版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/aFeiOnePiece/article/details/47710423
本文是 Andrew Ng 《机器学习》公开课的学习笔记
现实中的例子有 ,垃圾邮件/非垃圾邮件, 肿瘤是良性还是恶性等等。
怎么分类?
我从高中数学积累了一个经验。假设直线方程是 f(x) = 0, 那么直线左边的点带入直线方程左边,得到的结果 < 0;相反,直线 右边的点带入直线方程左边的式子,得到的结果 > 0。
所以,如果我们能找到这样一条直线,使它左边的点 属于 A类,右边的点 属于 B类,那么再有一个新的点进来,我们就可以知道这个点 属于哪一类了!
对,还是找直线(这里为了方面解释,说的是简单的模型。也可以是 多个feature,高次幂等等。)
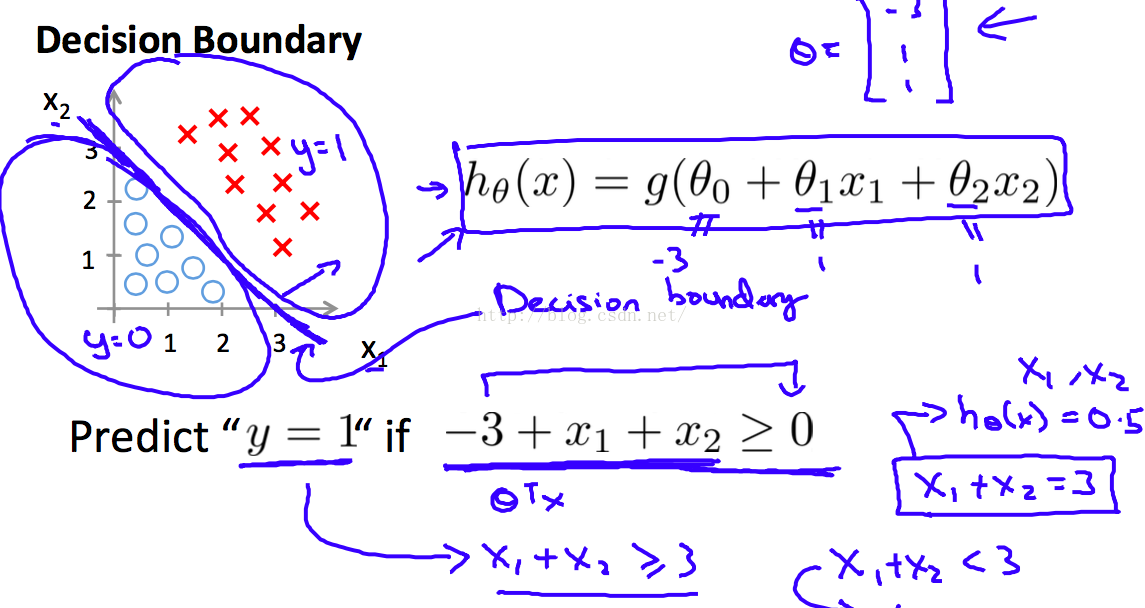

为什么说是 Regression呢?因为我们用了 linear regression的 hypothesis。
为什么说是 Logistic呢?因为这里的结果只有 0 和1 (离散的)。linear regression的结果是连续的。
上面仅仅用 > 或者 < 表达的式子,没本法找 costFunction,不能求最优解。于是,伟大的科学家想到了下面这个式子,对 hypothesis做了一个转换
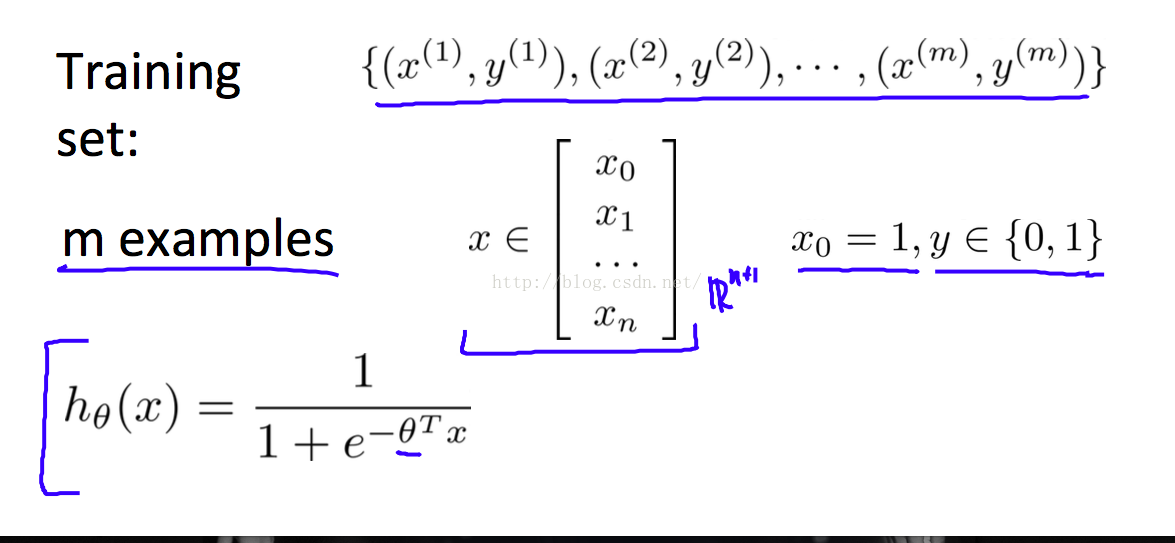
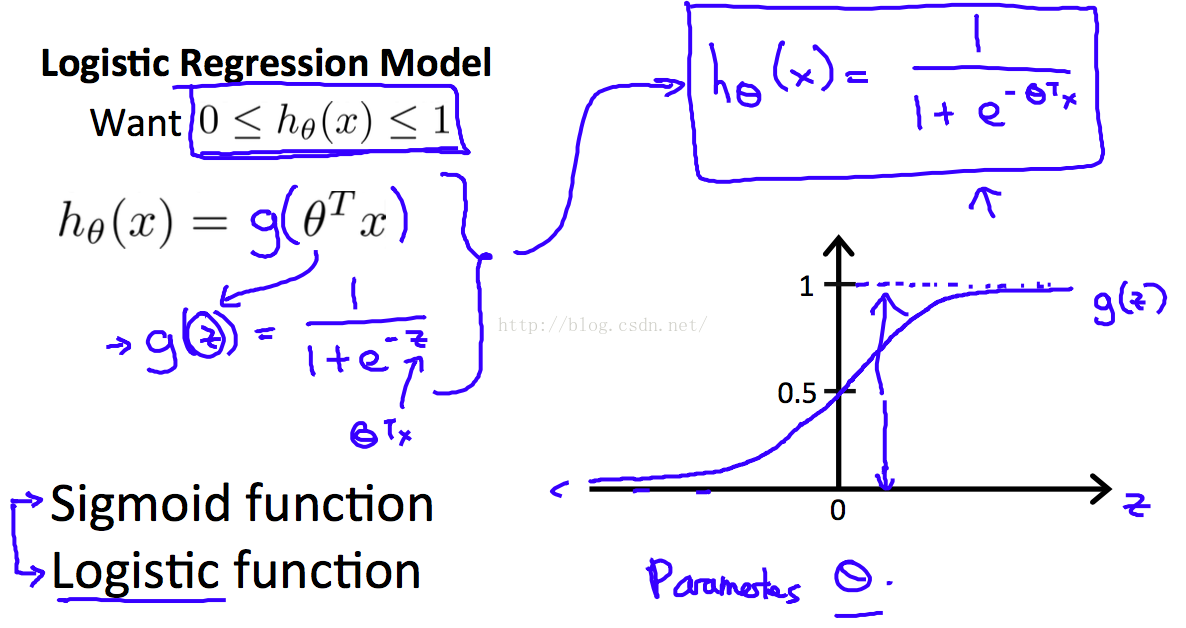
可以看到 转换以后,h(x)的取值范围是 0~1,Z >0 时,h(x) > 0.5。 Z < 0时,h(x) < 0.5。这样我们通过h(x)的取值来判断分类了。
求Theta,当然还是要靠 min CostFunction啦
因为h(x)变化了,costfunction如果采用linear regression的形式,其就不是 convex的了,就不能使用梯度下降法
convex 和non-convex的比较
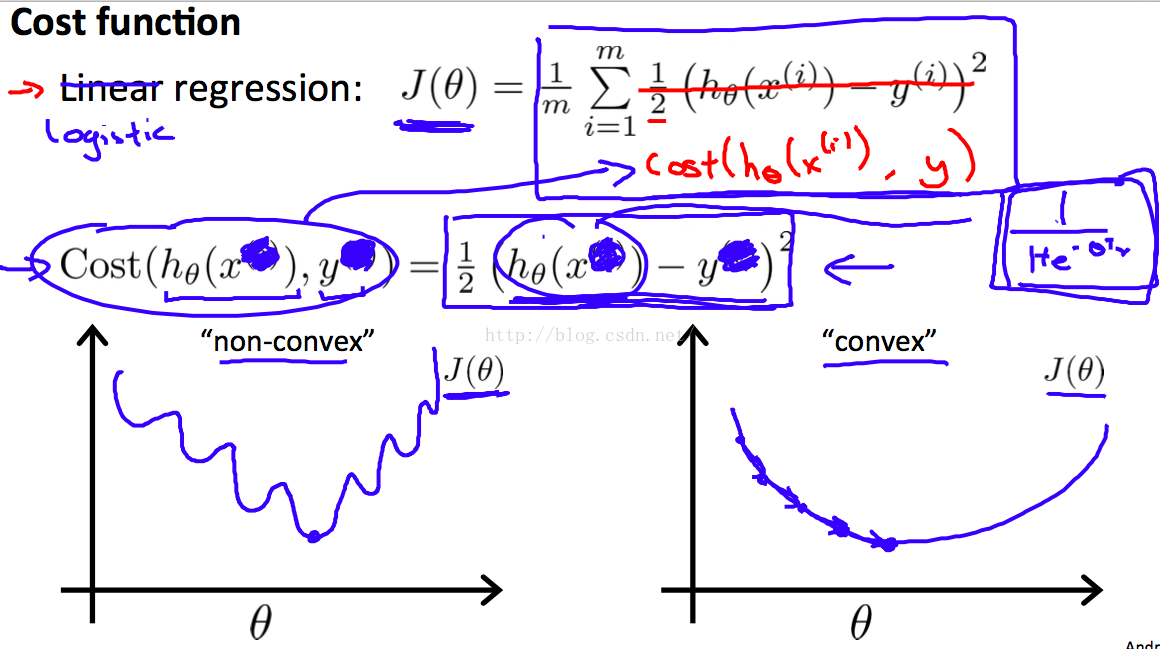
于是,前辈想到了给 h(x) 加log的方式作为 costFunction,这样的costFunction又变为convex

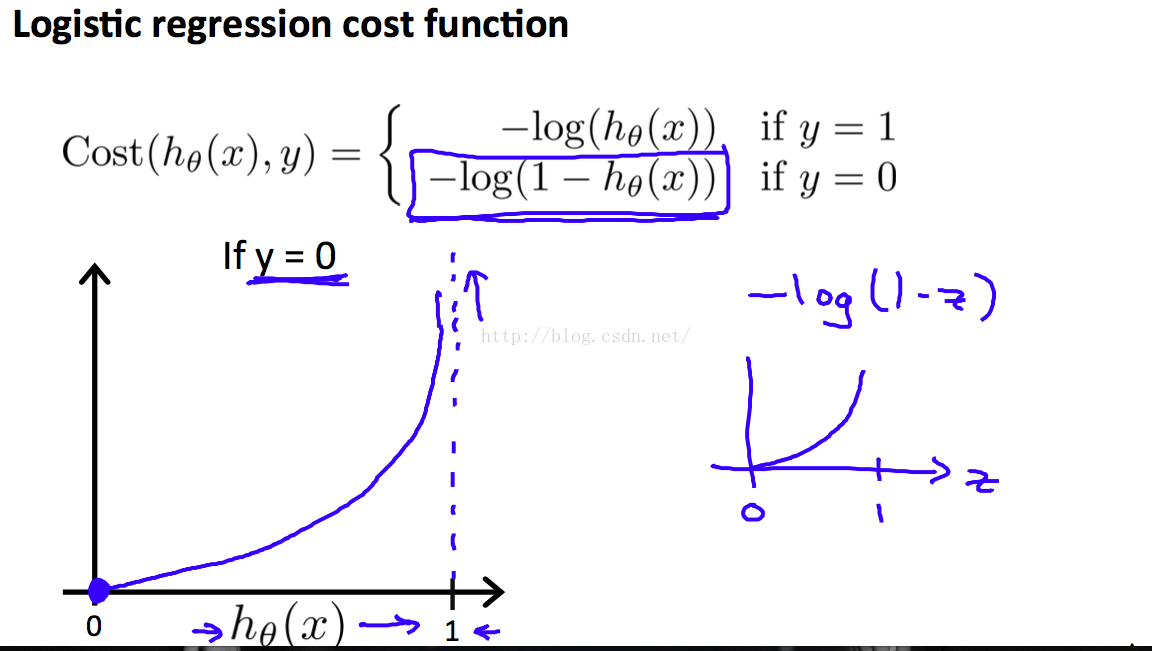
由上面两个曲线可知,当y=1时,costFunction逐渐减小的办法就是 使 h(x)趋近于1
当y=0时,要costFunction逐渐减小,就是使h(x)趋近于0,这整合我们的意思。
两个式子总归不好求,于是有了下面的合体,而且 求导以后的 式子也是那么的和谐。美!


