Hierarchical Discriminative Learning for Visible Thermal Person Re-Identification
目前的问题:
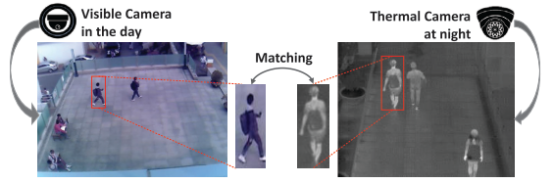
现有的交叉模态匹配方法主要侧重于对交叉模态分布的建模,而VT-REID也存在由于摄像机视角不同而导致的交叉视图变化。下图可以看到,除了对同一ID的跨模态问题外,对摄像机拍摄同一ID的视角变化也是当前ReID的一个难点。
本文提出了一个分层的跨模态匹配模型,该模型通过联合优化模态特异性和模态共享矩阵来实现。模式特异性度量将两种不同的模式转换成一个一致的空间,从而可以随后学习模式共享度量。与此同时,特定于模态的度量将同一个人的特征压缩到每个模态中,以处理较大的模态内人的变化(例如视点、姿势)。此外,提出了一种改进的两流CNN网络来学习多模态可共享特征表示。
网络框架及loss:
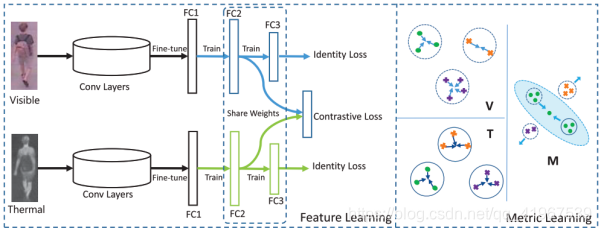
本文提出的框架包括特征学习和度量学习两个阶段。前者的目的是学习多模态可共享的特征表示,通过一个具有identity loss 和contrastive loss的two-stream CNN网络来实现。后者侧重于判别匹配模态训练,分别使用特定模态的(V, T)和共享模态的(M)度量学习。
1.Feature Learning:
首先,two-stream CNN Network中,backbone 采用AlexNet,分别学习两种模态各自的特征,经过fine-turn输出给3个FC层,并引入two identity losses 和 one contrastive loss 。
Identity Loss:该loss是指通过使用特定模态的信息来学习描述特征表征,从而在不同的模态中区分不同的人。用的是一个分类加交叉熵函数作为identity loss,L1 loss见下,L2 loss同理:
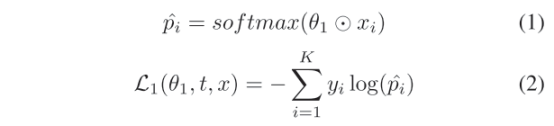
Contrastive Loss:该loss的作用是弥补两个不同模态之间的差距,同时也可以增强特征学习的模态不变性。其中,x,z分别为fc2的two-stream的输出,yn表示两个图像是否为同一人,是yn=1,不是yn=0,dn为x-z的2范数,代表了x与z之间的欧几里得距离,margin本文中去0.5,N为batch size。
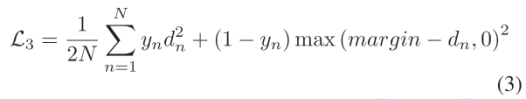
总共loss为:
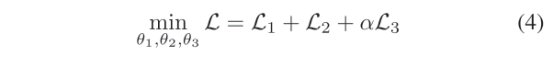
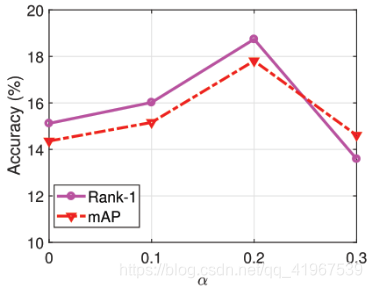
其中α为权重参数,具体取值如下:
2.Metric Learning:
Hierarchical Cross-modality Metric Learning (HCML):核心思想是将两个不同空间的模态的数据转化到同一个空间,为了更有效对特征的学习:
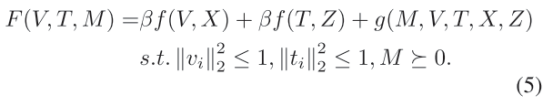
其中,V和T表示可见光图像和热成像图像的模态特异性变换矩阵,以处理模态内的变化,M表示学习到的处理交叉模态差异的模态共享度量。具体如下:
2.1Modality-specific Terms:
在特定模态域中,目的是在每种模态内分别约束同一人的特征向量。
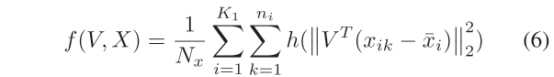
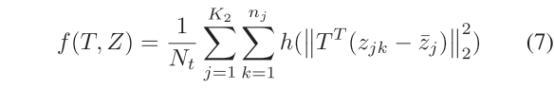
其中,和分别代表RGB和热图特征向量的均值,Nx和Nt表示每种模态中每个子图像的总数,ni (nj)是人i (j)在可见(热)模态下的每个子图像的数量,
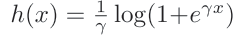 是generalized logistic loss,类似hinge loss:
是generalized logistic loss,类似hinge loss:
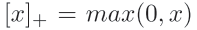
2.2Modality-shared Term:
目的是学习能够区分不同人的两种不同模态转换后与模态特异性的度量:
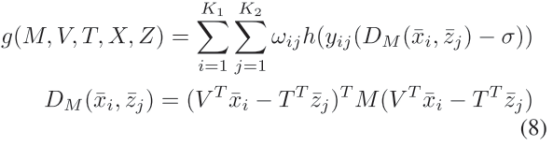
其中,yij=1表示i和j属于同一个人,且此时wij权重满足:
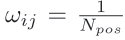 ,即正样本数量的倒数;
,即正样本数量的倒数;
反之,yij=-1,且此时wij权重满足:
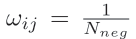 ,即负样本数量的倒数。
,即负样本数量的倒数。
实验:
数据集选用 RegDB ;
该模型中不同部分比较及消融实验:
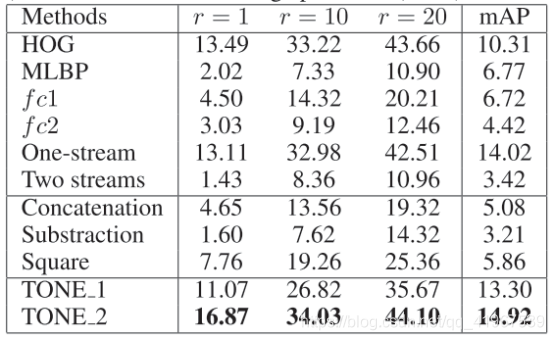
其中TONE表示TwO-stream CNN NEtwork,TONE_1表示fc1,TONE_2表示fc2。
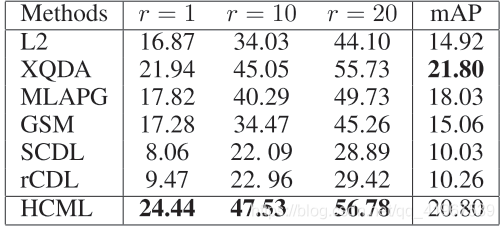
不同方法之间比较: