ML Lecture 6: Brief Introduction of Deep Learning
深度学习简介

上图是谷歌的杰佛瑞·艾德盖尔·迪恩(Jeffrey Adgate Dean)在SIGMOD会议(Special Interest Group On Management Of Data)作演讲时的幻灯片,它体现了这样一种趋势:从2012年第一季度到2016年第一季度,谷歌内部涉及深度学习的项目数量:从几乎为 到超过 个,呈指数增长。此外,深度学习的应用涵盖各个领域:Android、Apps等。
深度学习的发展历程
深度学习在历史上经过几次沉浮:

1958年,
Perceptron(感知机)技术被提出,它与之前讲的Logistic回归十分相似,只是没有经过Sigmoid函数,感知机也是一个线性模型。
当心理学家弗兰克·罗森布拉特(Frank Rosenblatt)在一个海军项目中首次提出感知机的设想时,许多学者都跃跃欲试。《纽约时报》甚至报导“从此以后人工智慧即将产生,计算机将能够自己学习”,而当时运行感知机需要一台相当庞大的机器。1969年,MIT人工智能实验室的创始人Marvin Minsky和Seymour Paper发表了一本名为《Perceptron》的书,表达了对过度夸大感知机作用的质疑,书中严谨分析了感知机作为一个线性模型,其实具有非常大的局限性。此后,感知机迅速没落。
单层感知机没落后,有人提出
多层感知机(Multi-layer Perceptron),这个想法正如上一节最后一部分试图将多个Logistic回归拼接在一起、解决非线性分类问题一样。
到20世纪80年代,多层感知机技术已经基本成熟。那个阶段的多层感知机的发展,就相当于今时今日深度学习的发展程度。此后的关键技术出现在1986年,杰弗里·埃弗里斯特·辛顿(Geoffrey Everest Hinton)提出了
反向传播(Backpropagation)算法,事实上Hinton并非发现BP算法的第一人,但其在1986年发表的论文《Learning representations by back-propagating errors》观点陈述精确清晰,而显得尤为突出。
当时这个方法的问题在于,通常超过三层的神经网络就无法训练出好的结果(一层的效果还可以,层数再多就无法保证训练效果)。1989年,有人发现:其实一个神经网络只需要一个隐藏层,就可以模拟出任何可能的函数,单隐藏层的神经网络已经足够强,没有必要再叠加多个隐藏层,因此多层感知机(也就是神经网络NN)的方法又再次没落了,人们转而使用SVM。
直至2006年,Hinton提出另一个突破点:用
受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)寻找初始化参数。有人认为,20世纪80年代的多层感知机与深度学习之间的区别就在于:用梯度下降法求解参数时,需要选择初始参数。如果使用RBM做参数初始化,就属于深度学习;如果直接自定义或随机初始化参数,就属于传统的多层感知机。
然而RBM方法异常复杂,对于机器学习的初学者,光看文献是无法理解的。它用到了一些比较深的理论,而且它不是基于神经网络(Neural Network-Based)的,而是一个图模型(Graphical Model)。现在深度学习的文献中已经比较少人用RBM做初始化,因为人们发现RBM并没有带来很大的帮助,Hinton自己也熟知这点(甚至在某篇文献中提到过)。但RBM最大的贡献就在于,让人们重拾对神经网络模型的兴趣,它被谷歌评价是“石头汤”里的“石头”,起到抛砖引玉的作用。深度学习的又一个转折点是2009年人们发现可以使用GPU来加速,这一发现推动了深度学习的发展。因为过去做深度学习,训练一次的时间需要一天、一周甚至更久,极大地降低研究热情。有了GPU后,本来需要一周的训练时间,现在可能只需要几个小时就能完成。
2011年,深度学习被引入语音识别领域,效果甚好,引起许多人的关注和研究。
2012年,深度学习技术在ILSVRC图像识别比赛中获胜,深度学习也因此在图像识别领域流行起来。
深度学习的三个步骤
与机器学习的过程相同,深度学习也具备三个步骤:定义模型/函数集
判断函数的优劣
选择最佳函数/参数。
这个过程如同把大象塞进冰箱一样一气呵成:开冰箱门
塞大象
关冰箱门。

1. 定义模型/函数集
我们所要定义的模型/函数集实际上就是一个神经网络。

前面提到,把不同的Logistic回归前后连接起来,其中每一个Logistic回归又称为神经元(Neuron),许多个神经元串接在一起所形成的整体就称为神经网络(Neural Network,NN)。采用不同的方法连接这些神经元,就得到了不同的神经网络结构。
在一个神经网络中,包含有许多个Logistic回归/神经元,每个Logistic回归/神经元都有自己的权重
和偏置
。所有的
和
集合起来就构成了这个神经网络的参数集
。

