ML Lecture 7: Backpropagation
反向传播(Backpropagation,BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的、用来训练人工神经网络的常见方法。该方法对网络中所有权重参数计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。
回顾梯度下降法求解最优参数:令损失函数
L(θ)
对每一个参数分别求偏导,构成梯度向量
∇L(θ)
,以学习率
η
不断迭代更新参数。当参数量十分庞大时,借助反向传播算法可以更高效地计算梯度。

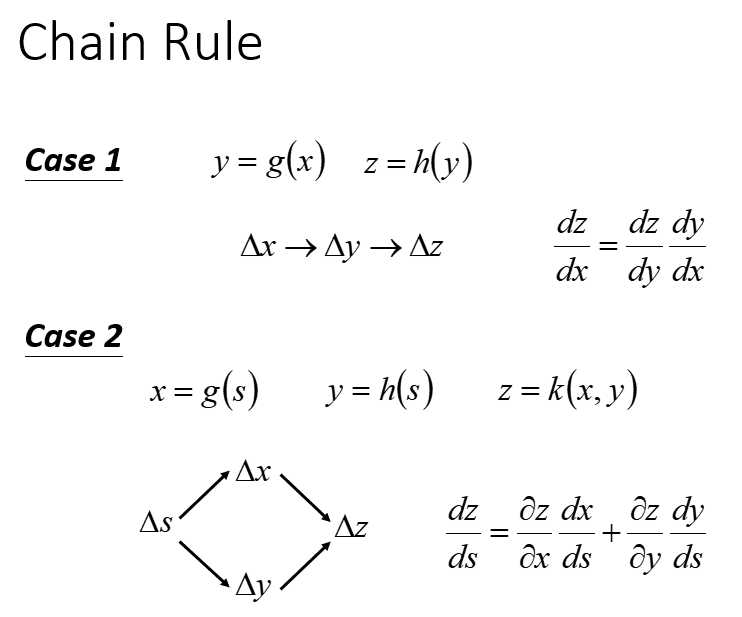
1. 链式法则(Chain Rule)回顾
对于两个函数
y=g(x)
和
z=h(y)
,自变量
x
的变化会引起
y
的变化,
y
的变化又会引起
z
的变化,这个连续的影响过程可以表示为:
△x→△y→△z
。根据求导法则有:
dzdx=dzdydydx
对于函数
x=g(s)
、
y=h(s)
及二元函数
z=k(x,y)
,自变量
s
的变化会分别引起
x
、
y
的变化,而
x
、
y
的变化又会进一步影响
z
。根据链式求导法则,
s
是通过两条路径影响
z
的:
dzds=∂z∂xdxds+∂z∂ydyds
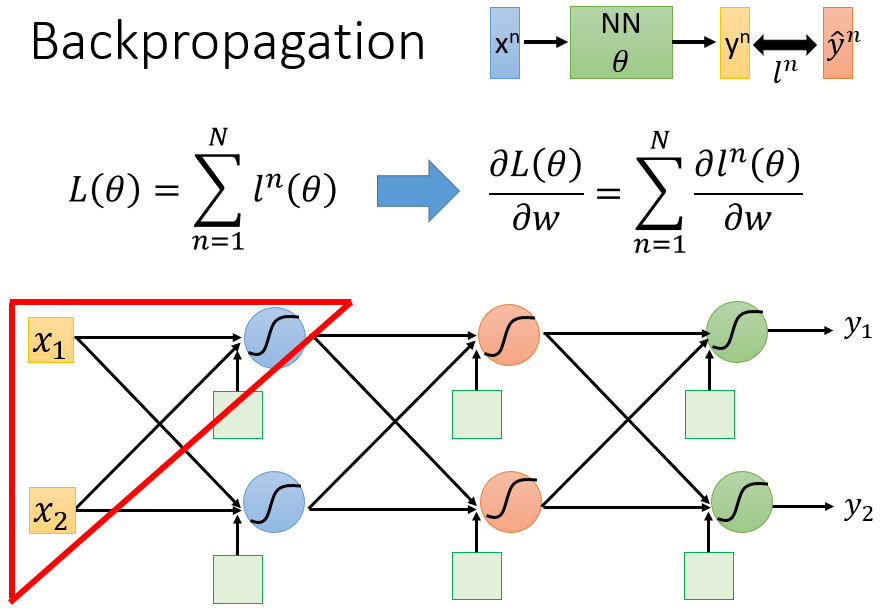
2. 反向传播(Backpropagation)的原理
