本篇博客主要介绍pyspark.ml中Classification、Clustering、Regression包的使用。
1. Classification
1.1 概览
ml.Classification包中包含的分类算法及其相关类主要如下:
| 分类算法 | 相关类 |
|---|---|
| 线性支持向量分类 | LinearSVC、LinearSVCModel、LinearSVCSummary 、LinearSVCTrainingSummary |
| 逻辑回归 | LogisticRegression、LogisticRegressionModel、LogisticRegressionSummary、LogisticRegressionTrainingSummary、BinaryLogisticRegressionSummary、BinaryLogisticRegressionTrainingSummary |
| 决策树 | DecisionTreeClassifier、DecisionTreeClassificationModel |
| 梯度提升树GBT | GBTClassifier、GBTClassificationModel |
| 随机森林 | RandomForestClassifier、RandomForestClassificationModel、RandomForestClassificationSummary、RandomForestClassificationTrainingSummary、BinaryRandomForestClassificationSummary、BinaryRandomForestClassificationTrainingSummary |
| 朴素贝叶斯 | NaiveBayes、NaiveBayesModel |
| 多层感知机 | MultilayerPerceptronClassifier、MultilayerPerceptronClassificationModel、MultilayerPerceptronClassificationSummary、MultilayerPerceptronClassificationTrainingSummary |
| 因式分解 | FMClassifier、FMClassificationModel、FMClassificationSummary、FMClassificationTrainingSummary |
| 一对剩余 | OneVsRest、OneVsRestModel |
ml.Classification包中的类主要有以下几种:
- 基础类:可以指定分类算法的各项参数;
- Model类:通过基础类的fit()方法等到;
- Summary类:通过Model对象.evaluate(data)得到,其中data为测试集。通过该类既可以对测试集进行预测,也可以获得分类算法的各项评估指标;
- TrainingSummary类:通过Model对象.summary。可以通过该类获得算法在训练集上的各项评估指标;
1.2 使用案例
本篇仅以逻辑回归为例对ml.Classification中的分类算法的使用进行说明。本案例中使用的是Iris鸢尾花数据集,可以从网上自行下载。
1.2.1 读取数据集
from pyspark.sql import SparkSession
import os
from pyspark.ml.feature import *
from pyspark.ml.classification import *
os.environ['SPARK_HOME'] ='/Users/sherry/documents/spark/spark-3.2.1-bin-hadoop3.2'
spark=SparkSession.builder.appName('ml').getOrCreate()
#读取数据集和测试集
trainSet=spark.read.csv(r'/Users/sherry/Downloads/iris_training.csv',
schema='Feat1 FLOAT,Feat2 FLOAT,Feat3 FLOAT,Feat4 FLOAT,label INT')
testSet=spark.read.csv(r'/Users/sherry/Downloads/iris_test.csv',
schema='Feat1 FLOAT,Feat2 FLOAT,Feat3 FLOAT,Feat4 FLOAT,label INT')
print('训练集数量:{},测试集数量:{}'.format(trainSet.count(),testSet.count()))
trainSet.show(5)
其结果如下:

1.2.2 模型训练
将特征组合成向量
vect_assemble=VectorAssembler(inputCols=['Feat1','Feat2','Feat3','Feat4'],
outputCol='features')
trainSet=vect_assemble.transform(trainSet)
testSet=vect_assemble.transform(testSet)
和模型训练
#训练
LR=LogisticRegression(featuresCol='features',
labelCol='label',
predictionCol='prediction')
LR_model=LR.fit(trainSet)
trainSet=LR_model.transform(trainSet)
trainSet.printSchema()
训练集trainSet经过训练拟合之后默认情况会新增三个列,具体如下:
- rawPrediction: 每个样本在各个类别上的线性回归结果;
- probability: 每个样本属于各个类的概率;
- prediction: 每个样本预测的最终类别;

查看模型参数
经过训练后的Model类即可以获得相关参数,可通过以下方法获得:
| 方法 | 作用 |
|---|---|
| coefficientMatrix | 模型参数 |
| coefficients | 二分类逻辑回归的模型参数 |
| interceptVector | 模型截距 |
| intercept | 二分类逻辑回归的截距 |
iris数据集是个三分类数据集,所以想要获得模型参数及截距需要通过coefficientMatrix和interceptVector。具体举例如下:
coefficient=LR_model.coefficientMatrix
intercept=LR_model.interceptVector
print(coefficient)
print(intercept)
其结果如下:

多分类逻辑回归采用OneVsRest模式训练,所以会有三个线性回归模型(可以参考:。这里仅以第一组结果为例进行说明:
coefficient=LR_model.coefficientMatrix
intercept=LR_model.interceptVector
getVectItem=func.udf(lambda x:x.toArray().tolist()[0],FloatType())
y=trainSet.select('features','rawPrediction',
getVectItem('rawPrediction').alias('y'))
get_y=func.udf(lambda x:float(x.dot(coefficient.toArray()[0])+intercept.toArray()[0])),
FloatType())
y=y.select('features','y',get_y('features').alias('y1'))
y.select('y','y1').show()
其结果如下:

模型评估指标
Summary类和TrainingSummary类提供的评估指标类似,所以这里仅以Summary类为例进行介绍。该类提供的属性和方法主要如下:
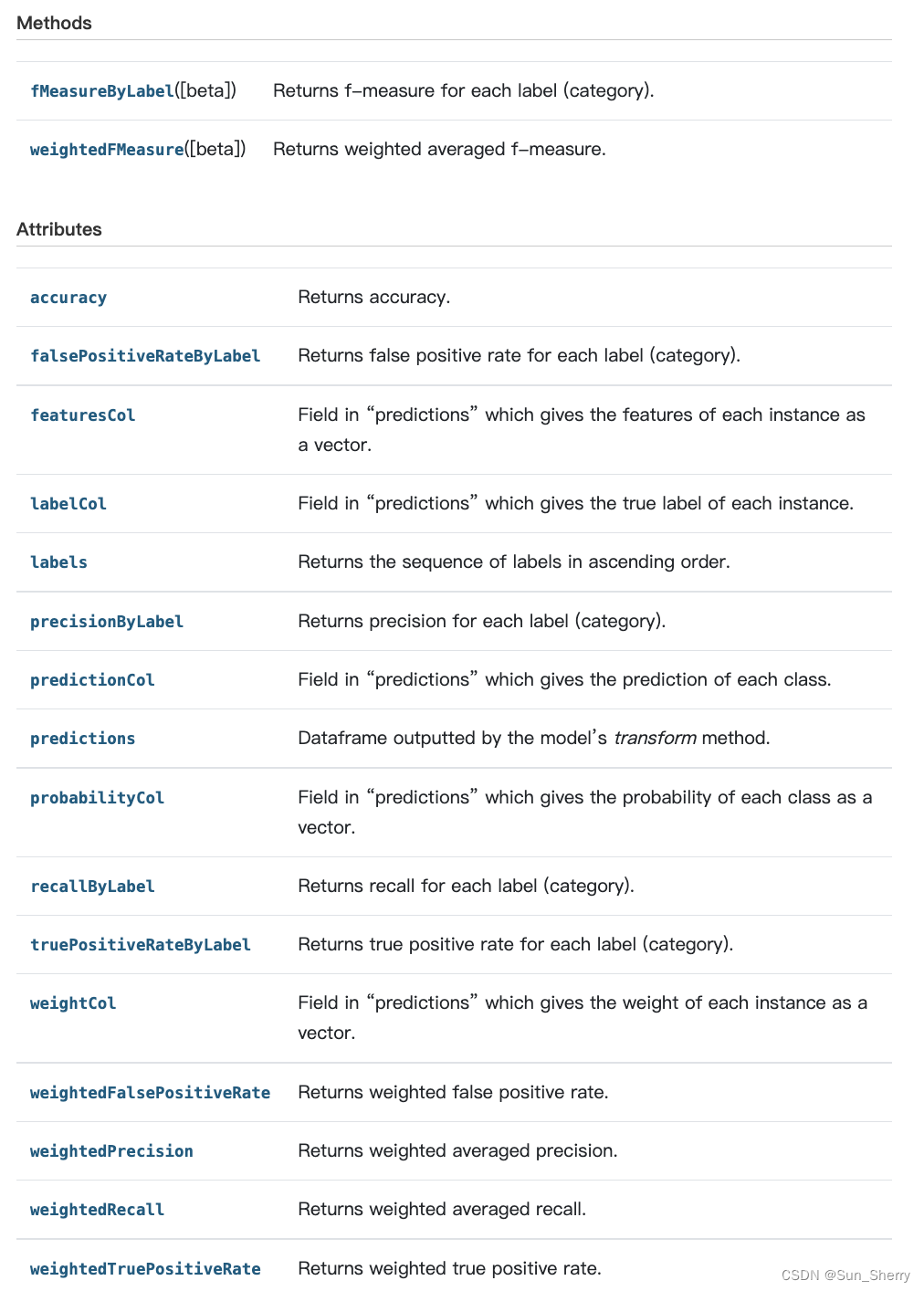
用法举例如下:
testSummary=LR_model.evaluate(testSet)
accuracy=testSummary.accuracy
FPR=testSummary.falsePositiveRateByLabel
precision=testSummary.precisionByLabel
Recall=testSummary.recallByLabel
TPR=testSummary.truePositiveRateByLabel
F_meature=testSummary.fMeasureByLabel()
这里要注意,testSet必须是未经模型训练的,否则会抱如下错误:IllegalArgumentException: requirement failed: Column prediction already exists.
2. Clustering
2.1 概览
ml.Clustering包中提供的聚类算法及其类如下:
| 聚类 | 相关类 |
|---|---|
| 二分K均值 | BisectingKMeans、BisectingKMeansModel、BisectingKMeansSummary |
| K均值++ | KMeans、KMeansModel、KMeansSummary |
| 高斯混合聚类 | GaussianMixture、GaussianMixtureModel、GaussianMixtureSummary |
| 主题模型 | LDA、LDAModel、LocalLDAModel、DistributedLDAModel |
| 幂迭代聚类 | PowerIterationClustering |
2.2 使用案例
这里使用K均值++对iris数据集进行聚类。其具体代码如下:
from pyspark.sql import SparkSession
import os
from pyspark.ml.feature import *
from pyspark.ml.clustering import *
from pyspark.sql.types import *
os.environ['SPARK_HOME'] ='/Users/sherry/documents/spark/spark-3.2.1-bin-hadoop3.2'
spark=SparkSession.builder.appName('ml').getOrCreate()
#读取数据集和测试集
trainSet=spark.read.csv(r'/Users/sherry/Downloads/iris_training.csv',
schema='Feat1 FLOAT,Feat2 FLOAT,Feat3 FLOAT,Feat4 FLOAT,label INT')
testSet=spark.read.csv(r'/Users/sherry/Downloads/iris_test.csv',
schema='Feat1 FLOAT,Feat2 FLOAT,Feat3 FLOAT,Feat4 FLOAT,label INT')
vect_assemble=VectorAssembler(inputCols=['Feat1','Feat2','Feat3','Feat4'],
outputCol='features')
trainSet=vect_assemble.transform(trainSet)
testSet=vect_assemble.transform(testSet)
kmean=KMeans(featuresCol='features',
k=3)
kmean_Model=kmean.fit(trainSet)
trainSet=kmean_Model.transform(trainSet)
trainSet.select('label','prediction').show(5)
其结果如下:

3. Regression
3.1 概览
ml.Regression包中提供的回归算法及其类如下:
| 回归 | 相关类 |
|---|---|
| 加速失效时间模型 | AFTSurvivalRegression、AFTSurvivalRegressionModel |
| 决策树回归 | DecisionTreeRegressor、DecisionTreeRegressionModel |
| 梯度提升树回归 | GBTRegressor、GBTRegressionModel |
| 广义线性回归 | GeneralizedLinearRegression、GeneralizedLinearRegressionModel、GeneralizedLinearRegressionSummary、GeneralizedLinearRegressionTrainingSummary |
| 保序回归 | IsotonicRegression、IsotonicRegressionModel |
| 线性回归 | LinearRegression、LinearRegressionModel、LinearRegressionSummary、LinearRegressionTrainingSummary |
| 随机森林回归 | RandomForestRegressor、RandomForestRegressionModel |
| 因式分解回归 | FMRegressor、FMRegressionModel |