【神经网络的连接方式】
神经元可以通过各种不同的方式相互连接,具体如何连接是需要手动设计的。当人类决定了神经网络的连接方式后,机器就可以自己根据训练资料找出每个神经元的参数。
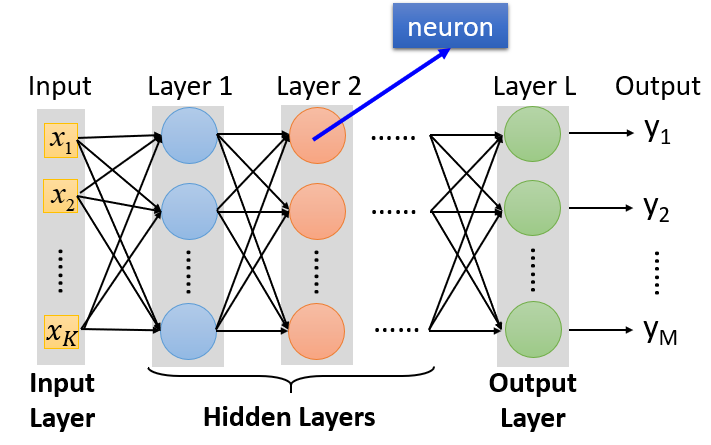
最常见的连接方式是完全连接前馈式网络(Fully Connected Feedforward Network)。在这种架构中,神经元排成一列一列,每列称为一层(Layer)。每层神经元的输出是下一层各神经元的输入,最后一层称为输出层(Output Layer),其他层则称为隐藏层(Hidden Layer)。
下图共有
个神经元,包括
个输入层,
个隐藏层,
个输出层。每个神经元都对应一组参数
,这组参数是根据训练集找出来的。
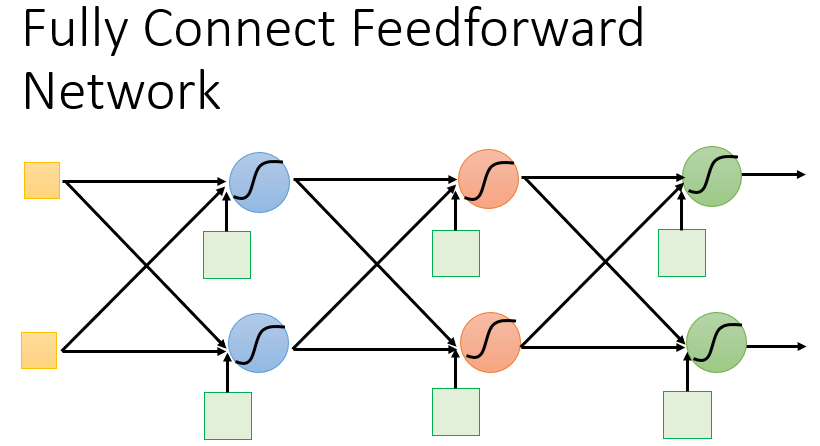
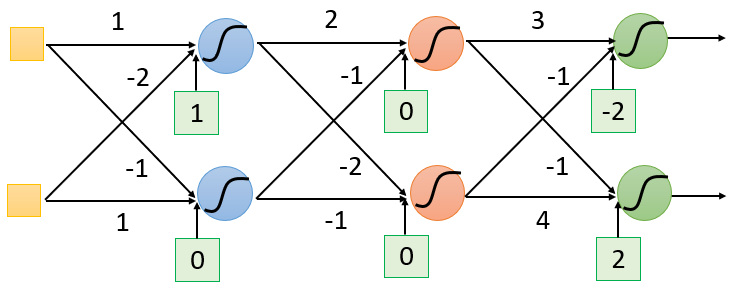
假设这个完全连接前馈式神经网络中,每个神经元的参数如下:
- 第 个隐藏层的两个神经元参数分别为 ,
- 第 个隐藏层的两个神经元参数分别为 ,
- 输出层的两个神经元参数分别为
,
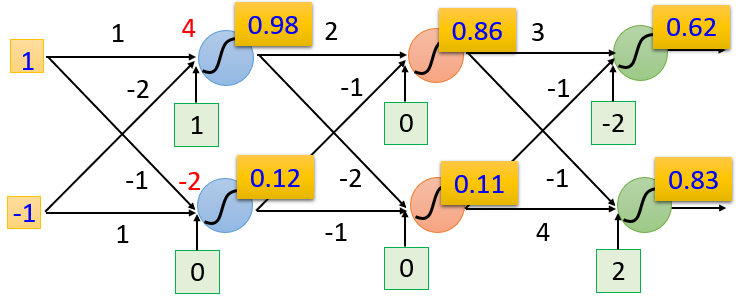
当输入层的值为 时,这个神经网络里经过一系列的计算:
第 个隐藏层的两个神经元输出
第 个隐藏层的两个神经元输出
输出层的两个神经元输出
同理,当输入层的值为 时,这个神经网络里经过一系列的计算:
第 个隐藏层的两个神经元输出
第 个隐藏层的两个神经元输出
输出层的两个神经元输出
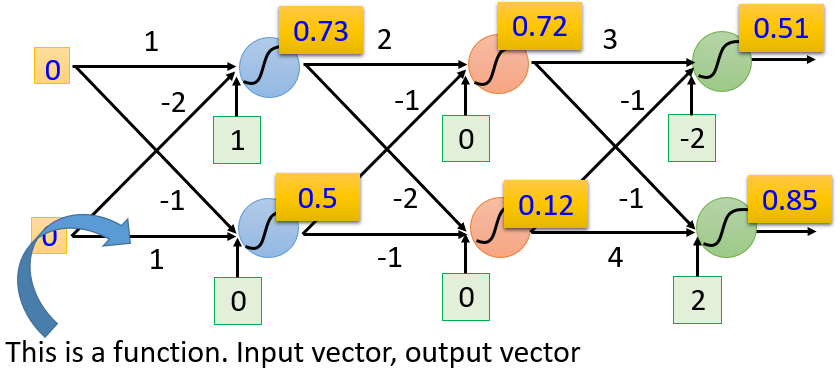
所以,当一个神经网络里的一系列参数都已知时,就构成了一个函数。这个函数的输入是一个向量,输出是另外一个向量。上面的例子可以表示为:
当我们只是界定了神经网络内部如何连接,而其中的各个参数未知时,这个神经网络就是一个模型/函数集。设置不同的参数,就会得到不同的函数。设计神经网络的架构实际上就是决定了一个模型/函数集。这与之前做Logistic回归和线性回归的过程类似,都要先确定一个模型/函数集。但与Logistic回归、线性回归模型不同的是,当以一个神经网络作为模型时,其所涵盖的函数范围是比较大的,其中包含了Logistic回归、线性回归无法涵盖到的许多函数。

