ML Lecture 5: Classification——Logistic Regression
Logistic回归的缺陷:线性不可分问题/布尔函数异或(XOR)问题
假设有四个样本,它们具有
维特征,蓝色代表样本的真实类别为
,红色代表样本的真实类别为
。将四个样本点在坐标图上表示:

在二分类问题中,Logistic回归所做的事情是计算 。其中, 、 都是 维向量。所以:
并将
代入到Sigmoid函数转换为一个概率值
。
当
或
时,将样本判为第一类。

所以对于上面的样本点应该有:

但
是一条线性的直线,它只能将二维平面划分为两个区域,一个区域代表样本属于
,另一个区域代表样本属于
。而这种线性不可分的样本情况,不是单纯用一条直线就能划分清楚,所以无法用直线
进行分类,或者说分类效果不好。这是Logistic回归本身能力问题:即只能做线性分类,增加样本个数也是无法改善分类效果的。

这种情况下,如果要用Logistic回归方法,只能通过特征转换(Feature Transformation),使其变为Logistic回归可以处理的线性分类问题,才能对样本进行分类。即通过特征转换,使得转换后的新的蓝色点、红色点分别落在一条直线的两边。
特征转换的方法(核方法)有很多种, 核方法的主要思想是基于这样一个假设:在低维空间中不能线性分割的点集,通过转化为高维空间中的点集时,很有可能变为线性可分的,这里以其中一种为例:
把原来的二维特征 转换为新的二维特征 ,其中:
表示 与 之间的距离
表示 与 之间的距离
通过这种转化,蓝色点、红色点分别落在新的位置上,并且是线性可分的:

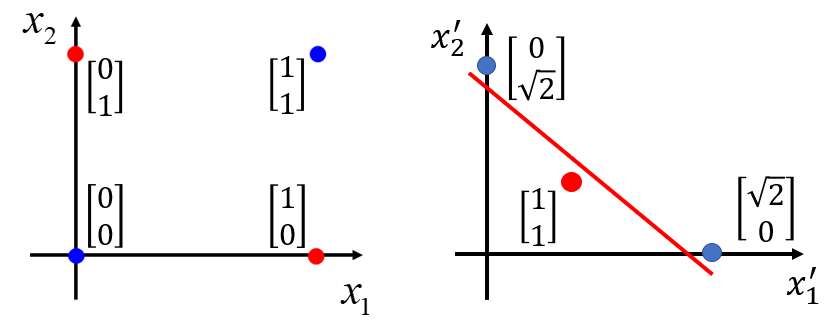
而如何对特征做转化并非很直觉地就能判断出来,通常需要一些专业知识辅助决策。

核方法下的Logistic回归
前面通过核方法做特征转换后,新的二维特征使得样本点变得线性可分,从而能用Logistic回归方法做分类。从“特征转换
分类”的整个过程,可以看成是很多个Logistic回归相叠加的结果。

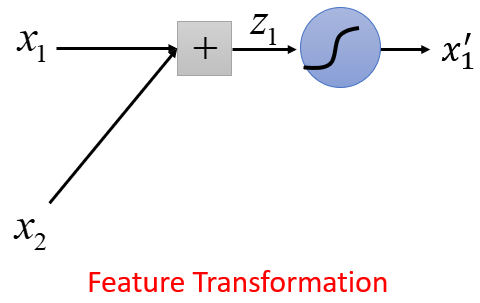
原来的样本特征 的过程,可以视为一个Logistic回归(蓝色)完成的:它的输入是 、 ,输出是
原来的样本特征 的过程,可以视为另外一个Logistic回归(绿色)完成的:它的输入是 、 ,输出是
新特征 使样本变得线性可分,这个分类过程是红色Logistic回归完成的:它的输入是 、 ,它的输出是概率值


下面举例说明特征转换的过程确实可以通过Logistic回归完成。对于样本点:
假设蓝色Logistic回归的参数为: , , 。
对每个样本计算 ,则经过特征转换后,每个样本的第一维特征发生变化:以上转换过程视为矩阵运算:
假设绿色Logistic回归的参数为: , , 。
对每个样本计算 ,则经过特征转换后,每个样本的第二维特征发生变化:以上转换过程视为矩阵运算:
四个样本点都有了新的特征值:
将其画在二维坐标图上,通过红色Logistic回归进行分类:




总结
综上,尽管Logistic回归没有办法进行非线性的分类,但通过把不同的Logistic回归串接起来:前面的Logistic回归负责特征转换(如第 、 步),最后一个Logistic回归负责分类(如第 步)。
当把所有的Logistic回归串接起来以后,这些Logistic回归的参数是可以同时训练得到的,只要知道输入值、输出值,就可以利用梯度下降,把所有的参数一次性训练出来。

其中,每一个Logistic回归又称为神经元(Neuron),类似于人脑中的神经元。当把许多个神经元串接在一起后,所形成的整体就称为神经网络(Neural Network),由此进入深度学习的范畴。

参考资料:
总结一下遇到的各种核函数~
维基百科:逻辑异或