熵、条件熵、相对熵、交叉熵和互信息
目录
笔记仅从机器学习角度理解下面的内容
1. 信息熵(Information entropy)
熵 (Entropy) 这一词最初来源于热力学。1948年,克劳德·爱尔伍德·香农将热力学中的熵引入信息论,所以也被称为香农熵 (Shannon entropy)、信息熵 (information entropy)。
首先,我们先来理解一下信息这个概念。信息是一个很抽象的概念,百度百科将它定义为:指音讯、消息、通讯系统传输和处理的对象,泛指人类社会传播的一切内容。我们知道我们的世界是由很多的信息构成的,我们需要了解这些信息、沟通这些信息,甚至是度量和测量这些信息的大小。那信息可以被度量么?可以的!香农提出的“信息熵”概念解决了这一问题。
假设我们需要搞清楚一件事,如果这件事的发生非常非常不确定,或者我们之前对此事一无所知,那么就需要了解大量的信息。相反,如果某件事经常发生,我们已经有了较多的了解,我们就不需要太多的信息就能把它搞清楚。所以,从这个角度出发,直觉上我们可以认为,一条信息的信息量的大小和它的不确定性有关系,而我们经常使用概率来说明一个事件的不确定性。
假设我们用随机变量\(x\)来表示事件。信息量可以被看成在学习\(x\)的值的时候的“惊讶程度”。举个例子说明一下,比如,有人说广州下雪了。对于这句话,我们是十分不确定的。因为广州几十年来下雪的次数寥寥无几,发生的概率很低。为了搞清楚这件事,我们就要去看天气预报,新闻,询问在广州的朋友,而这就需要大量的信息,信息量很大。再比如,你接到了妈妈打来的电话,让你晚上回家吃饭。对于这件事,因为它很可能发生,几乎不需要引入信息,信息量很小。我们想找到一个函数\(h(x)\)来衡量事件信息量的大小。这里用\(h(x_1)\)和\(h(x_2)\)来表示上面的两个例子的信息量,那么,怎么表示\(h(x_1)\)和\(h(x_2)\)之间的大小关系呢?怎么寻找到函数\(h(x)\)呢?
从上边的例子出发,首先,直觉上看,事件\(x\)的信息量应该和它的概率分布\(p(x)\)有关,而且信息量\(h(x)\)增大,\(p(x)\)减小,而\(h(x)\)减小,则\(p(x)\)增大,可以认为是\(h(x)\)和\(\dfrac{1}{p(x)}\)之间的关系。当然,此时也可能认为是\(h(x)\)和\(-p(x)\)的关系,我们后面再说。
其次,我们考虑观察两个事件同时发生时获得的信息量,假设是两个不相关的事件,它和每个事件的信息量有什么关系呢?也就是说你听说广州下雪了,同时你接到了妈妈的电话叫你回家吃饭,这两件事应该是独立的,所以它们的信息量应该是和的关系,即\(h(x_1,x_2)= h(x_1) + h(x_2)\)。
最后,一个信息量的函数应该是大于零、等于零还是小于零呢?如果你接到了妈妈的电话,你至多也就是觉得这个电话对你来说没有任何的信息,而你的信息是不会跑到你妈妈那里的。所以这个函数应该是大于等于0的,即\(h(x) \ge 0\)。回过头来看,前面认为的\(h(x)\)和\(-p(x)\)的关系是不太合理的,因为\(p(x)\)是一个大于等于0的数。
综上,就想到了以下函数:
首先,函数满足\(p(x)\)减小,\(h(x)\)增大,而\(p(x)\)增大,则\(h(x)\)减小;
其次,因为两个事件是独立的,因此\(p(x_1,x_2)=p(x_1)p(x_2)\)。所以
最后,显然\(h(x)\)是大于等于0的。
因此,我们得到了信息量函数(information function)
其中, 对数函数底的选择是任意的,信息论中底常常选择为2,\(h(x)\)的单位为比特(bit),而机器学习中底常常选择为自然常数,\(h(x)\)的单位为奈特(nat)。
\(h(x)\)也被称为随机变量\(x\)的自信息(self-information),描述的是随机变量的某个事件发生所带来的信息量。如图1所示:
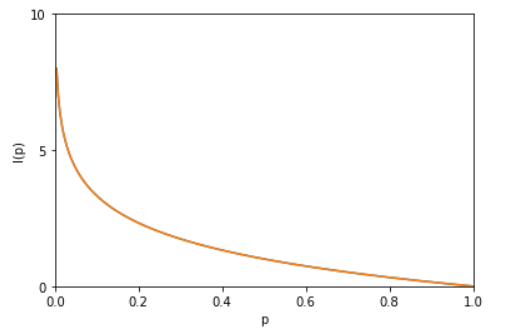
图1
那么,什么是熵呢?
熵(entropy)是定义为关于函数\(h(x)\)在随机变量\(X\)以\(p(x)\)为分布下的数学期望,即假设一个发送者想传输一个随机变量的值给接受者。这个过程中,他们传输的平均信息量可以通过求公式\((1)\)关于概率分布\(p(x)\)的期望得到
这个量被叫做随机变量\(x\)的熵,它是随机变量不确定性的度量,是对所有可能发生的事件产生的信息量的期望。
我们知道,如果随机变量\(X\)是离散型变量,则\(E_x[f(x)] = \sum_x p(x) f(x)\),将其中的\(f(x)\)替换成\(h(x)\)即可得到公式\((2)\)。
现在举个例子说明这些定义的性质。考虑一个随机变量\(x\),这个随机变量有8种可能的状态,每个状态都是等可能的。个人理解,我们就想象有这么一个空间,空间中有64个小球,共有8种颜色,每种颜色小球的个数相等,都为8个。那么这个变量的熵为
信息论中即为为了把\(x\)的值传递给接收者,我们需要传输3比特的消息。
现在考虑⼀个具有8种可能状态\(\{a, b, c, d, e, f, g, h, g\}\)的随机变量,每个状态各自的概率为\((\cfrac{1}{2},\cfrac{1}{4},\cfrac{1}{8},\cfrac{1}{16},\cfrac{1}{64},\cfrac{1}{64},\cfrac{1}{64},\cfrac{1}{64})\)(Cover and Thomas, 1991)。这种情形下的熵为
我们看到,⾮均匀分布⽐均匀分布的熵要⼩。
从公式可得,随机变量的取值个数越多,状态数也就越多,信息熵就越大,混乱程度就越大。当随机分布为均匀分布时,熵最大,且\(0≤H(X)≤logM\)。其中\(M\)是状态\(x_i\)的总数。
注:这里的结论及以下的微分熵相关的结论的证明可参见(Christopher M. Bishop-- Pattern Recognition and Machine Learning)
我们可以把熵的定义扩展到连续变量\(x\)的概率分布\(p(x)\),这时把熵称作微分熵(differential entropy)
在离散分布的情况下,最⼤熵对应于变量的所有可能状态的均匀分布。而连续变量的最⼤化微分熵的分布是⾼斯分布。
注意:
- 从熵的公式可以看出,\(H(x)\)是一个函数(概率分布函数)的函数。
- 熵只依赖于随机变量的分布,与随机变量的取值无关,所以也可以将\(X\)的熵记作\(H(p)\)。
- 因为\(lim_{p\rightarrow 0}p log_2 p =0\),因此只要我们遇到一个\(x\)使得\(p(x)=0\),那么就应该令\(p(x)log_2(p(x))=0\)。
- 与离散熵不同,微分熵可以为负,即存在\(H(x)<0\)的情况。
2. 条件熵(Conditional entropy)
如上述,将一维随机变量分布推广到多维随机变量分布,则可得到联合熵(joint entropy):
条件熵表示在已知随机变量\(X\)的条件下随机变量\(Y\)的不确定性,记作\(H(Y|X)\)。\(H(Y|X)\)是\(X\)给定条件下\(Y\)的条件概率分布的熵对\(X\)的数学期望:
条件熵\(H(Y|X)\)也可以理解为联合熵\(H(X,Y)\)减去随机变量\(X\)的熵\(H(X)\),即
表示\((X,Y)\)发生所包含的熵,减去\(X\)单独发生包含的熵,即在\(X\)发生的前提下,\(Y\)发生“新”带来的熵。
注意:
注意公式\((5)\),这个条件熵,是指在给定某个数(某个变量为某个值)的情况下,另一个变量的熵是多少,变量的不确定性是多少。
因为条件熵中\(X\)也是一个变量,意思是在一个变量\(X\)的条件下(变量\(X\)的每个值都会取),另一个变量\(Y\)熵对\(X\)的期望。
这是最容易错的!