下图推广到含有多个隐藏层的完全连接前馈式网络:
- 第一列是Input Layer(黄):
,是一个
维向量,代表样本
共有
维特征
严格来说Input Layer不算一个层,因为它不是由神经元组成的,但为了叫法一致,也称之为“层”
Input Layer里的每一维元素 ,…, ,会全部输入到每一个蓝色神经元中(第 个Hidden Layer的神经元) - 最后一列(第 层)是Output Layer(绿),通过绿色的神经元,计算得到一个 维向量 ,代表一共输入 个类别
- Input Layer与Output Layer之间的每一列,称为Hidden Layer(蓝、红…)
各Hidden Layer内,每一个圆圈代表一个神经元,神经元的数量没有限制,可以是 、 个…
各Hidden Layer之间,上一层内每一个神经元的输出,会传递给下一层内每一个神经元,即上一层的输出会全部输入下一层。由于层与层之间,所有的神经元两两之间相互连接,所以称为完全连接(Fully Connected);由于传递方向是从前往后, ,所以称为前馈式(Feedforward)。
所谓深度学习的“深”,意味着有很多的隐藏层(至于要多少隐藏层才足以称之为“深”就见仁见智了)。下面是近几年来较为突出的一些模型:
- 2012年参加ImageNet的冠军模型AlexNet,其深度是 层,top-5错误率 %,远优于第二名的 %
- 2014年,VGG Net 以 %的失误率取得了当年ILSVRC的“分类及定位”比赛的单项冠军,这一模型含有 个层
- 2014年,GoogLeNet的模型以 %的失误率取得了当年ILSVRC的冠军,该模型含有 个层

- 2015年,Microsoft ResNet 以
%的失误率取得了当年ILSVRC的冠军,这一模型是有着
个层的“超深度”网络架构。在2015年图像识别任务中,除了要辨别出图片是猫还是狗,还要求判别猫、狗的种类。据了解,普通人的失误率大约为
%,而Residual Net的准确度已经超过了人类水平。
Residual Net的内部结构并不是一般的完全连接前馈式网络,如果用完全连接前馈式网络是会有问题的,问题不是出在过拟合,而是根本无法进行训练。因此需要设计特别的结构,才能搞定这么深的神经网络。