首先明确,反向传播算法是一种辅助计算梯度向量的有效方法。利用反向传播算法计算出梯度后,就可以按照梯度下降法去更新参数。
在机器学习的第二个步骤中,我们定义了一个损失函数
L(θ)
用于判断函数的优劣,这个损失函数
L(θ)
是基于所有训练样本计算出来的。假设记第
n
个训练样本
xn
的损失函数为
ln(θ)
,则
L(θ)=∑Nn=1ln(θ)
。
在第三个步骤中,我们以损失函数
L(θ)
最小化为目标寻找最优参数,需要计算
L(θ)
对各个权重参数的偏导数。实际上,
L(θ)
对某一个权重参数
w
的偏导数
∂L(θ)∂w
,即各个训练样本的损失函数
l(θ)
分别对
w
求偏导,最后加总求和得到的:
∂L(θ)∂w=∑n=1N∂ln(θ)∂w
因此,损失函数的偏导数计算问题,就从计算
∂L(θ)∂w
转变为计算
∂l(θ)∂w
。
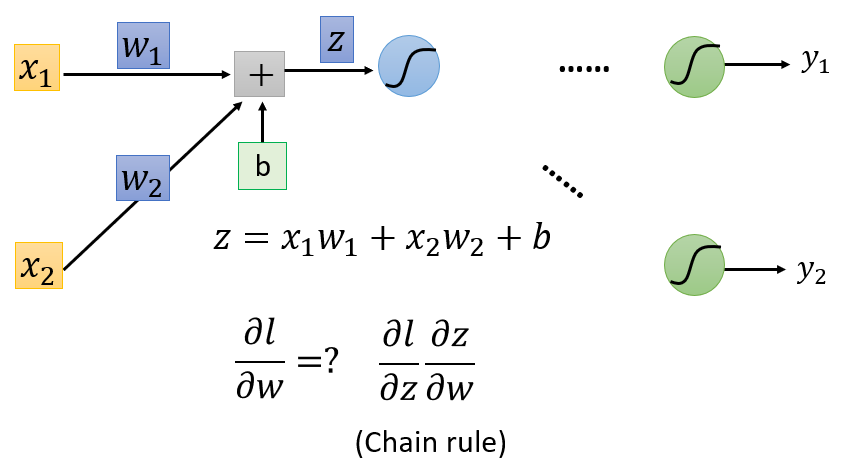
以其中一个神经元为例:假设该神经元的参数为
θ=(w1,w2,b)
,输入样本
x
是一个二维向量
[x1x2]
,则样本
x
在这个神经元里,经过了一个线性变换(并在后续神经元里经过一系列转换,得到最后的输出
y
):
z=w1x1+w2x2+b
记样本
x
的损失函数
l
,对于参数
θ
中的权重参数
w1
(或
w2
)的偏导数为
∂l∂w1
(或
∂l∂w2
),则根据链式求导法则有:
∂l∂w=∂l∂z∂z∂w
其中,
w=w1
或
w2
。这里的影响路径是:改变参数
w
,就会影响线性变换的结果
z
,而
z
会进一步影响损失函数
l
。
