Logistic Regression Research
这篇文章旨在梳理一下逻辑回归,因为其简单、实用、高效,在业界应用十分广泛。注意咯,这里的“逻辑”是音译“逻辑斯蒂(logistic)”的缩写,并不是说这个算法具有怎样的逻辑性。
机器学习算法中的监督式学习(Supervised Learning)可以根据返回值是否既定可以分为分类(classification)和回归(Regression):
-
分类模型:目标变量是分类变量(离散值);
-
回归模型:目标变量是连续性数值变量。
逻辑回归虽名为“回归”但是解决的却是离散问题,也就是分类,例如预测肿瘤良性、电子邮件是否为欺诈邮件等。但是,“分类”是应用逻辑回归的目的和结果,但中间过程依旧是“回归”。
何出此言?因为通过逻辑回归模型。我们得到的计算结果是某件事情(不)发生的概率,值域为[0, 1]。然后,给这个概率加上了阈值,比如说0.5,则以上面的肿瘤为例,当肿瘤为良性的可能性大于等于0.5时,就可以将此肿瘤判别为良性肿瘤。
一、线性回归
1. 一般模型
考虑最简单的线性回归模型,也就是只有一个自变量。例如,广告投入金额 x 与 销售量 y 之间的联系,下面的散点图说明了x 与 y 之间的一元线性回归的关系。线性回归的相关概念:用人话讲明白线性回归LinearRegression
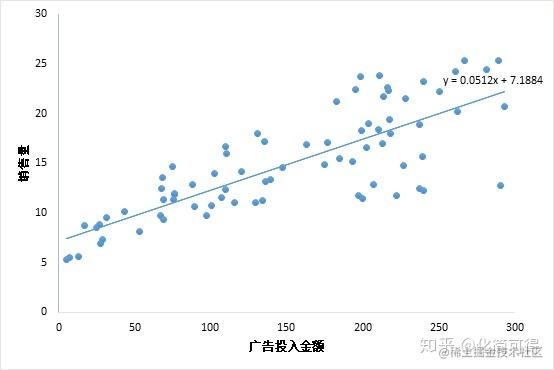 但是由于在实际问题中,因变量 y 是分类型,也就是只取 0、1 两个值,并非如上的对应关系(y可以取任意值)。
但是由于在实际问题中,因变量 y 是分类型,也就是只取 0、1 两个值,并非如上的对应关系(y可以取任意值)。
2.示例
假设我们有这样一组数据:给不同的用户投放不同金额的广告,记录他们购买广告商品的行为,1代表购买,0代表未购买,如下所示:
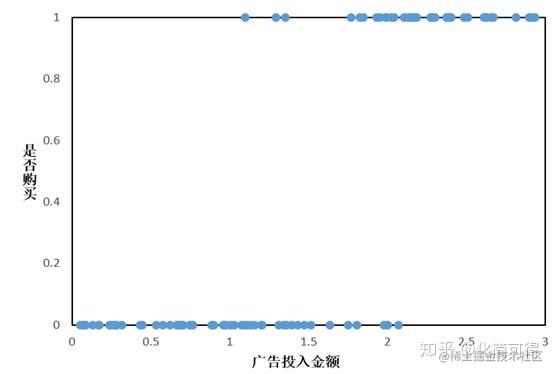
此时仍考虑线性回归模型,则会拟合出一条直线:
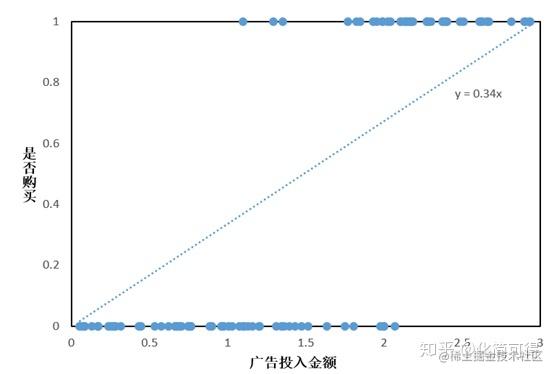
可以看出,没有只有极少数点落在了直线上,看起来各散点和直线并没有什么关系。但是我们可以在输出 y 的结果后可以加一个阈值限制,也即是取中值 0.5.当输出的 y > 0.5时,则就认为其是属于 1 这一分类,也就是会购买商品,反之则不会购买。
y={1,f(x)>0.50,f(x)≤0.5
因为解出的拟合方程为
y=0.34x,那么就可以通过代入y的阈值0.5,反解出x的阈值1.47,从而将上面的分段函数等价为:
y={1,x>1.470,x≤1.47 ,这种形式和单位阶跃函数非常相似:
y=⎩⎪⎨⎪⎧1,z>00.5,z=00,z<0 ,图像如下:
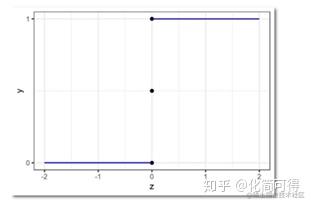
我们发现,把阶跃函数向右平移一下,就可以比较好地拟合上面的散点图呀!但是阶跃函数有个问题,它不是连续函数。非连续函数不便于拟合,所以理想的情况,是像线性回归的函数一样,X和Y之间的关系,是用一个单调可导的函数来描述的。下面我们就引入处理函数来解决:
二、sigmond函数
实际上,我们使用Logistic Regression算法时,常用的拟合函数是sigmoid函数,函数表达式为:
f(z)=1+e−z1。图像如下:
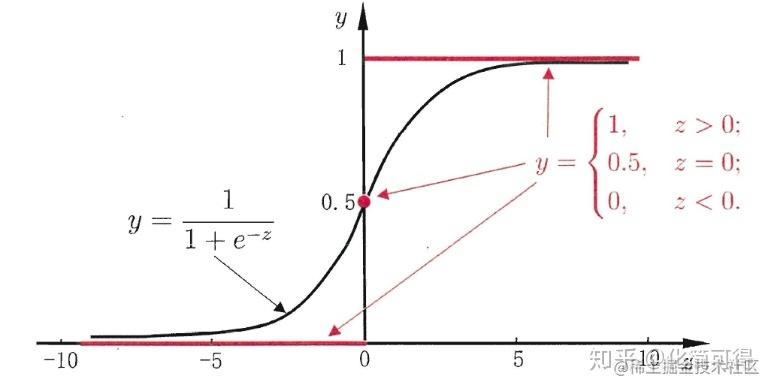 sigmoid函数是一个s形曲线,就像是阶跃函数的温和版,阶跃函数在0和1之间是突然的起跳,而sigmoid有个平滑的过渡。
sigmoid函数是一个s形曲线,就像是阶跃函数的温和版,阶跃函数在0和1之间是突然的起跳,而sigmoid有个平滑的过渡。
从图形上看,sigmoid曲线就像是被掰弯捋平后的线性回归直线,将取值范围(−∞,+∞)映射到(0,1) 之间,更适宜表示预测的概率,即事件发生的“可能性”
三、推广至多元回归
1. 多元线性回归方程
-
一般形式:
y=θ0+θ1x1+θ2x2+⋯+θpxp
可以简写为矩阵形式:
Y=Xθ
-
迭代方式:求导,利用所有数据集来更新
θ
2. 多元Logistic Regression
-
一般形式,直接将sigmoid函数的自变量修改为多元线性回归的方程即可。
f(Xθ)=1+e−Xθ1=P(Y=1)
因为Logistic Regression 的核心思想就是利用线性回归解出的值来进行分类。
-
到目前为止,逻辑函数的构造算是完成了。找到了合适的函数,下面就是求函数中的未知参数向量
θ了。求解之前,我们需要先理解一个概念——似然性
四、似然函数
我们常常用概率(Probability) 来描述一个事件发生的可能性。
而似然性(Likelihood) 正好反过来,意思是一个事件实际已经发生了,反推在什么参数条件下,这个事件发生的概率最大。
用数学公式来表达上述意思,就是:
- 已知参数
θ 前提下,预测某事件 x 发生的条件概率为
P(x∣θ) ;
- 已知某个已发生的事件 x,未知参数
θ 的似然函数为
L(θ∣x);
- 上面两个值相等,即:
P(x∣θ) =
L(θ∣x)。
一个参数
θ 对应一个似然函数的值,当
θ 发生变化,
L(θ∣x)也会随之变化。当我们在取得某个参数的时候,似然函数的值到达了最大值,说明在这个参数下最有可能发生x事件,即这个参数最合理。
因此,最优
θ,就是使当前观察到的数据出现的可能性最大的
θ。
五、最大似然估计
1. 基本公式
在二分类问题中,y只取0或1,可以组合起来表示y的概率:
P(y)=P(y=1)y∗P(y=0)1−y
上面的式子,更严谨的写法需要加上特征x和参数
θ:
P(y∣(x,θ))=P(y=1∣(x,θ))y∗P(y=0∣(x,θ))1−y
前面说了,
1+e−Xθ1=P(Y=1)表示的就是P(y=1),代入上式:
P(y∣x,θ)=(1+e−xθ1)y(1−1+e−xθ1)1−y
根据上一小节说的最优的定义,也就是最大化我们见到的样本数据的概率,即求下式的最大值。
L(θ)=∏i=1nP(yi∣xi,θ)=∏i=1n(1+e−xiθ1)yi(1−1+e−xiθ1)1−yi
这个式子怎么来的呢?其实很简单。
2. 推导过程
前面我们说了,
P(x∣θ) =
L(θ∣x),对于某个观测值
