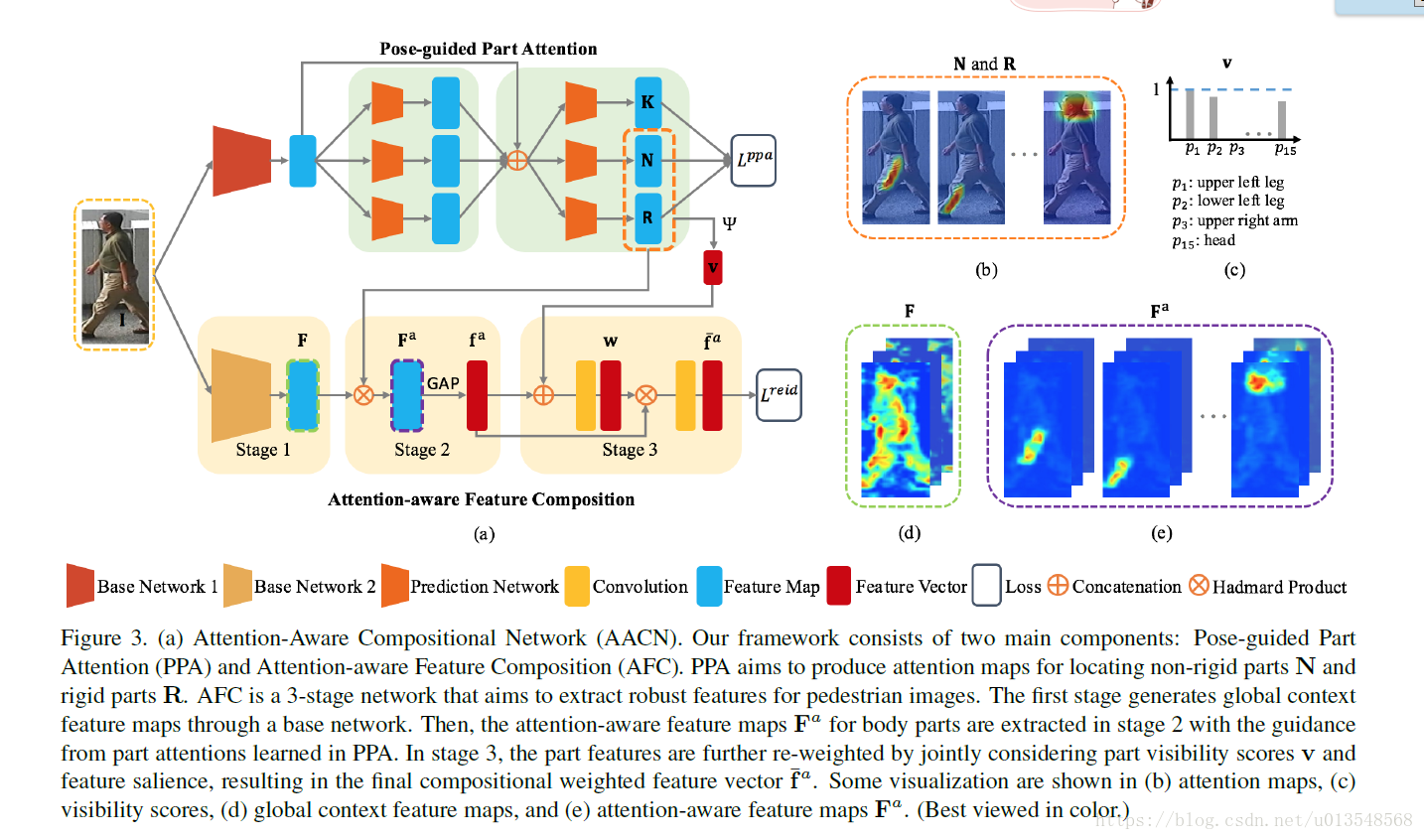
每一个分支选择一个损失,所以这里所有的attention都是显式学出来的,而不是隐式学习出来的
3、
学习出了整体的attention之后,讲这些attention应用到GCN的特征上,用来对GCN(Global Context Network)进行加权。GCN首先是Googlenet而来,在global average pooling 之后,加入identification loss和verification loss进行学习,取FCN的特征F,假设大小为F = 256xMxN
1)网络学出来的attention的每一张map都去乘F,假设第p张attention去乘F的话,产生
,大小还是256xMxN,然后经过global average pooling
产生
,大小为256x1x1,然后将p张attention处理的结果concat在一起形成
,大小为(Px256)x1x1,也即AFC的stage2
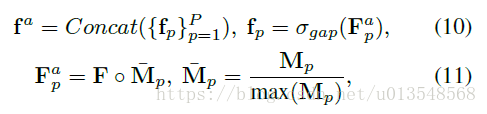
2) 然后将上面concat后的结果
和attention产生的分数concat,然后通过1x1的全连接层产生w权重,w一共有p个,然后将每个部位的权重乘到对应的
上去
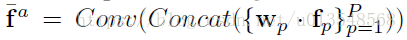
3)将最后的 的1024维向量用来做最后的ReID分类
4、训练策略
- 首先PPA用 pose loss进行训练
- GCN用ReID loss进行训练
- 然后将训练好的PPA和GCN应用在AFC的训练上
- 最后所有模块放在一起去训练