因此,损失函数的偏导数计算问题,就从计算
∂l(θ)∂w
转变为计算
∂l∂z
和
∂z∂w
。 其中,第一项
∂l∂z
称为反向传播(Backward Pass);第二项
∂z∂w
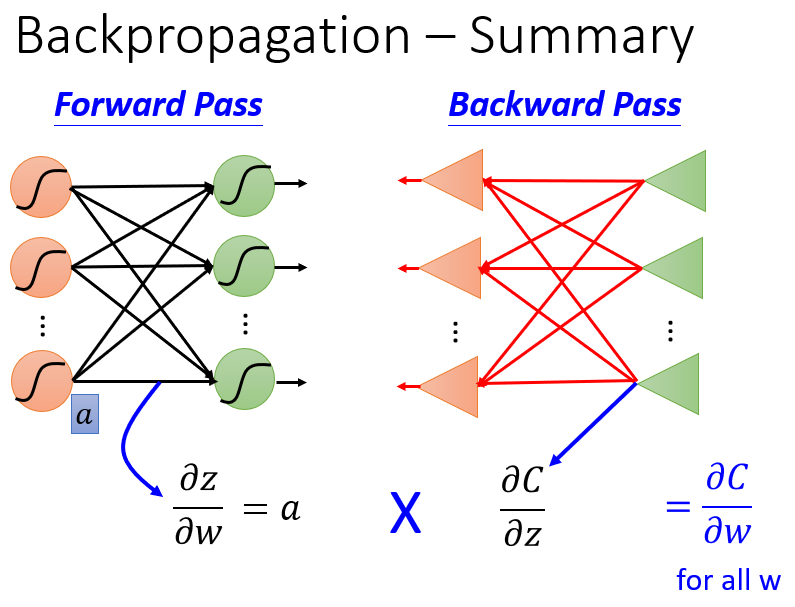
称为前向传播(Forward Pass)。

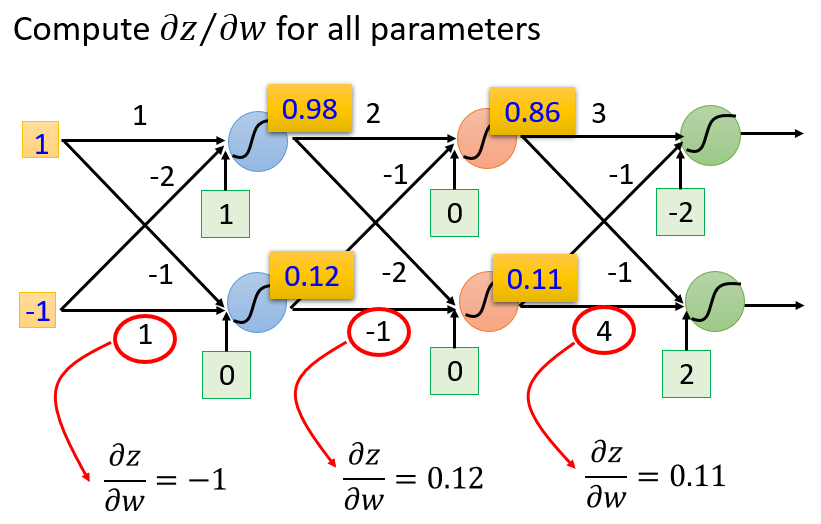
(1)前向传播阶段(Forward Pass)计算
∂z∂w
前向传播阶段的计算十分简单。需要计算的偏导数为
∂z∂w
,以上面单个神经元为例,线性变换
z=w1x1+w2x2+b
,则
2
个权重参数的偏导数分别为:
∂z∂w1=x1
∂z∂w2=x2
偏导数的计算结果恰好是这个神经元的输入
x=[x1x2]
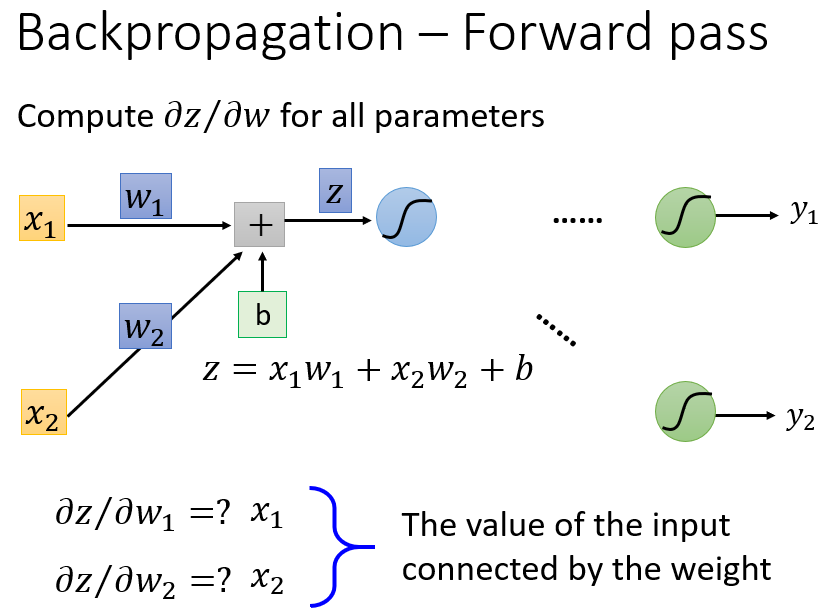
上面是单个神经元对自身各权重参数求偏导的情况。以此类推,任何一个神经元对自身权重参数的偏导,就是该神经元的输入值。
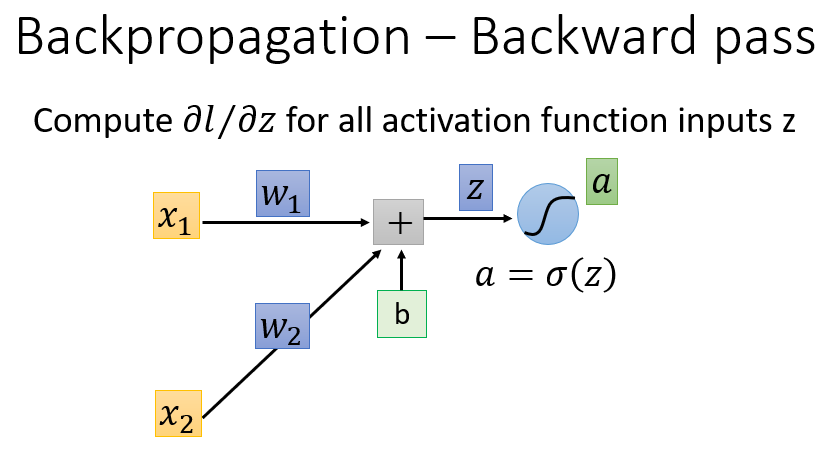
(2)反向传播阶段(Backward Pass)计算
∂l∂z
反向传播阶段计算的偏导数为
∂l∂z
。首先考察线性变换
z
是如何影响损失函数
l
的:
z
通过一个激活函数
σ()
后,得到
a
。因此,
z
是通过影响
a
的值,进而影响损失函数
l
的值。
【注】:这里的激活函数是Sigmoid函数
σ(z)
,现在比较常用的是ReLU、tanh等激活函数,详见神经网络之激活函数(Activation Function)。
