what:
交叉熵是信息论的重要概念;用于度量两个概率分布之间的差异性;
其他相关知识:
- 信息量:
信息是用来消除随机不确定的东西;
信息量的大小与信息发生的概率成反比;
I(x)=−log(P(x)),
p(x)表示某一事件发生的概率,log表示自然对数
举例:
信息量为0:“太阳从东边升起”
信息量极大:”2018年中国队成功进入世界杯“
- 信息熵:
信息熵也叫熵,是用来表示所有信息量的期望;
期望是每次试验结果的概率 乘以 信息量的总和,因此公式如下:

举例:

H(X)=−n=1∑nP(xi) log(P(xi))
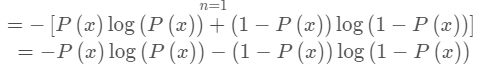
- 相对熵
如果对于同一个随机变量 X 有两个单独的概率分布P(x) 和Q (x), 那么就可以用KL散度来衡量这两个概率分布之间的差异:公式如下:

机器学习中,通常用p(x)表示样本的真实分布,Q(x)表示模型预测的分布;
举例:

- 交叉熵:
H(p(x))表示信息熵,后者表示交叉熵;所以 公式计算上KL散度=交叉熵 - 信息熵
交叉熵的公式为:
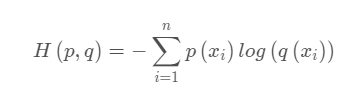
note:
机器学习训练时,输入数据和标签通常已经确定(真实概率分布P(x)确定),所以信息熵就是常量; 并且当真实概率分布P(x) 和 预测概率分布Q(x) 之间的差异越小表示预测的acc越高; 所以目标是最小化KL散度; 又因为交叉熵 = KL散度+信息熵,且公式比KL散度计算 更加容易计算,所以机器学习通常用交叉熵来计算loss。
举例:
