反向传播 —BackPropagation
Grandient Descent
- 梯度下降通过使用Loss function 对model中的每个参数进行求偏微分 最后通过learnig rate 对model进行更新
-

但是一般大型的神经网络都会有上百万个类似于w\b 这样的参数,如何计算这样的梯度是Backprogation要做的事情。
Backprogation就是一个特殊的梯度下降算法
链式求导

BackProgation——Forward pass(正向传导)
- 定义一个函数**Cn**表示yn和y’^n的距离
- 所以当前network的paramter的loss就是

 对某一参数进行偏微分时
对某一参数进行偏微分时
我们使用一种方法,不需要对所有的paramer进行偏微分,而是对某一笔data进行偏微分就能得到得到grandet
我们以一个genurel举例:

如何计算偏导? 首先使用链式法则:
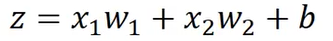

所以我们得到一个规则: 一个神经元对一个paramer的求导就是相应路径上的输入

所以我们可以得到每一个paramer,前的nuerel对相依参数的偏微分:就是前一层传入的input
BackProgation——Backward pass(反向传导)
-
首先我们求解
 ?
?
根据图片我们可以看到如下思路:
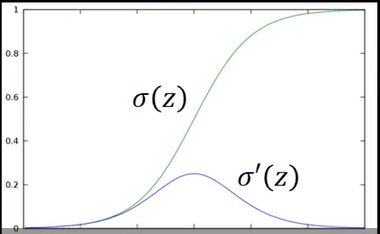 sigmoid 函数和它的微分函数图像
sigmoid 函数和它的微分函数图像
C对A的偏微分可以分解:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-foF9m1zW-1637154131172)(…/…/…/AppData/Roaming/Typora/typora-user-images/image-20210721103841464.png)]
前一项好理解,但是如何理解第二项的偏微分呢?

根据图片我们可以看到z对C的影响通过影响z’和z’'来实现的,所以有链式法则:
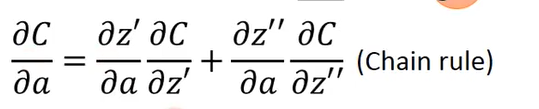
根据之前得到的规则有:
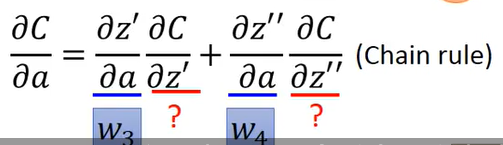
可以得到w3,w4分别是其中两项的值;
现在我们的目标是求出C对z’的偏微分和C对z’'的偏微分:
我们使用逆向思维:

-
z是一个常数,一个固定的值,在我们做正向传导的时候我们已经知道它是多少了,所以他是一个常数,所以
 也是一个常数。
也是一个常数。所以,目前我们的目标就是计算
 和
和
-
此时,计算这两项的思路仍然和之前一样:


但是如果存在第二层的话:又要进行之前的操作,所以这是一种思想:递归,我们可以通过计算机计算出最终的结果。
就是反向计算偏微分利用规律来计算偏微分;

这就是Backpropagation。