使用梯度下降法得到的 更新theta的式子,表达上可以跟 linear regression如此的相似,差别只在h(x)上。
其实,从h(x)的取值上来看,我们可以理解为,预测结果为1的概率是h(x)
即

multi-class classifiation
one-vs-all classification。 一对多分类,就是说,把多类别转换成 2类,A类和余下的所有类。这样就可以采用上述分两类的 logistic regression方法。
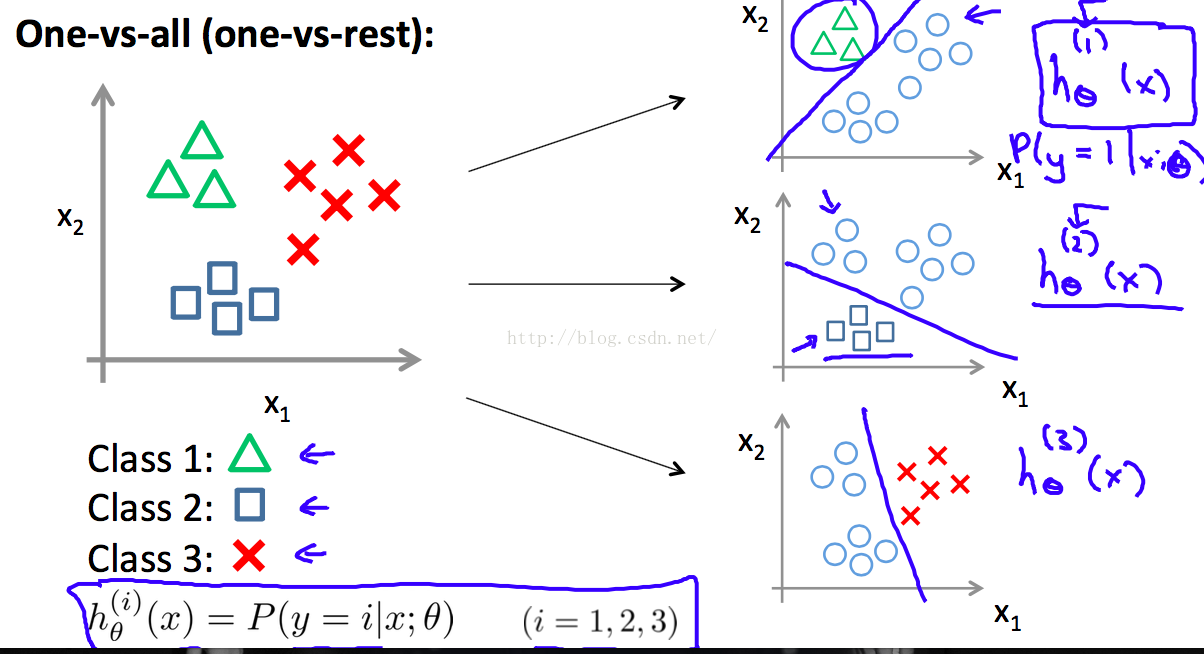
通过one-vs-all的方法,对每一类都要训练出一个 hypothesis。
最后通过对多个hypothesis的结果进行比较然后预测