下面通过例子来解释一下:
假如我们有下面数据,表格1:
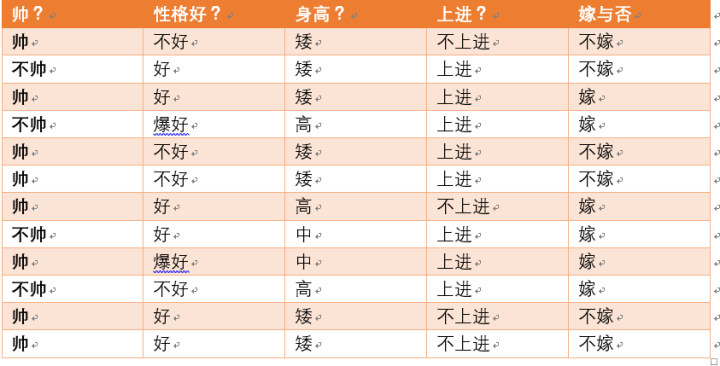
表格1
设随机变量\(Y=\) {嫁,不嫁}
我们可以统计出,嫁的个数为6/12 = 1/2
不嫁的个数为6/12 = 1/2
那么\(Y\)的熵,根据熵的公式来算,可以得到\(H(Y) = -\cfrac{1}{2}log_2\cfrac{1}{2} -\cfrac{1}{2}log_2\cfrac{1}{2}\)
为了引出条件熵,我们现在还有一个变量\(X\),代表长相是帅还是不帅,当长相是不帅的时候,统计如下表格2红色所示:
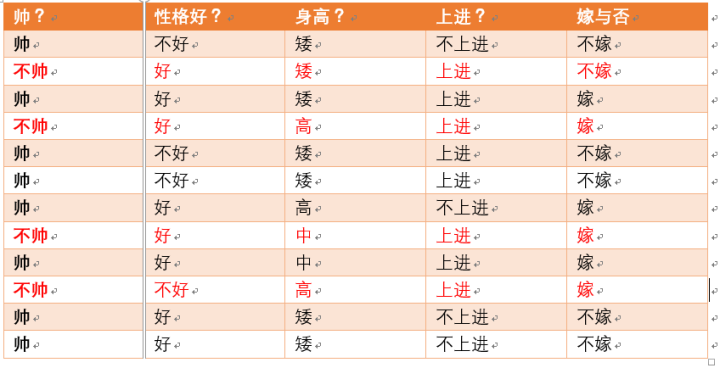
表格2
可以得出,当已知不帅的条件下,满足条件的只有4个数据了,这四个数据中,不嫁的个数为1个,占1/4,嫁的个数为3个,占3/4,那么此时的\(H(Y|X=不帅) = -\cfrac{1}{4}log_2\cfrac{3}{4} -\cfrac{3}{4}log_2\cfrac{3}{4}\),\(p(X = 不帅) = 4/12 = 1/3\)
同理我们可以得到:
当已知帅的条件下,满足条件的有8个数据了,这八个数据中,不嫁的个数为5个,占5/8,嫁的个数为3个,占3/8。那么此时的\(H(Y|X=帅) = -\cfrac{5}{8}log_2\cfrac{5}{8} -\cfrac{3}{8}log_2\cfrac{3}{8}\),\(p(X = 帅) = 8/12 = 2/3\)
计算结果
有了上面的铺垫之后,我们终于可以计算我们的条件熵了,我们现在需要求:
也就是说,我们想要求出当已知长相的条件下的条件熵。根据公式我们可以知道,长相可以取帅与不帅两种,条件熵是另一个变量\(Y\)熵对\(X\)(条件)的期望。
公式为:
其中,\(H(Y|X=长相) = p(X =帅) \times H(Y|X=帅) + p(X =不帅) \times H(Y|X=不帅)\)
然后将上面已经求得的答案带入即可求出条件熵!
这里比较容易发生的错误就是忽略了\(X\)也是可以取多个值,然后对其求期望!!
总结一下,其实条件熵意思是按一个新的变量的每个值对原变量进行分类,比如上面这个题把嫁与不嫁按帅,不帅分成了俩类。然后在每一个小类里面,都计算一个小熵,然后每一个小熵乘以各个类别的概率,然后求和。我们用另一个变量对原变量分类后,原变量的不确定性就会减小了,因为新增了X的信息,可以感受一下。不确定程度减少了多少就是信息的增益。
3. 相对熵(Relative entropy)和交叉熵(Cross entropy)
我们现在开始把熵关联到机器学习问题中。考虑某个未知的分布\(p(x)\),假定我们已经使⽤⼀个近似的分布\(q(x)\)对它进⾏了建模。如果我们使⽤\(q(x)\)来建⽴⼀个编码体系,⽤来把\(x\)的值传给接收者,那么,由于我们使⽤了\(q(x)\)⽽不是真实分布\(p(x)\),因此在具体化\(x\)的值时,我们需要⼀些附加的信息。我们需要的平均的附加信息量(单位是nat)为
如果\(p(x)\)和\(q(x)\)是离散随机变量\(X\)中取值的两个概率分布,则
注:这里我们把熵的定义中的对数变成⾃然对数
这个重要的量被称为分布\(p(x)\)和\(q(x)\)之间的相对熵(relative entropy),或者Kullback-Leibler散度(Kullback-Leibler divergence),或者KL散度(Kullback and Leibler, 1951)。
相对熵的一些性质:
- 如果\(p(x)\)和\(q(x)\)两个分布相同,即有\(q(x) = p(x)\)对于所有\(x\)都成⽴时,相对熵等于0;
- 相对熵具有不对称性\(D_{KL}(p||q) \ne D_{KL}(q||p)\)。举个简单的例子:
假设随机变量\(x\)服从0-1分布,现有概率分布\(p(x)\)和\(q(x)\)。且
则