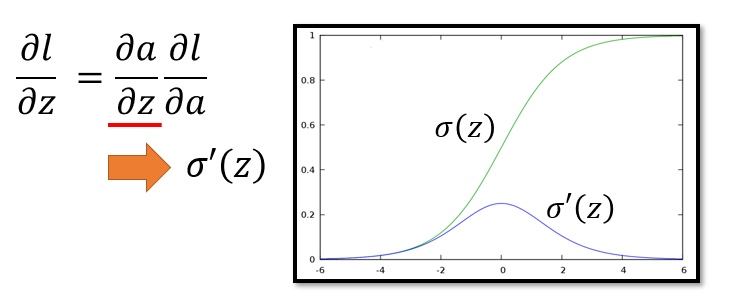
根据链式法则,偏导数
∂l∂z=∂l∂a∂a∂z
。
其中
∂a∂z
这一项取决于激活函数的具体表达式,计算比较简单。以Sigmoid函数
a=σ(z)=11+e−z
为例,偏导数
∂a∂z=σ′(z)=σ(z)(1−σ(z))
。若在同一坐标图上画出
σ(z)
和
σ′(z)
的形状:由于
σ(z)
左右两端变化慢,中间段斜率很大,所以
σ′(z)
的两端趋近于
0
,在中间位置达到最大值,如下图。
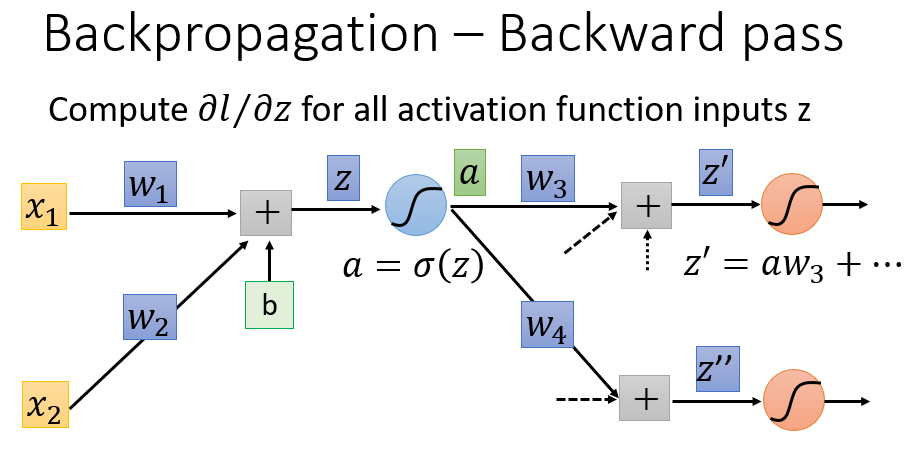
而另外一项
∂l∂a
的计算则比较复杂,涉及到所谓的“反向传播”。经过第一层Sigmoid函数转化后,得到的
a=σ(z)
,将传入下一层的每一个神经元,所以
a
会影响到后面所有神经元。现在假设
a
后面还有两个神经元,显然
a
会影响到
z′
和
z′′
:
z′=aw3
、
z′′=aw4
。
因此,
∂l∂a
就要继续按照链式法则展开,写成:
∂l∂a=∂l∂z′∂z′∂a+∂l∂z′′∂z′′∂a
。
其中,
∂z′∂a=w3
,
∂z′′∂a=w4
。
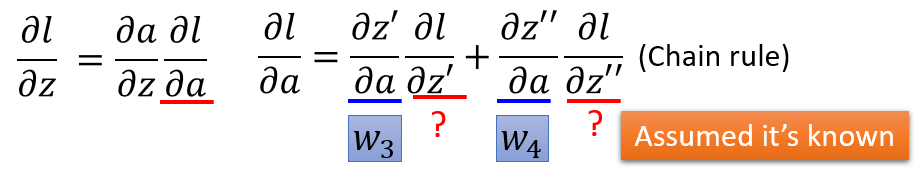
则反向传播阶段所要计算的偏导数
∂l∂z
就可以总结为:
∂l∂z=∂l∂a∂a∂z=(w3∂l∂z′+w4∂l∂z′′)σ′(z)
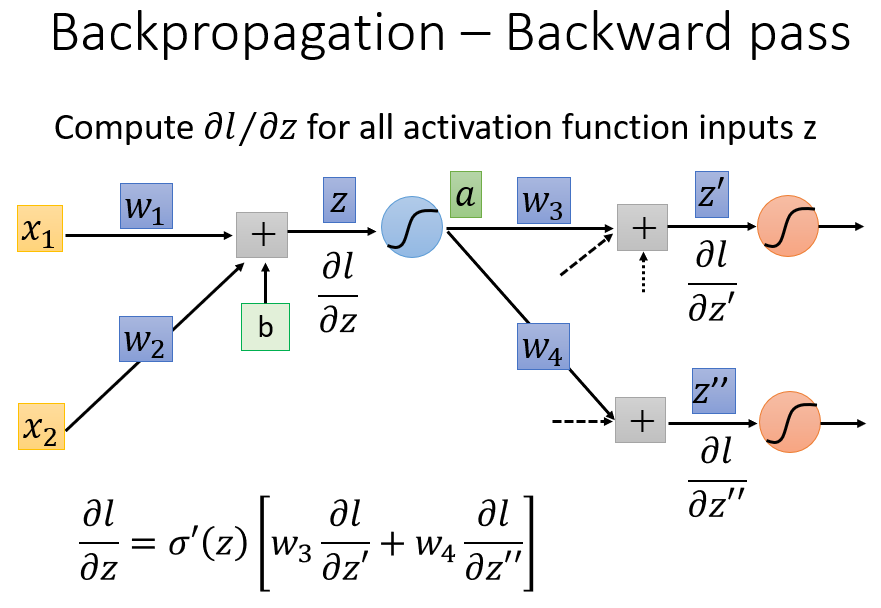
