
求梯度的小提示
- Tip1:小心定义变量,并保持跟踪他们的维度
- Tip2:使用链导法则,弄清楚哪些变量输入到计算中
- Tip3:对于一个模型顶层的softmax,首先考虑正确类别的梯度,然后考虑所有的不正确类别的梯度
- Tip4:如果对矩阵的微积分搞糊涂了,求出元素的偏导数
- Tip5:使用形状惯例。注:到达一个隐藏层的错误信息 与隐藏层的维度应该相同
重新训练词向量会出现的问题
问题
假设我们通过单个单词来训练一个电影评论情感的逻辑回归模型
在训练集中,含有单词“TV”和“telly”
在测试集中,含有单词“television”
预训练的词向量中三个单词都有

问题:当我们更新词向量时,会出现什么问题
答案:在训练集中的单词会移动位置,而在测试集中的单词将会停留在原位置
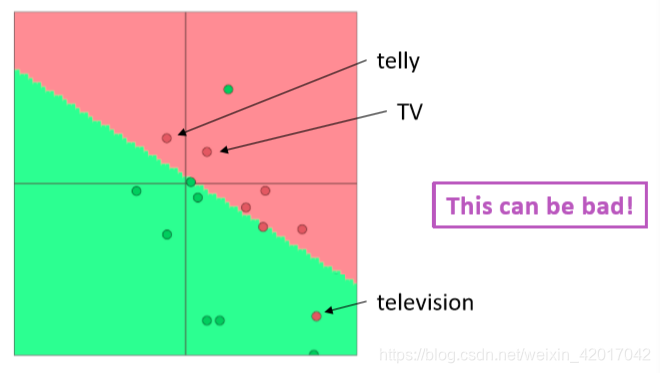
如何解决
- 可以使用存在的预训练词向量吗?
可以,因为使用大规模预料训练出来的词向量,对于下游任务效果会更好 - 应该对词向量进行更新吗?(fine tune)
- 如果训练集较小,不应该训练词向量,但是如果训练集很大,那么fine-tune词向量对最终效果应该有帮助
反向传播
求导数并使用(广义)链式规则
在计算较低层的导数时,重复使用为较高层计算的导数,以使计算量最小化
计算图
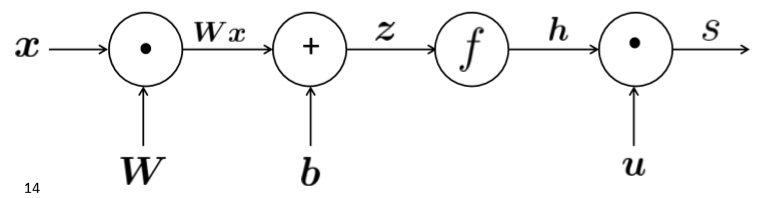
源节点是输入,内部节点是操作,边传递操作的结果。计算的过程即为前向传播。
反向传播
边传递梯度
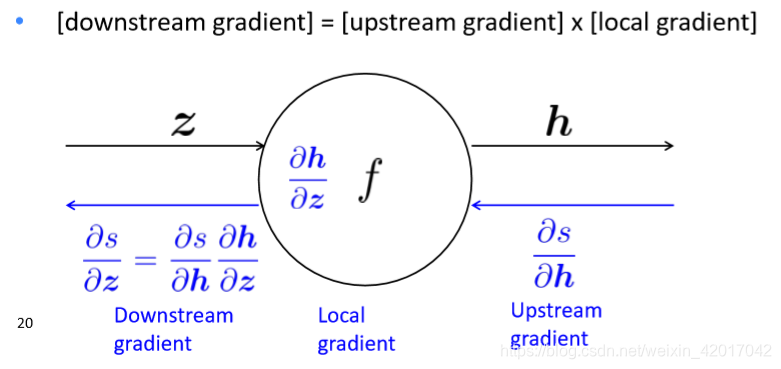
单个节点的计算( )
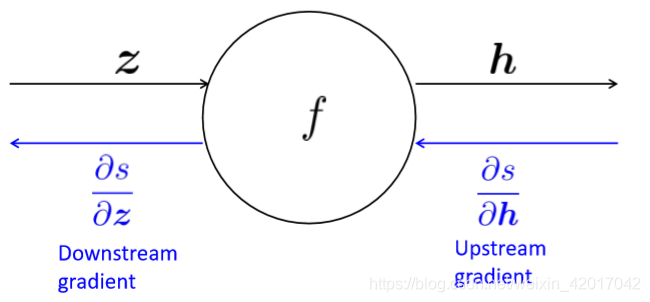
节点接收一个"upstream gradient",目标是向前传递正确的"downstream gradient"。
每个节点有一个Local gradient,即它的输出关于它的输入的梯度,如下图所示