yi,似然函数的值
L(θ∣yi)就等于条件概率的值
P(yi∣θ) 。
另外我们知道,如果事件A与事件B相互独立,那么两者同时发生的概率为P(A)*P(B)。那么我们观测到的
y1,y2,y3,…,yn,他们同时发生的概率就是。
∏i=1nP(yi∣xi,θ)
因为一系列的
xi和
yi都是我们实际观测到的数据(或者是我们收集到的数据集),式子中未知的只有
θ。因此,现在问题就变成了求
θ在取什么值的时候,L(
θ)能达到最大值。
L(
θ)是所有观测到的y发生概率的乘积,这种情况求最大值比较麻烦,一般我们会先取对数,将乘积转化成加法。
取对数后,转化成下式:
logL(θ)=∑i=1n([yi⋅log(1+e−xiθ1)]+[(1−yi)⋅log(1−1+e−xiθ1)])
接下来想办法求上式的最大值就可以了,求解前,我们要提一下逻辑回归的损失函数。
六、损失函数
在机器学习领域,总是避免不了谈论损失函数这一概念。损失函数是用于衡量预测值与实际值的偏离程度,即模型预测的错误程度。也就是说,这个值越小,认为模型效果越好,举个极端例子,如果预测完全精确,则损失函数值为0。
1. 线性回归损失函数
在线性回归一文中,我们用到的损失函数是残差平方和SSE:
Q=∑1n(yi−y^i)2=∑1n(yi−xiθ)2
这是个凸函数,有全局最优解。
2. 逻辑回归损失函数
如果逻辑回归也用平方损失,那么就是:
Q=∑1n(yi−1+e−xiθ1)2
很遗憾,这个不是凸函数,不易优化,容易陷入局部最小值,所以逻辑函数用的是别的形式的函数作为损失函数,叫对数损失函数(log loss function)。
这个对数损失,就是上一小节的似然函数取对数后,再取相反数哟:
J(θ)=−logL(θ)=−∑i=1n[yilogP(yi)+(1−yi)log(1−P(yi))]
3. 示例
用文章开头那个例子,假设我们有一组样本,建立了一个逻辑回归模型P(y=1)=f(x),其中一个样本A是这样的:
公司花了x=1000元做广告定向投放,某个用户看到广告后购买了,此时实际的y=1,f(x=1000)算出来是0.6,这里有-0.4的偏差,是吗?在逻辑回归中不是用差值计算偏差哦,用的是对数损失,所以它的偏差定义为log0.6(其实也很好理解为什么取对数,因为我们算的是P(y=1),如果算出来的预测值正好等于1,那么log1=0,偏差为0)。
样本B:x=500,y=0,f(x=500)=0.3,偏差为log(1-0.3)=log0.7。
根据log函数的特性,自变量取值在[0,1]间,log出来是负值,而损失一般用正值表示,所以要取个相反数。因此计算A和B的总损失,就是:-log0.6-log0.7。
之前我们在用人话讲明白梯度下降中解释过梯度下降算法,下面我们就用梯度下降法求损失函数的最小值(也可以用梯度上升算法求似然函数的最大值,这两是等价的)。
七、梯度下降法求解
1. 逻辑回归假设函数对x求导
要开始头疼的公式推导部分了,不要害怕哦,我们还是从最简单的地方开始,非常容易看懂。
首先看,对于sigmoid函数
f(z)=1+e−z1,f'(x)等于多少?