上面的式子可以从反向传播的角度来解读:把这个式子视为一个线性的神经元,一般我们认为神经元就是把输入值
x
在权重参数
w
的作用下,加上偏置值,通过激活函数,得到输出值。上述式子可以把
∂l∂z′
、
∂l∂z′′
视为输入,把
w3
、
w4
视为权重,经过一个线性的激活函数,相当于经过一个运算放大器(Operational Amplifier,op-amp),即乘上一个常数
σ′(z)
,得到输出
∂l∂z
。
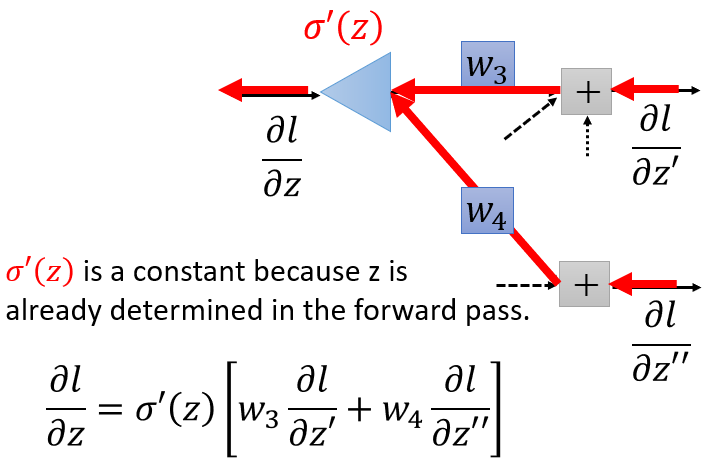
至此,剩下的问题就是如何求得
∂l∂z′
和
∂l∂z′′
,分为如下两种情况讨论:
若
z′
和
z′′
通过激活函数后,得到的就是输出值,即已经抵达终点。那么由链式法则:
∂l∂z′=∂l∂y1∂y1∂z′
∂l∂z′′=∂l∂y2∂y2∂z′′
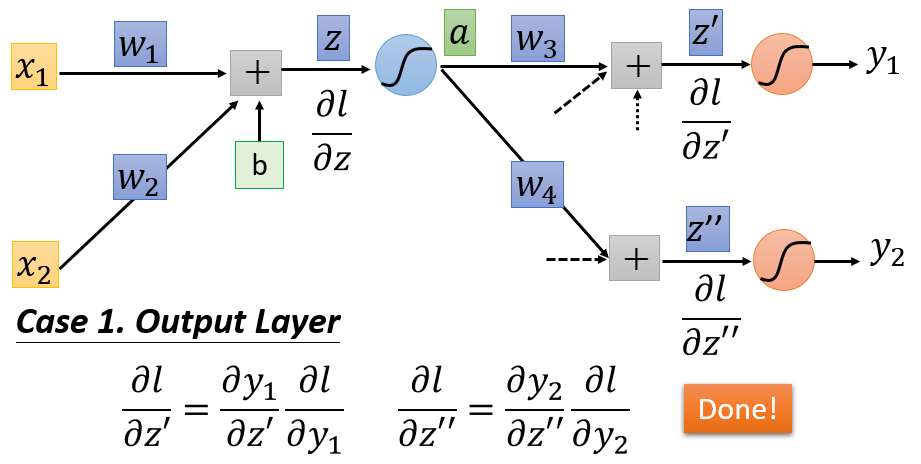
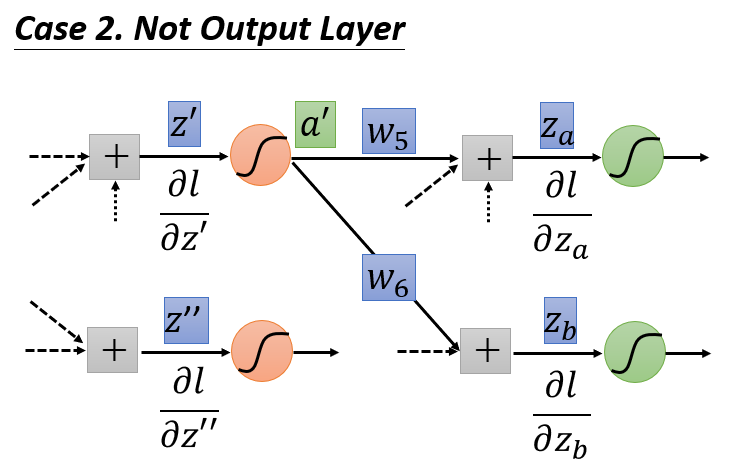
若
z′
和
z′′
通过激活函数后,还未到达输出层,后面还连接有其他神经元,那么链式法则就继续延伸。以
z′
为例,其通过激活函数后,得到
a′
,现在假设后面还有两个神经元
za
和
zb
。显然
a′
会影响到
za
和
zb
:
za=a′w5
、
zb=a′w6
。
那么根据链式法则:
∂l∂z′=∂l∂a′∂a′∂z′=[∂l∂za∂za∂a′+∂l∂zb∂zb∂a′]∂a′∂z′=[∂l∂zaw5+∂l∂zbw6]σ′(z′)
。
同理,可以计算
∂l∂z′′
。
偏导数
∂l∂z
的整个运算过程归纳如下。如果从Input的方向从前往后看,随着神经元个数不断增加,运算量以递归的形式不断增大。
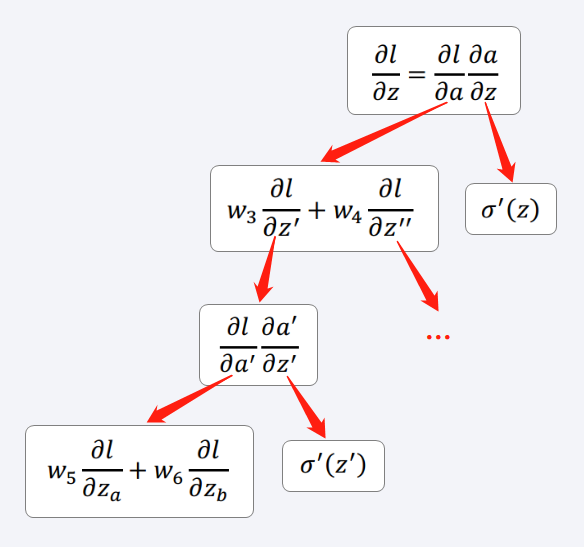
容易观察:只要知道
∂l∂za
和
∂l∂zb
,就能够计算出
∂l∂a′
,进而求出
∂l∂z′
;只要知道
∂l∂z′
和
∂l∂z′′
,就能够计算出
∂l∂a
,进而求出
∂l∂z
。这里,
σ′(z)
和
σ′(z′)
相当于两个线性放大器op-amp。如果神经元个数继续增加,那么
∂l∂za
和
∂l∂zb
就要继续往后做递归推算,直到抵达输出层。
而从Output的方向出发,从后往前看,计算量会大大减少。
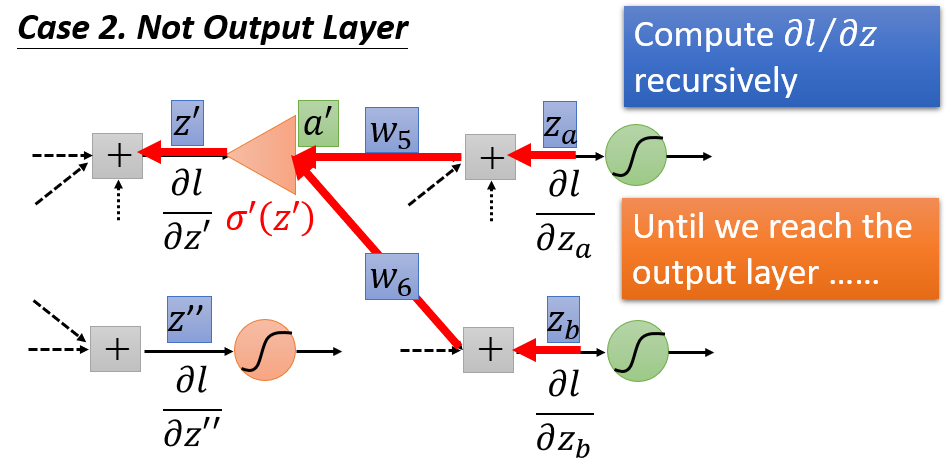
假设一共有如下
6
个神经元:
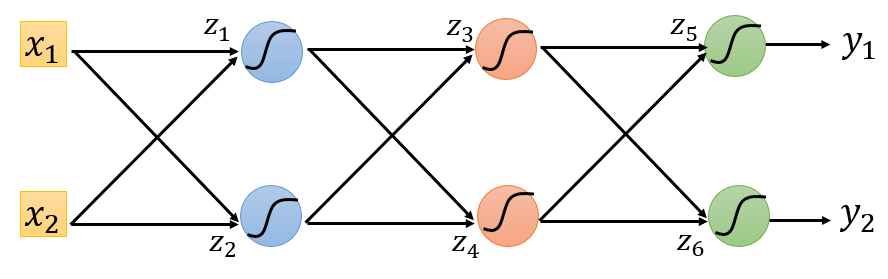
如果从前往后看,要求出
∂l∂z1
,就必须先知道
∂l∂z3
和
∂l∂z4
;要求出
∂l∂z3
,就必须先知道
∂l∂z5
和
∂l∂z6
,运算过程很复杂
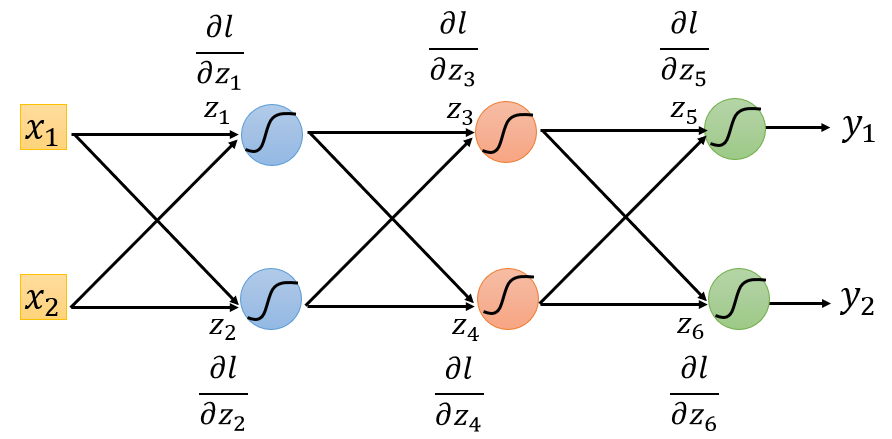
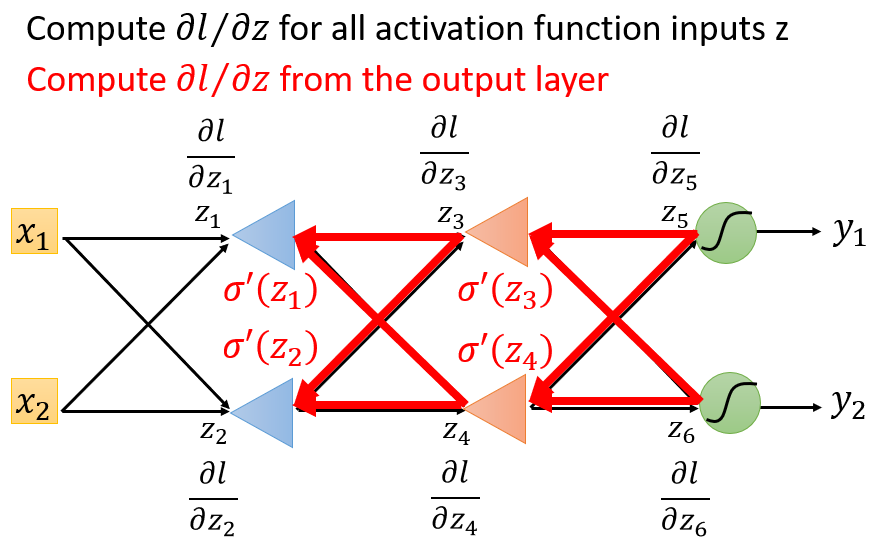
如果从后往前看,这个问题就被简化了。如下图,把原来的神经网络通通逆转,把所有神经元全部用op-amp取代,放大倍率就是原神经元的激活函数的导数:
σ′(z1)...σ′(z4)
。
先计算
∂l∂z5
和
∂l∂z6
,这两个偏导的计算是简单的,因为它们连接着输出层。分别经过op-amp
σ′(z3)
和
σ′(z4)
后,求出
∂l∂z3
和
∂l∂z4
。
再将
∂l∂z3
和
∂l∂z4
经过op-amp
σ′(z1)
和
σ′(z2)
,求出
∂l∂z1
和
∂l∂z2
。
注意到,这个运算过程与完全连接前馈式神经网络的计算量是一样的。
总结
将神经网络简化为如下构造:
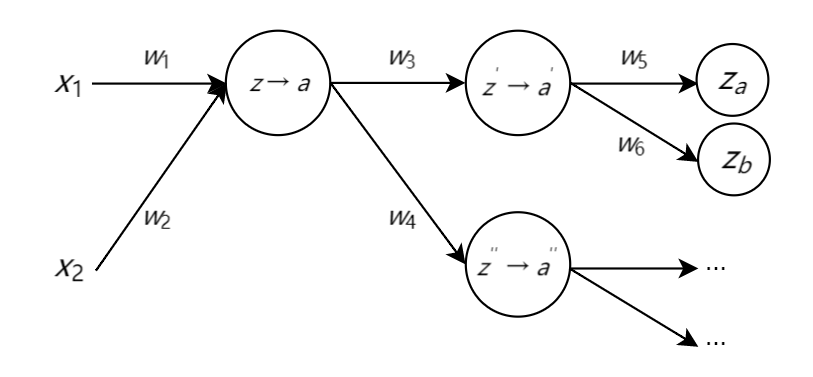
则在反向传播算法中,各个计算过程分别为:
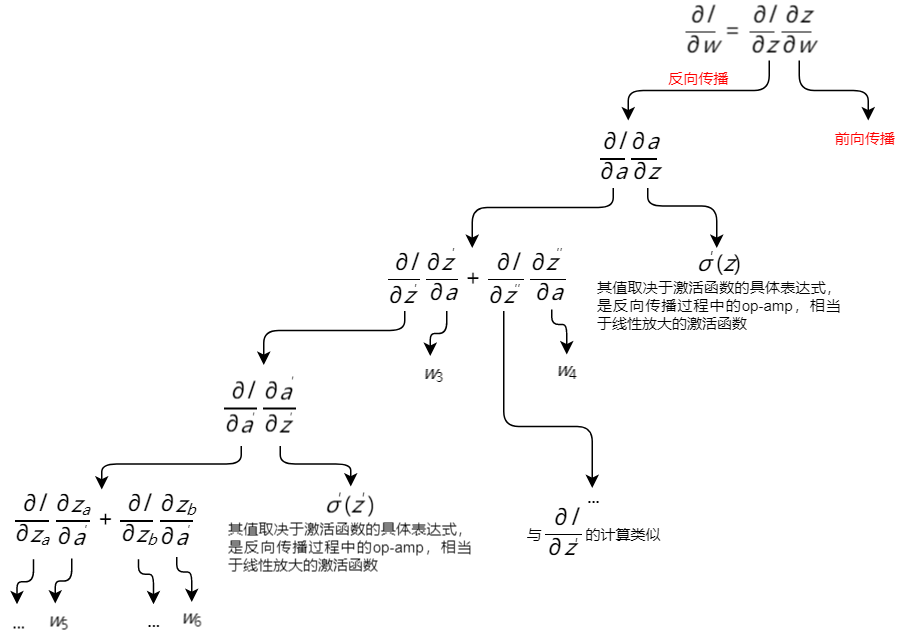
- 前向传播阶段(Forward Pass)的目标是计算
∂z∂w
我们需要知道最开始的输入值,以及每一层各个神经元的输出,这些值就是各个神经元所对应的权重参数的偏导数
∂z∂w
- 反向传播阶段(Backward Pass)的目标是计算
∂l∂z
先把神经网络逆转,用op-amp替换所有神经元,从后往前计算各个神经元的
∂l∂z
最后,将
∂z∂w
和
∂l∂z
相乘,就可以得到单个样本的损失函数
l
对神经元中各权重参数
w
的偏导数
∂l∂w
,用反向传播算法可以简单地将整个神经网络里的所有权重参数的偏导值求出来,构成一个梯度向量,这个梯度向量可以根据梯度下降法对参数进行更新。
参考资料:
维基百科:反向传播算法
一小时神经网络从入门到精通(放弃)
如何直观地解释 back propagation 算法?
