机器学习技法 Lecture5: Kernel Logistic Regression
1. Soft-Margin SVM as Regularized Model
总结一下之前讲的关于SVM的内容,主要是hard-margin和soft-margin两种类型,而两种类型各自也有对应的对偶问题与其解法。soft-margin的主要区别就是不一定要求数据是线性可分的,可以有一定的违反:

这个松弛变量
表示的是该点到分类正确的边的margin的距离,如右图:

而这个值可以用一个max的式子来表示:

因此目标函数可以该写为如下形式,这样写也就去掉了对于这个松弛变量的限制条件:

对于这个问题来说新的目标函数看起来比较熟悉,可以看作是类似于加了L2正则化项的分类问题:
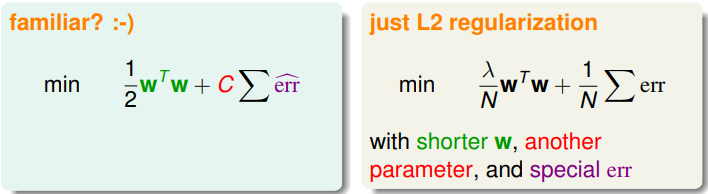
但是这个问题看起来还有些难解,因为问题并不是一个二次规划可解的问题,而且没有用上核方法。max函数也是一个不可微的函数。
对比一下SVM与正则化的模型,可以看出它们之间的练习与区别:
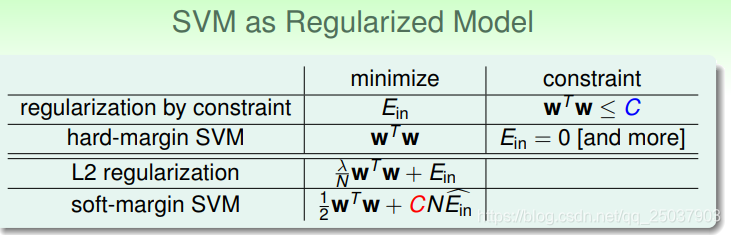
对于不同的目标追求在几个问题中是相通的,比如更大的margin等同于只能在比较少的分类平面选择,与使用L2正则得到的结果相似。

把SVM问题看做是一个带了正则化的模型可以将其与其它模型联系起来。
2. SVM versus Logistic Regression
我们把SVM看做是一个特殊的带正则化项的问题以后,就可以把max的那项看作是一个特殊的err。通过图示可以看出来,这个特殊的err是0/1 error的一个上界:

对于SVM的hinge error与逻辑回归的交叉熵 error,在ys趋近于正无穷与负无穷时,两个error的结果很接近,因此说明SVM与L2正则化的逻辑回归很接近。
对于二分类的三个线性模型现在可以进行一个对比:
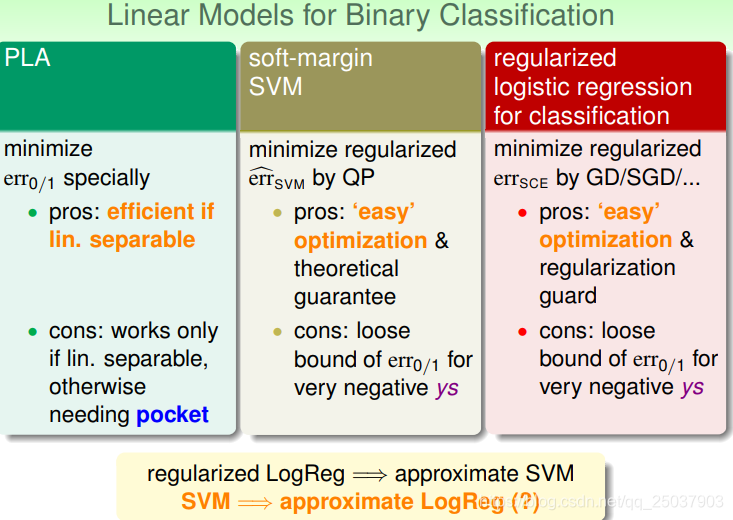
因此可以看出如果我们解了一个正则化的逻辑回归问题,那么就接近于解了一个soft-margin的问题。那么能否反过来应用,如果我们解了一个SVM问题,从而将其结果作为某个逻辑回归的结果呢?
3. SVM for Soft Binary Classification
对于以上疑问我们有两种比较初步的想法:一个是先运行SVM然后将得到的结果直接作为一个逻辑回归的系数,但这样就无法利用逻辑回归的优势。第二个是先运行SVM得到一个初步结果,然后将其作为逻辑回归的初始参数继续运行逻辑回归算法得到结果。但是这样就无法利用SVM的优势。

有一个简单的结合方式可以将这两种方法的优势都结合起来。那就是首先利用SVM得到一个结果,然后在得到的结果多项式外加一个放缩系数A和一个平移系数B,作为一个级联的学习方式。

这种方法叫做probabilistic SVM算法。得到的结果与SVM得到的结果略微有些差别。

这个算法实际上相当于将SVM得到的结果作为一个非线性映射,映射到Z空间之后在Z空间进行一次逻辑回归。
4. Kernel Logistic Regression
在使用核方法背后有一个关键因素,那就是我们的结果系数w能够表示为样本z的加权和。这样得到的结果才能够利用Kernel方法来减少计算。那么什么条件下线性分类的结果能够使用样本点表示呢?
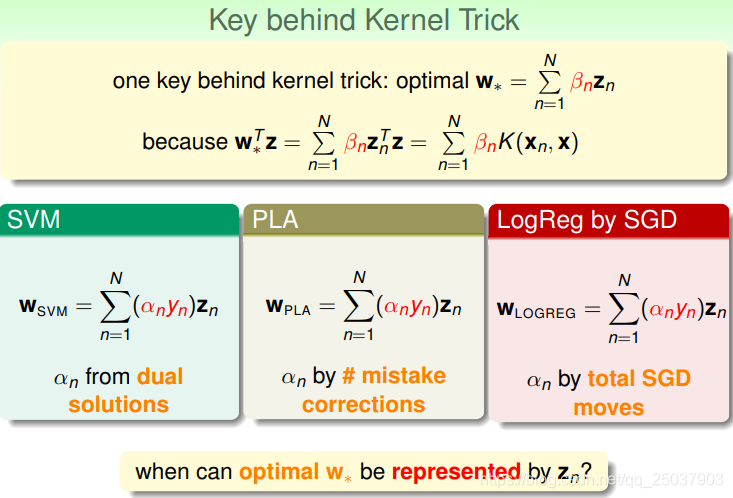
其实对于任意的使用L2正则化的线性模型都可以将结果的系数w表示为样本的加权和。

可以利用反证法来证明这一点,证明过程很简单:

这个证明也说明了一个重要的事实,那就是任何L2正则化的线性模型都能够使用核方法。
因此在求解这类模型的时候可以将系数先直接写为样本表示的形式然后使用核方法:

在这个直接带入使用核方法的逻辑回归方法里,目标函数写为如上述形式以后可以直接利用梯度下降或者随机梯度下降的方法得到最后的解果。
从另一个角度看,核方法逻辑回归算法可以看成是一个对于系数
的线性模型,因为对应有着核方法做映射与对应的正则化。但是也可以看成是系数w的线性模型,看作是将w表示为样本线性组合之后利用核方法加上L2正则化的一个线性模型。

不过在这个问题里,系数
大部分的结果都是非0值。