【神经网络的运作方式】
神经网络的运作方式通常用矩阵运算(Matrix Operation)来表示。
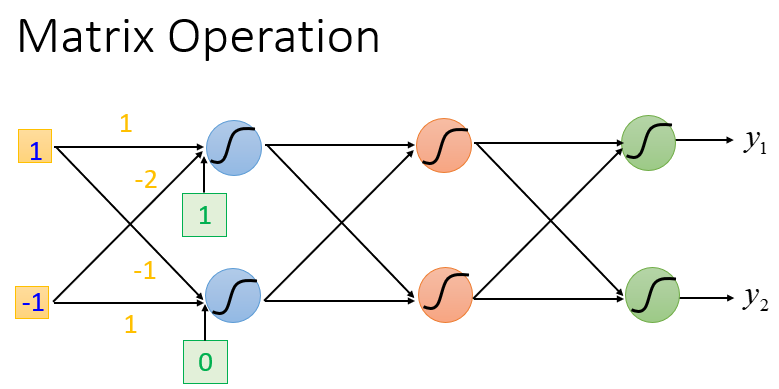
以第 个隐藏层的两个神经元参数为例,它们可以表示为矩阵 ,
则当输入层的值为
时,经过第
个隐藏层的计算可以化为矩阵操作:
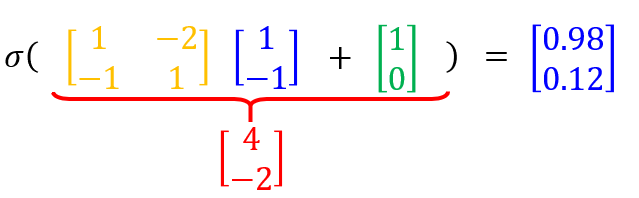
在神经网络的文献中,把
这样的函数称为激活函数(Activation Function)。激活函数不一定非要是Sigmoid函数(只不过前面章节的例子全部以Sigmoid函数作为激活函数)。Sigmoid函数是从Logistic回归发展过来的激活函数,事实上现在已经比较少用Sigmoid函数作激活函数。
推广到含有多个隐藏层的完全连接前馈式网络,则每一层的参数分别表示为
。其中,
都是矩阵,
都是列向量。
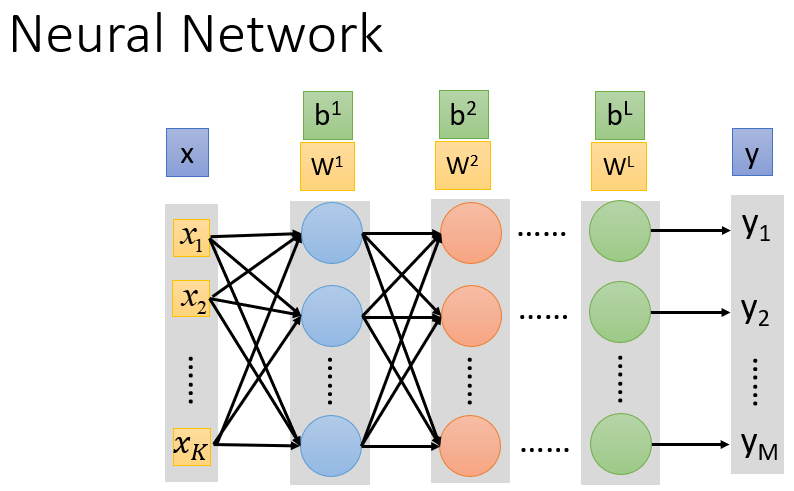
从输入层的样本 到输出层的分类结果 ,其过程可以视为:
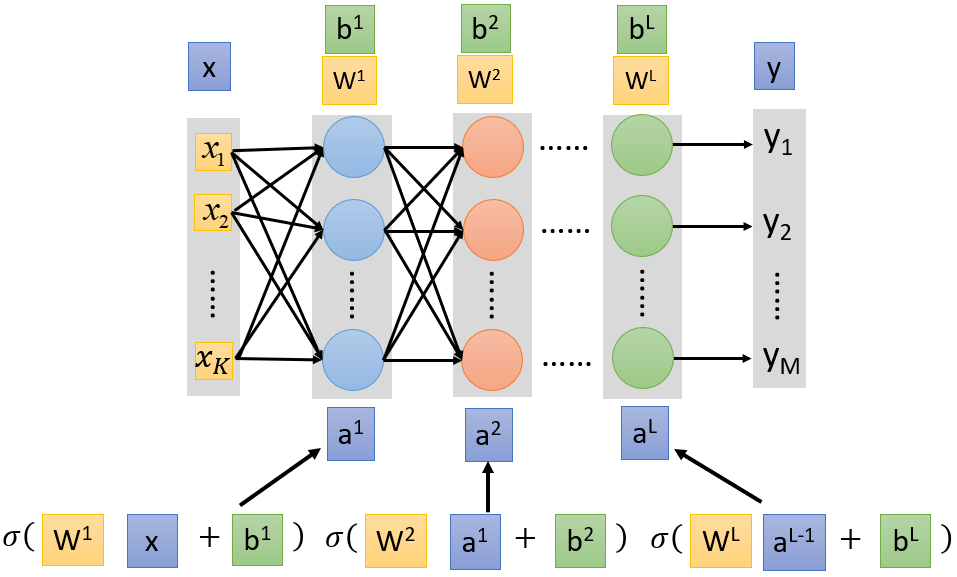
因此,整个神经网络的运算其实就是一连串的矩阵运算。转换成矩阵运算的好处就在于,计算过程中可以利用GPU加速,通过并行计算提高效率。GPU并不是对神经网络做了什么优化,而只是从硬件上提升了计算性能。每次需要做矩阵运算才调用GPU,这会比使用CPU更快。因此,通常把神经网络的式子表示成矩阵形式。
【神经网络的内部结构】
至此,我们知道神经网络由输入层、隐藏层、输出层构成。事实上,输出层之前的全部隐藏层所进行的工作,可以看做是一个特征提取的过程。这相当于之前处理异或问题时,我们手动进行了特征转换(Feature Transformation),使样本变得线性可分,能够用Logistic回归进行分类。
而在神经网络中,输入一个样本
,通过许多个隐藏层后,最后一个隐藏层的输出为
,它可以视为一组新的特征,是经过多重转化后,更方便模型进行分类的新特征(Separable Feature)。
最后,输出层起到一个多分类器的作用,它的输入值是经过多个隐藏层之后抽取出来的、新的样本特征
,在输出层中一般是对这组特征做Softmax。