手撸反向传播算法+代码实现
计算实栗
根据反向传播算法的过程:


其中,
∇a
是求梯度运算符,
∇aC=∂C∂aL
是一个向量,
L
表示最后一层(输出层)。
假设有如下三层神经网络:
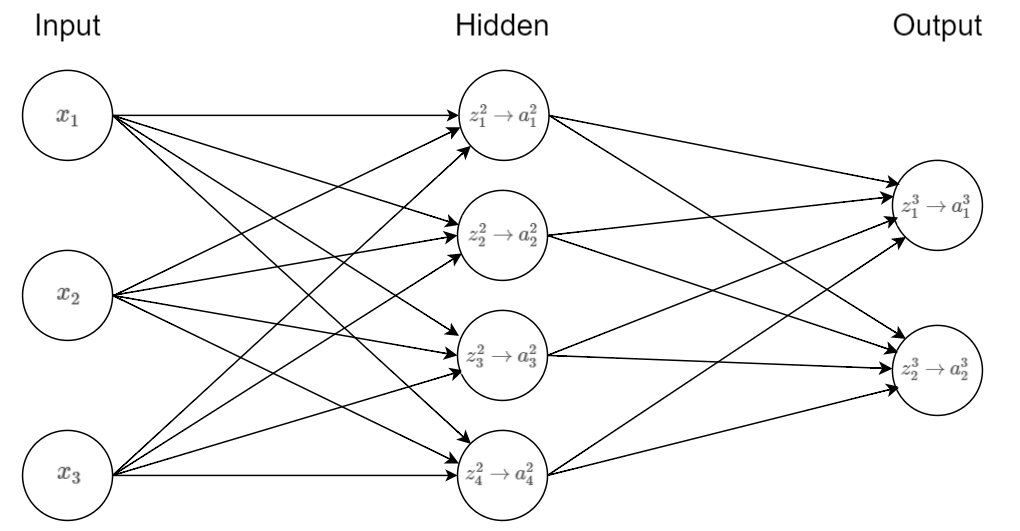
第一个输入层:样本
x=⎡⎣⎢x1x2x3⎤⎦⎥
第二个隐藏层有
4
个神经元:权重矩阵为
W2=⎡⎣⎢⎢⎢⎢w211w221w231w241w212w222w232w242w213w223w233w243⎤⎦⎥⎥⎥⎥4×3
,偏置矩阵为
b2=⎡⎣⎢⎢⎢⎢b21b22b23b24⎤⎦⎥⎥⎥⎥
带权输入为
z2=⎡⎣⎢⎢⎢⎢z21z22z23z24⎤⎦⎥⎥⎥⎥
,激活向量为
a2=⎡⎣⎢⎢⎢⎢a21a22a23a24⎤⎦⎥⎥⎥⎥
第三个输出层有
2
个神经元:权重矩阵为
W3=[w311w321w312w322w313w323w314w324]2×4
,偏置矩阵为
b3=[b31b32]
带权输入为
z3=[z31z32]
,激活向量为
a3=[a31a32]
【注】:第
l
个隐藏层的参数矩阵
Wl
,它的行数是该隐藏层(第
l
层)的神经元个数,它的列数是上一层(第
l−1
层)传过来的列向量的维数。
实际计算过程如下:
输入:样本
x
,作为输入层的激活值
a1=x=⎡⎣⎢x1x2x3⎤⎦⎥
前向传播:当
l=2,3
,计算
z2,a2,z3,a3
:
z2=W2a1+b2=⎡⎣⎢⎢⎢⎢w211w221w231w241w212w222w232w242w213w223w233w243⎤⎦⎥⎥⎥⎥⎡⎣⎢x1x2x3⎤⎦⎥+⎡⎣⎢⎢⎢⎢b21b22b23b24⎤⎦⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢w211x1+w212x2+w213x3+b21w221x1+w222x2+w223x3+b22w231x1+w232x2+w233x3+b23w241x1+w242x2+w243x3+b24⎤⎦⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢z21z22z23z24⎤⎦⎥⎥⎥⎥
a2=σ(z2)=⎡⎣⎢⎢⎢⎢σ(w211x1+w212x2+w213x3+b21)σ(w221x1+w222x2+w223x3+b22)σ(w231x1+w232x2+w233x3+b23)σ(w241x1+w242x2+w243x3+b24)⎤⎦⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢a21a22a23a24⎤⎦⎥⎥⎥⎥
z3=W3a2+b3=[w311w321w312w322w313w323w314w324]⎡⎣⎢⎢⎢⎢a21a22a23a24⎤⎦⎥⎥⎥⎥+[b31b32]=[w311a21+w312a22+w313a23+w314a24+b31w321a21+w322a22+w323a23+w324a24+b32]=[z31z32]
a3=σ(z3)=[σ(w311a21+w312a22+w313a23+w314a24+b31)σ(w321a21+w322a22+w323a23+w324a24+b32)]=[a31a32]
计算输出层误差向量
δ3
:
δ3=∇aC⊙σ′(z3)=∂C∂a3⊙σ′(z3)=⎡⎣⎢∂C∂a31∂C∂a32⎤⎦⎥⊙[σ′(z31)σ′(z32)]=⎡⎣⎢∂C∂a31⋅σ′(z31)∂C∂a32⋅σ′(z32)⎤⎦⎥=[δ31δ32]
计算反向误差传播
δ2
:
δ2=((W3)Tδ3)⊙σ′(z2)=([w311w321w312w322w313w323w314w324]T[δ31δ32])⊙⎡⎣⎢⎢⎢⎢⎢σ′(z21)σ′(z22)σ′(z23)σ′(z24)⎤⎦⎥⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢⎢(w311δ31+w321δ32)⋅σ′(z21)(w312δ31+w322δ32)⋅σ′(z22)(w313δ31+w323δ32)⋅σ′(z23)(w314δ31+w324δ32)⋅σ′(z24)⎤⎦⎥⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢δ21δ22δ23δ24⎤⎦⎥⎥⎥⎥
代价函数的梯度元素计算公式为:
∂C∂wljk=al−1k⋅δlj
和
∂C∂blj=δlj
,以计算偏导数
∂C∂w211
为例:
由公式:
∂C∂w211=a11⋅δ21=x1⋅δ21
由链式法则:
∂C∂w211=∂z21∂w211∂a21∂z21∂z31∂a21∂a31∂z31∂C∂a31+∂z21∂w211∂a21∂z21∂z32∂a21∂a32∂z32∂C∂a32
=x1⋅σ′(z21)⋅w311⋅σ′(z31)⋅∂C∂a31+x1⋅σ′(z21)⋅w321⋅σ′(z32)⋅∂C∂a32
=x1⋅σ′(z21)⋅[w311⋅σ′(z31)⋅∂C∂a31+w321⋅σ′(z32)⋅∂C∂a32]
=x1⋅σ′(z21)⋅[w311⋅δ31+w321⋅δ32]
=x1⋅δ21
因此,由反向传播计算公式与链式法则的计算结果完全一致。