如果你还记得导数表中这2个公式,那就好办了(不记得也没关系,这就给你列出来):
(x1)′=−x21(ex)′=ex
根据上两个公式,推导:
f′(x)=(1+e−x1)′=−(1+e−x)2(e−x)′=(1+e−x)2e−x
到这还不算完哦,我们发现
1−f(x)=1+e−xe−x ,而
f′(x) 正好可以拆分为
1+e−xe−x⋅1+e−x1, 也就是说:
f′(x)=f(x)⋅(1−f(x))
当然,现在我们的 x 是已知的,末知的是
θ ,所以后面是对
θ求导,记:
1+e−xiθ1=f(xiθ)
2. 简化损失函数表示并对
θ求导
将
1+e−xiθ1=f(xiθ)代入前面的损失函数得:
J(θ)=−∑i=1n[yilog(f(xiθ))+(1−yi)log(1−f(xiθ))]=−∑i=1ng(θi,xi,yi)
简便起见,先不看求和号,看
g(θ,x,y) 。不过这个
g(θ,x,y) 里面也挺复杂的,我们再把里面的
f(xiθ) 挑出来,单独先看它对
θ向量中的某个
θj求偏导是什么样。
根据上面的求导公式,有:
∂θj∂f(xiθ)=f(xiθ)⋅(1−f(xiθ))⋅xij
Y=⎣⎢⎢⎢⎡y1y2…ym⎦⎥⎥⎥⎤,X=⎣⎢⎢⎢⎡11…1x11x21…xm1………x1nx2n…xmn⎦⎥⎥⎥⎤,θ=⎣⎢⎢⎢⎡θ0θ1…θn⎦⎥⎥⎥⎤
注意咯,这个
xi实际上指的是第 i 个样本的特征向量,即
(1,xi1,…,xip) ,其中只有
xij会和
θj相乘,因此求导后整个
xi只剩
xij了。
理解了前面说的,下面的化简就轻而易举:
∂θj∂g(θi,xi,yi)=yif(xiθ)1∂θj∂f(xiθ)−(1−yi)1−f(xiθ)1∂θj∂f(xiθ)=(f(xiθ)yi−1−f(xiθ)1−yi)⋅∂θj∂f(xiθ)=(f(xiθ)yi−1−f(xiθ)1−yi)⋅f(xiθ)⋅(1−f(xiθ))⋅xij=[yi(1−f(xiθ))−(1−yi)f(xiθ)]⋅xij=(yi−f(xiθ))⋅xij
加上求和号:
∂θj∂J(θ)=−∑i=1n(yi−f(xiθ))⋅xij=∑i=1n(1+e−xiθ1−yi)⋅xij
有了偏导,也就有了梯度G,即偏导函数组成的向量。
3. 梯度下降算法过程:
-
初始化β向量的值,即
Θ0,将其代入G得到当前位置的梯度;
-
用步长α乘以当前梯度,得到从当前位置下降的距离;
-
更新
Θ1 ,其更新表达式为
Θ1=Θ1−αG;
-
重复以上步骤,直到更新到某个
Θk,达到停止条件,这个
Θk 就是我们求解的参数向量。
本文转载自知乎用户化简可得 - 知乎 (zhihu.com)的文章用人话讲明白逻辑回归Logistic regression - 知乎 (zhihu.com)。