【神经网络应用实例】
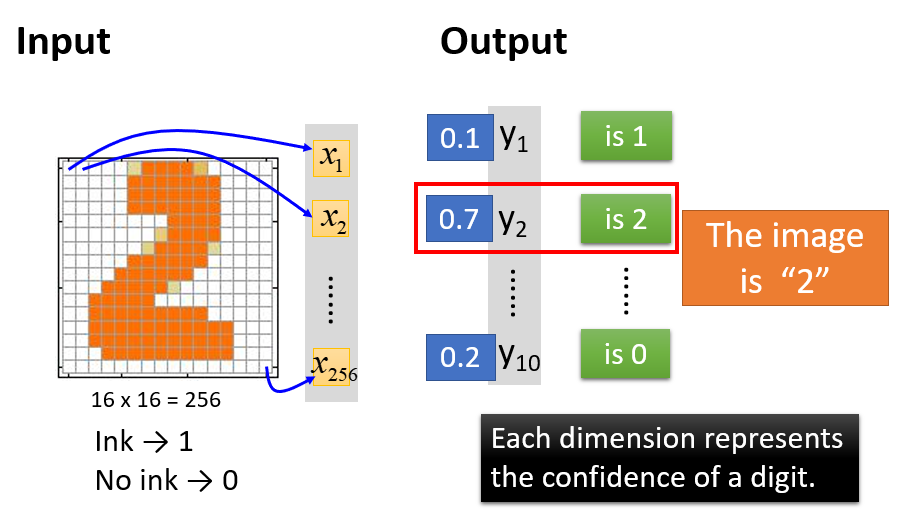
以图像识别为例,输入一张手写数字
的图片,希望模型能够准确输出这个手写数字对应的阿拉伯数字是
。对机器而言,一张图片就是一个向量。