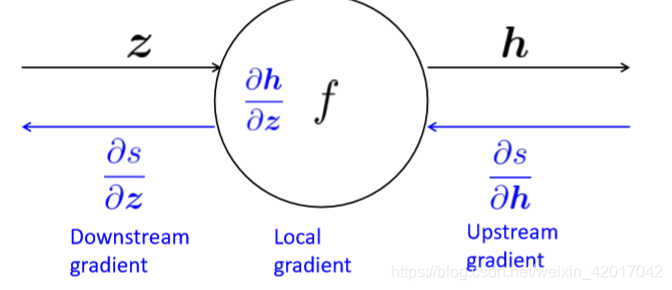
使用链导法则即可求出正确的梯度,如下图所示
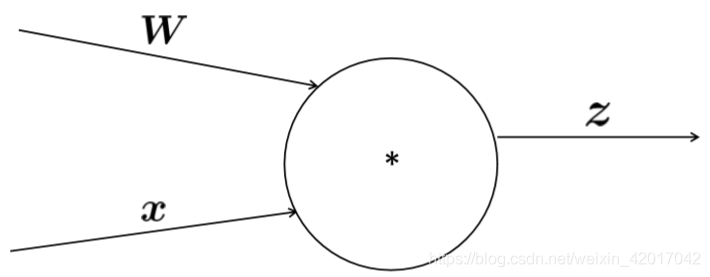
若有多个输入的节点
如:
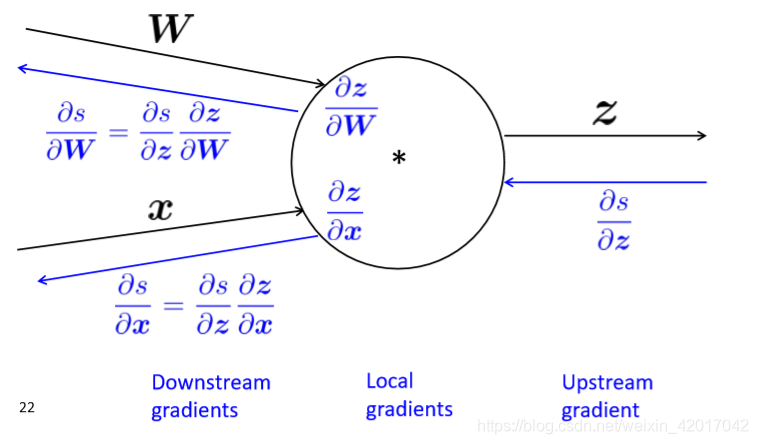
多个输入意味着多个local gradient(本地梯度),即该节点的输出关于每个输入的梯度,如下图所示
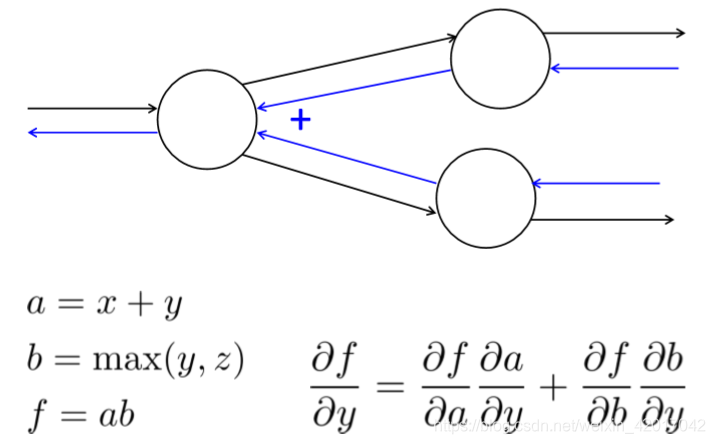
讲义中有一个例子讲的很清楚,若此处不太懂,可以去看看本节课讲义P24-P38
- 一个小技巧
"+"操作节点”分发“upstream gradient,即将上面传来的梯度分发到每个输入去
"max"操作节点”路由“upstream gradient,即将上面传来的梯度只传递到某个输入去,其余为0
"*"操作节点改变upstram gradient - 如下情况,需要加起来
计算效率
同时计算所有输入的梯度并独立计算每个输入的梯度,导致大量重复计算。所以正确的方法应该为:
前向传播:按拓扑顺序访问节点
反向传播:
- 初始化输出梯度为1
- 按相反的顺序访问节点,使用所有后继节点来计算关于每个节点的梯度
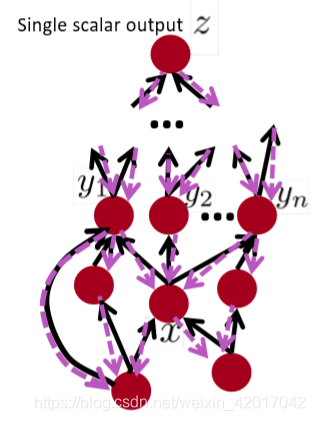
如上图,要计算z关于x的梯度,则计算如下
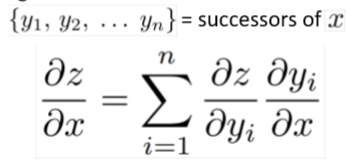
- 前向传播和后向传播大O复杂度相同
自动微分
- 梯度计算可以从fprop的符号表达式自动推断出来
- 每种节点类型都需要知道如何计算其输出,以及如何在给定梯度输出的情况下计算其输入的梯度
- 现代DL框架可以自动进行后向传播,主要留下layer/node的书写
为什么要学习反向传播
