词源 — 最初来源于热力学
Entropy来源于希腊语,原意:内向,即:一个系统不受外部干扰时往内部稳定状态发展的特性。定义的其实是一个热力学的系统变化的趋势。
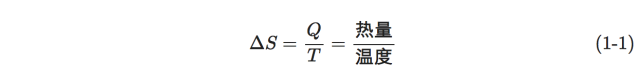
1923年,德国科学家普朗克来中国讲学用到entropy这个词,胡刚复教授看到这个公式,创造了“熵”字,因为“火”和热量有关,定义式又是热量比温度,相当自洽。
信息论
信息论中,熵是接受的每条消息中包含的信息的平均值。又被称为信息熵、信源熵、平均自信息量。可以被理解为不确定性的度量,熵越大,信源的分布越随机。
1948年,由克劳德·爱尔伍德·香农将热力学中的熵引入信息论,所以也叫做:香农熵。
生态学
在生态学中,熵表示生物多样性的指标。

广义的定义
熵是描述一个系统的无序程度的变量;同样的表述还有,熵是系统混乱度的度量,一切自发的不可逆过程都是从有序到无序的变化过程,向熵增的方向进行。
我们接下来要讨论的信息熵 交叉熵 相对熵 更多的着眼于信息论的角度,换句话说,更加关注概率和不确定性。
2 什么是信息熵、交叉熵、相对熵
可以将对熵的理解从简单到复杂依次分解成三个层次来理解。
如何衡量不确定事物的发生?
数学是一种工具,使用数学来描述现实中的各种事物是一个数学家本质的工作目标。而现实中不确定性,或者说不太确定是否会发生的事件必须要找到一种抽象的、符号化和公式化的手段去表示。
比如天气情况,假设可能有【阴、晴、雨、雪】四种情况,使用概率符号表示P=[p1, p2, p3, p4],接下来自然而然的思考:那么,什么条件(情况)会影响这些值呢?
假设有一下三种描述,或者说条件
今天是晴天,所以明天可能也是晴天
天气预报说明天下雨
9月12日苹果公司举行发布会
那么这三个描述中,很明显,第二条的信息量更大,因为它可以使得不确定事件发生在p3的概率更大。类似的,第三条对判断毫无帮助,信息量为0。注意,信息量不等于信息熵,如果是这样,那么直接用概率来衡量就可以了,不需要在重新定义一个概念。
其实信息熵是信息量的期望(均值),它不是针对每条信息,而是针对整个不确定性结果集而言,信息熵越大,事件不确定性就越大。单条信息只能从某种程度上影响结果集概率的分布。
考虑到信息冗余,信息量存储下来究竟需要多大空间?
我们已经有了P=[p1, p2, p3, p4],来表示天气情况,那么用计算机来存储每天的天气,那该如何编码呢?
常见的做法是,4个不同的信息,只需要2bit就能做到,00 01 11 10,假设我们在南方城市,肯定要把00编码成雨天,这样可以节省存储空间,至于为什么能节省存储空间,这就要讨论编码方式。可以简单的理解为,如果一串信息一串0很多,可以通过编码压缩这一群0来节省空间。
之后我们发现这个公式中有个除法非常讨厌,我们想着去掉它,脑海中第一反应出来的满足这个条件的一定是取对数,至于为什么取对数,那说道就很多,取对数是指数的逆操作,
对数操作可以让原本不符合正态分布的模型符合正态分布,比如随着模型自变量的增加,因变量的方差也增大的模型取对数后会更加稳定。
取对数操作可以rescale(原谅我,这里思前想后还是感觉一个英文单词更加生动)其实本质来说都是因为第一点。说人话版本,人不喜欢乘法,对数可以把乘法变加法。
那么我们结束清楚之后,就很容易就可以定义出
a作为底数,可以取2(处理2bit数据),10(万金油),e(处理正态分布相关的数据)
结合对信息熵的定义(第一节最后的粗体字)然后把(2-2)带入(2-1),就会发现,哦!看着有点眼熟啊。
这这这,就是信息熵的定义式吧?总结就发现,信息熵其实从某种意义上反映了信息量存储下来需要多少存储空间。
总结为:根据真实分布,我们能够找到一个最优策略,以最小的代价消除系统的不确定性(比如编码),而这个代价的大小就是信息熵。
理解基于信息熵的交叉熵和相对熵
因为是我们用2bit模式存储,为了计算方便,这里取a = 2
直观的来考虑上面不同的两种情况,明显当事件的不确定性变小时候,我们可以改变存储策略(00 雨天 01 阴天),再通过编码,节省存储空间。信息熵的大小就是用来度量这个不确定大小的。
关于编码的方式,这里提一下,哈夫曼树与哈夫曼编码 ,有兴趣的读者可以去研究一下。
交叉熵的由来
我们把这个问题再扩展一下

顾名思义,看公式3-1的形式,就不难发现,这就是所谓的交叉熵,计算可得
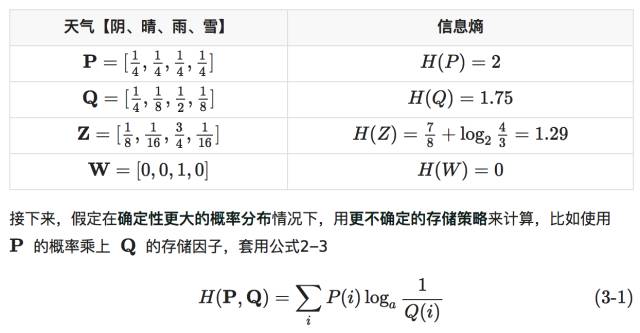
上表直观的展现的交叉熵的数值表现,PQZW依次不确定性越来越低,极端情况的W不确定性为0,即是确定的。
交叉熵,用来高衡量在给定的真实分布下,使用非真实分布指定的策略消除系统的不确定性所需要付出努力的大小。
总的来说,我们的目的是:让熵尽可能小,即存储空间小(消除系统的不确定的努力小)。(不要问为什么想要存储空间小,这都是钱更是效率和时间)。
通过上表我们发现一个规律,为了让熵小,解决方案是:是用确定性更大的概率乘以确定性更小的存储因子,比如不确定性越大的概率分布,如P概率分布,其信息熵越大;基于同一真实(确定性)分布的情况下,套用不确定性更大的存储因子,如P的存储因子,得出的交叉熵越大。
在机器学习中,即用测试结果集(样本结果集)的概率乘以训练出来的结果集存储因子,而在不断的训练过程中,我们要做的就是通过不断调整参数,降低这个值,使得模型更加的稳定,不确定性越来越小,即突出需要表征的数值的特点(白话文也就是分类的效果更好)。
相对熵的由来