假设这张图片的分辨率/解析度是
,那么这张图片就有
个像素(Pixel)。对机器而言:
- Input:输入这张图片,就相当于输入一个 维的向量。图片里每一个像素格都对应于向量的其中一维,我们可以定义:涂黑的像素格是 ,未涂黑的像素格是
- Output:如果输出层使用的是Softmax函数,那么机器输出的是一个概率分布。它是一个
维的向量
,向量中的各元素分别代表图片数字是
的概率。
假如 , ,…, ,则说明图片中的数字是 的概率为 ,是 的概率为 ,故图片中的数字最有可能是
在这个手写数字辨识问题中,唯一需要的就是一个函数:使得其输入是一个
维的向量,输出是一个
维的向量。这个函数就是神经网络。
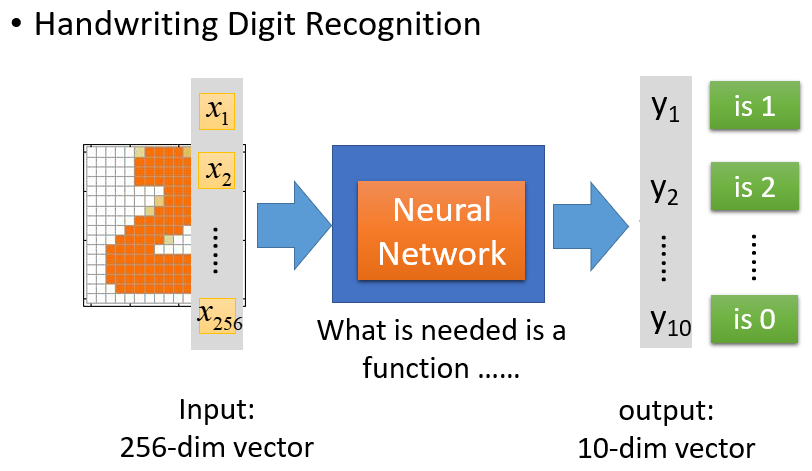
假设选择一个前馈式的神经网络:定义了神经网络的结构,就相当于定义了一个模型/函数集。这个模型中有许多函数,它们都可以用来辨识手写数字,但是不同的函数辨识效果有优劣之分。所以,接下来需要做的就是用梯度下降去寻找一组最佳参数/一个最佳函数,用这个函数解决手写数字的辨识问题。
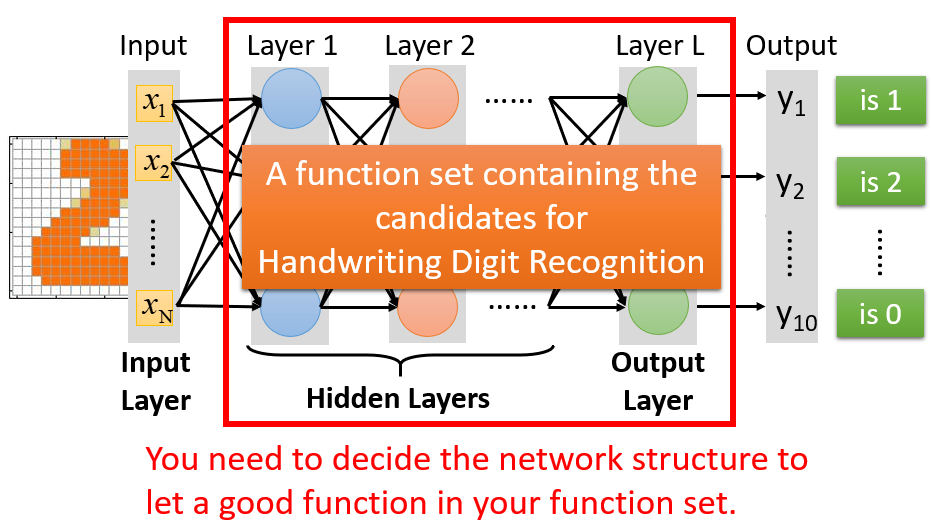
在线性回归、Logistic回归中,模型的结构通常不需要特别设计。而定义一个神经网络模型来解决上述图片辨识问题,除了要求输入是一个 维的向量、输出是一个 维的向量,还需要做一些额外的设计:定义中间需要多少个隐藏层,定义每个隐藏层设置多少个神经元。
这种结构的设计需要人类在机器学习前事先决定。如果结构设定不当,由此结构所定义的函数根本找不到好的函数,接下来再怎么努力都是徒劳。这就好比想要在大海捞针,结果针根本不在海里。所以,决定一个好的神经网络结构,才能决定一个好模型,这是十分关键的。
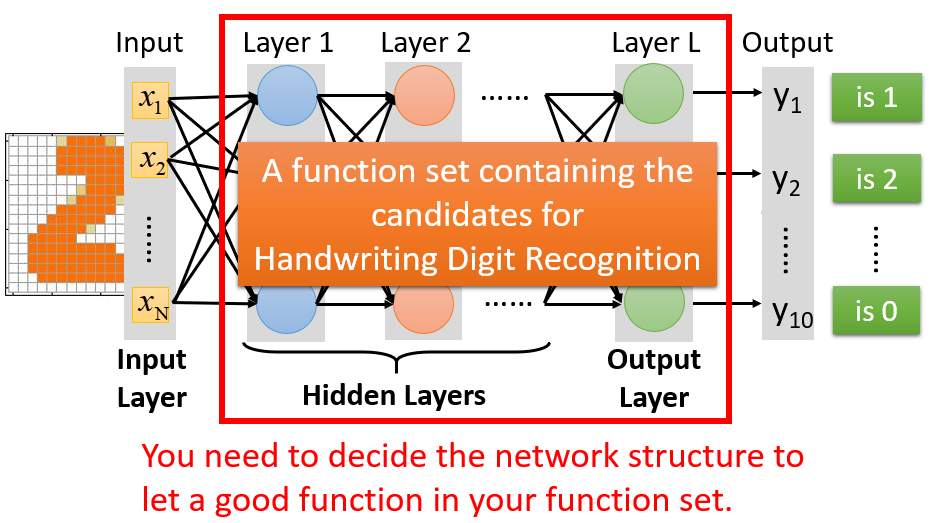
【神经网络的结构确定】
如何确定隐藏层的层数、设置多少个神经元,没有放之四海而皆准的设定,只能通过经验直觉以及多方的尝试,找到一个好模型有时候并不容易,可能需要一些领域知识。所以从非深度学习到深度学习,机器学习可能并没有变得比较简单,我们只是把一个问题转化为另一个问题。对于非深度模型来说,为了得到好的结果,往往需要进行特征工程/特征转换,找到一组好的特征。而在深度模型里,通常不需要去寻找一个好的特征,例如过去做影像辨识,需要先对pixel抽一些人为设定的特征(即Feature Transform),才能进行判别。而现在用深度学习做影像辨识,可以直接把pixel丢进去强行判别,但深度学习也制造了一个新的问题:人类需要事先设计神经网络的结构,问题从原来“如何抽取特征、抽取什么特征”转变成了“如何设计神经网络的结构”。
深度学习方法是否更有效,取决于实际要解决的问题。例如对于语音、影像辨识问题,设计神经网络结构要比传统的特征抽取更容易。因为,虽然人类也具有听和看的能力,但这些能力太过于潜意识,由于天生就会看、会听,所以人类并不能直觉地意识到自己是如何进行听和看的。对人类而言,抽取一组好的特征,使得机器能利用线性方法做语音辨识并不是一件简单的事,因为在这些问题上我们自己也无法判断什么才是好的特征。所以还不如设计一个神经网络结构,或是尝试各种神经网络结构,让机器自己去找出好的特征,问题反而更容易解决。
至于深度学习在其他领域的应用,就要视具体情况而言。例如深度学习用来解决NLP问题时,其表现不如解决语音辨识、影像辨识问题那么给力。语音、影像辨识是最早开始使用深度学习方法的,最初使用时,判别错误率大大降低,性能提升惊人。而在NLP领域,深度学习方法也带来了一定提升,但并不是特别喜人。原因可能是,在文字处理方面人类是比较强的,例如由人来设计规则判断一篇文章是正面还是负面情绪,那么人类可以列出关于正/负面情绪的词汇,然后比较文档中正负面词汇各占的比重,这种方法已经能得到不错的结果。所以针对NLP任务,由人来设定一些
先验规则(Ahead Rule)对解决问题比较有帮助,这也是为什么处理NLP任务时,深度学习相较于传统学习方法虽有提升,但不如语音、图像识别领域的提升那么显著。事实上,文字处理也是比较困难的问题,其中有许多潜在信息是人类自己也意识不到的。长久而言,深度学习这种由机器自己寻找特征的学习模式还是占有一定优势,只是眼下看来优势还不太显著。神经网络的结构是可以由机器自动决定的。例如在
遗传算法(Genetic Algorithm)中,有许多技术可以让机器自动找出神经网络的结构。但这些算法目前还没有十分普及,目前流行的AlphaGo等也不是基于这些算法做出来的。神经网络的结构不一定是完全连接式的,可以自行设计,其中一个特殊的连接方法就是
卷积神经网络(Convolutional Neural Network,CNN)。
2. 判断函数的优劣

判断函数的优劣需要定义一个损失函数,即前面提到的交叉熵损失函数。对于一个神经网络(模型),假如给定一组参数,就确定了一个具体的函数。用这一函数解决手写数字的图像识别问题:对于一张真实label为 的图片,目标概率分布应该是 。而神经网络函数的输出结果是一个 维向量 。则关于这张图片样本, 与 的交叉熵为:
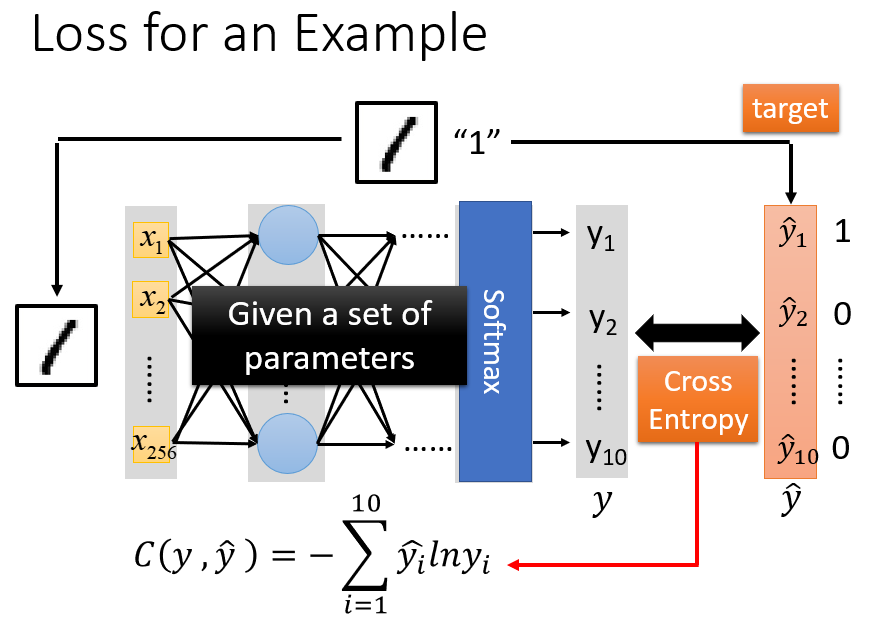
实际训练数据是由许多张图片样本组成的。对于第
个样本
,其交叉熵记为
,则对于共有
个样本的训练集,损失函数
定义为所有样本的交叉熵:
。我们的任务就是调整神经网络模型的参数,使得损失函数越小越好。

3. 选择最佳函数/参数

寻找最佳函数/参数同样是通过梯度下降法。在深度学习里使用梯度下降法,与线性回归中使用梯度下降法是没有区别的。只是在深度学习处理的任务中,函数变得复杂许多,参数个数增多,其实寻找参数的过程都是一样的。
即,对于参数集
,随机寻找一系列初始值,计算梯度——损失函数对每一个参数的偏导数
,并按照学习率
不断更新参数。

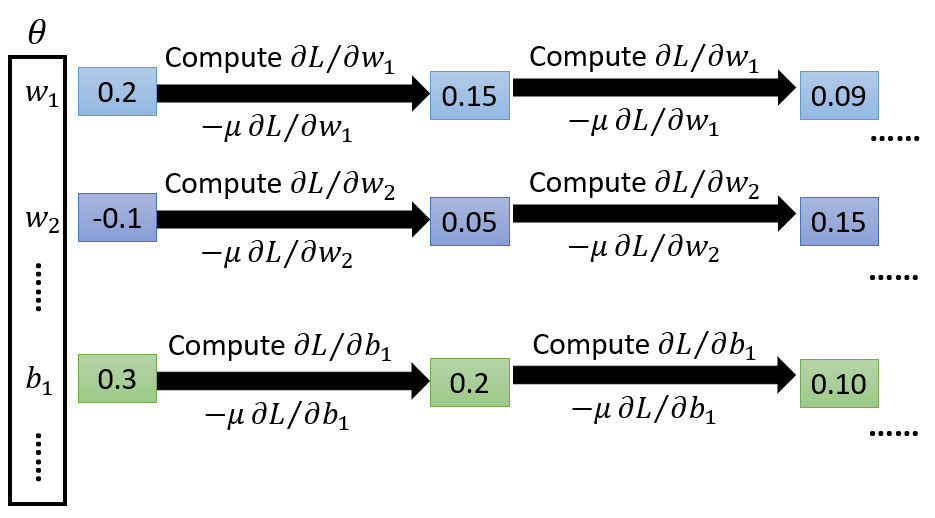
即使是目前最引人注目的AlphaGo,也是用梯度下降法训练参数的。

深度学习的框架
在之前的Regression - Demo中,用Python实现了梯度下降法求解最优参数
和
。当时使用的是线性模型,比较简单,偏导数可以手动计算。而神经网络的函数比较复杂,难以手动计算。早先做深度学习时,还需要自己代码实现反向传播算法(Backpropagation),而现在已经有许多框架可以辅助我们实现反向传播(由于待求参数有很多个,呈百万级别,无法为每个参数都计算偏导数,而反向传播是计算这些复杂偏导数的一种有效方式)。

为什么要深度学习

从直觉上来看,神经网络的深度越“深”,模型性能就越好。2011年Interspeech会议的一篇论文提到一个实验:
个隐藏层
每个隐藏层
k个神经元的情况下误差为
%
…
个隐藏层
每个隐藏层
k个神经元的情况下误差为
%
不出意料地,随着隐藏层数增多,模型变复杂,误差率会下降。
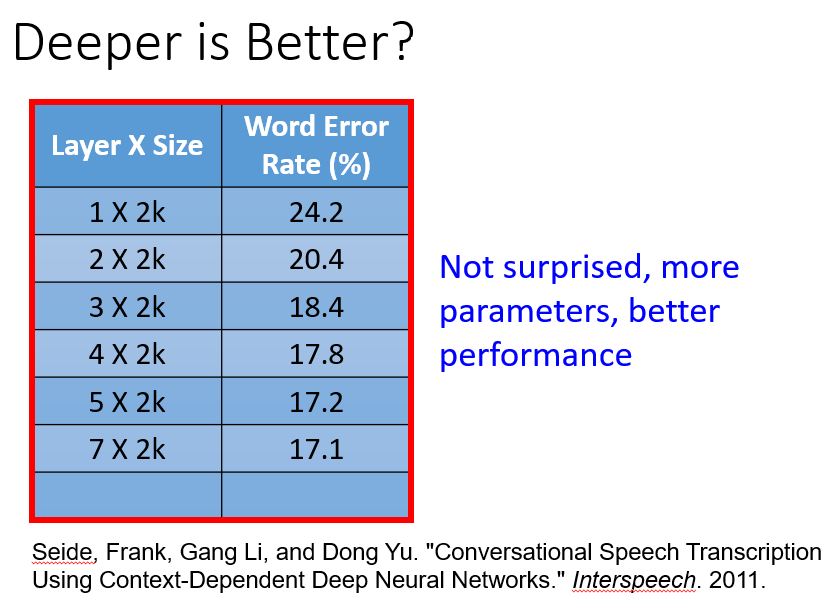
但这个结果并没有令人十分惊喜,因为随着模型的参数增多,这个模型所能涵盖的函数就越多,其偏置也就越小,这在Where does the error come from?中讨论过。当训练数据足够多,使得方差也减小到一定程度时,那么训练结果一定不会差到哪里去。
也就是说,一个比较复杂的模型/一个参数比较多的模型,它的性能表现更好,本来就是一件理所当然的事情,这与“神经网络要不要更深一点”并没有直接关系。因为要使模型变复杂(尽可能涵盖更多函数),除了增加隐藏层(深度增大),也可以不增加隐藏层,只设置 个隐藏层,并使得该隐藏层里有非常多个神经元(这时整个神经网络画出来会很Fat),这样也能起到复杂化模型的作用。
甚至有一个理论认为:对于任何连续的函数
(其输入是一个
维向量
,输出是一个
维向量
),都可以用只含有
个隐藏层的神经网络来表示,只要保证这个隐藏层的神经元足够多,那么神经网络就可以表示成任何一个函数。机器学习的目的就是找到一个最佳函数,其可以很好地描述/预测样本的类型。而如果只含
个隐藏层的神经网络就足以表示任何函数,我们只需要从这个单隐藏层的神经网络里寻找目标函数即可,何必追求很多层的深度神经网络,一层就够了。

所以有人认为,深度学习只是一个噱头。要使模型效果更好,不一定要通过神经网络的深度来体现,不一定非要加大深度,不一定非要追求Deeper,用Fat Neural Network也同样能够提升模型效果。
事实上,Deep Neural Network相较于Fat Neural Network是更有优势的。所以,追求Deeper还是有一定的价值,并非空穴来风,后续会就这个问题继续解释。最后是一些参考资料:
My Course: Machine learning and having it deep and structured
“Neural Networks and Deep Learning”
- written by Michael Nielsen
- http://neuralnetworksanddeeplearning.com/
“Deep Learning”
- written by Yoshua Bengio, Ian J. Goodfellow and Aaron Courville
- http://www.deeplearningbook.org

参考资料:
神经网络和深度学习简史(全)
李宏毅:什么是深度学习——类神经网络的卷土重来
深度学习问世这些年,有哪些里程碑