这里有一篇文章https://medium.com/@karpathy/yes-you-should-understand-backprop-e2f06eab496b
大意讲了,构建神经网络时会出现很多问题,比如权重矩阵更新缓慢,最终任务效果不好等问题。而引起这些问题的原因有可能在于反向传播上,比如sigmoid,值过大或过小时(权重矩阵初始化会影响),梯度为0,再比如ReLU函数值小于0时,梯度也为0。还有RNN中会出现梯度消失和梯度爆炸等问题。若你不了解反向传播,你就不会警惕这些问题的出现,导致工作效率或得到的最终结果不太好。大概浏览了下,有兴趣的读者可以去看看上面这篇文章。
一些其他知识点
-
实际上,一个完整的损失函数在实际中应该包含所有参数 正则项,例如L2正则
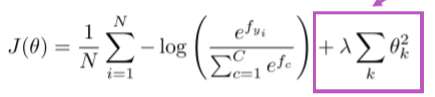
正则项有效避免了过拟合,当含有大量特征,或在一个过深的模型中。 -
向量化:应尽可能避免循环,多使用向量或矩阵,这样能够加速运算。
-
一些非线性激活函数
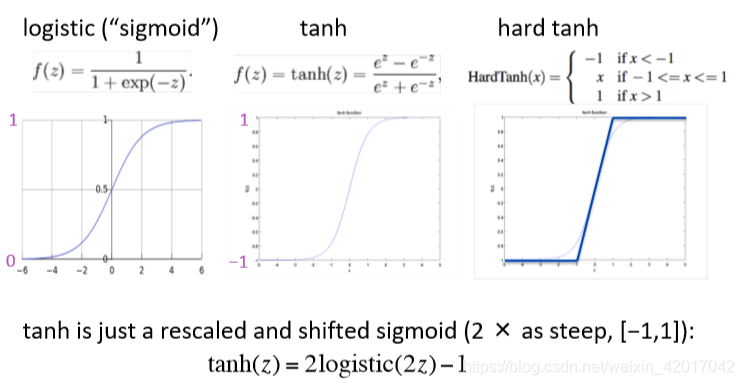
-
参数初始化
- 应该将权重初始化成小的随机值,避免对称性妨碍学习/专业化(不懂)
- 如果权重为0,则将隐藏层偏差初始化为0,并将输出(或重建)偏差初始化为最佳值(例如,平均目标或平均目标的逆sigmoid)
- 初始化所有其他权重~均匀(–r,r),选择r,使数字既不太大也不太小
-
优化
- 通常,使用SGD就可以工作,然而,要想获得好结果通常需要手动调学习率
- 一些更复杂的“自适应”优化器中,这些优化器通过累积的梯度来调整参数。

-
学习率
可以使用一个固定的学习率,但不能过大:会导致发散,不收敛。也不能过小:会导致训练时间很长
也可以随着训练轮数增加,降低学习率,这样会获得更好的效果- 可以手调:每k个epoch将学习率减半
- 可以使用公式 ,对于每个epoch t
- 也有一些更奇特的方法,比如循环学习率