那么,当\(r=s\)时,\(D_{KL}(p||q) = D_{KL}(q||p) = 0\),如果\(r=0.5, s=0.25\),则计算得到
- \(D_{KL}(p||q) \ge 0\),证明如下:
首先,介绍凸函数(convex function)的概念,如果一个函数具有以下的性质:每条弦都位于函数图像或其上⽅(如图2所⽰),那么我们说这个函数是凸函数。位于\(x = a\)到\(x = b\)之间的任何⼀个\(x\)值都可以写成\(\lambda{a}+(1-\lambda)b\)的形式,其中\(0 \le \lambda \le 1\)。弦上的对应点可以写成\(\lambda {f(a)} + (1 -\lambda)f(b)\),函数的对应值为\(f(\lambda a + (1 -\lambda)b)\)。这样,凸函数的性质就可以表⽰为:
这等价于要求函数的⼆阶导数处处为正。凸函数的例⼦有\(xln x(x > 0)\)和\(x^2\) 。如果等号只在\(\lambda = 0\)和\(\lambda = 1\)处取得,我们就说这个函数是严格凸函数(strictly convex function)。如果⼀个函数具有相反的性质,即每条弦都位于函数图像或其下⽅,那么这个函数被称为凹函数(concave function)。对应地,也有严格凹函数(strictly concave function)的定义。如果\(f(x)\)是凸函数,那么\(-f(x)\)就是凹函数。
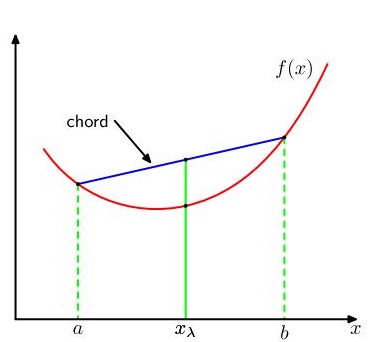
图2 凸函数f(x)的每条弦(蓝⾊表⽰)位于函数上或函数上⽅,函数⽤红⾊曲线表⽰
使⽤归纳法,我们可以根据公式\((9)\)证明凸函数\(f(x)\)满⾜
其中,对于任意点集\(\{x_i\}\),都有\(\lambda_i \ge 0\)且\(\sum_i \lambda_i=1\)。上述公式的结果被称为Jensen不等式(Jensen's inequality)。如果我们把\(\lambda_i\)看成取值为\(\{x_i\}\)的离散变量\(x\)的概率分布,那么上面的公式可以写成
其中,\(E[\cdot]\)表示期望。对于连续变量,Jensen不等式的形式为
所以,
因为\(\sum_x q(x) =1\),所以\(D_{KL}(p||q) \ge 0\)。推导过程中,我们使⽤了\(ln x\)是凸函数的 事实, 以及归⼀化条件\(\sum_x q(x) =1\)。实际上,\(ln x\)是严格凸函数,因此只有\(q(x) = p(x)\)对于所有\(x\)都成⽴时,等号才成⽴。上面公式的意义就是求\(p(x)\)和\(q(x)\)之间的对数差在\(p(x)\)上的期望值。因此我们可以把Kullback-Leibler散度看做两个分布\(p(x)\)和\(q(x)\)之间不相似程度的度量。
比如TD-IDF算法就可以理解为相对熵的应用:词频在整个语料库的分布与词频在具体文档中分布之间的差异性。
那么,什么是交叉熵?
假设\(p(x)\)和\(q(x)\)是关于某样本集的2个概率分布,其中\(p(x)\)为数据的真实分布,\(q(x)\)对\(p(x)\)的一个近似。按照真实分布\(p(x)\)来衡量识别一个样本的所需要的编码长度的期望,即平均编码长度(也就是熵)为\(H(x) = -\sum_x p(x)ln p(x)\)。如果我们要使用近似分布\(q(x)\)来表示真实分布\(p(x)\)的平均编码长度,则应该是:
因为用\(q(x)\)来编码的样本来自分布\(p(x)\),所以期望\(H(p(x),q(x))\)中的概率是\(p(x)\)。这里的\(H(p(x),q(x))\)我们称之为交叉熵。
比如含有4个字母(A,B,C,D)的数据集中,真实分布\(p(x)=(1/2, 1/2, 0, 0)\),即A和B出现的概率均为1/2,C和D出现的概率都为0。计算\(H(p(x))\)为1,即只需要1位编码即可识别A和B。如果使用分布\(q(x)=(1/4, 1/4, 1/4, 1/4)\)来编码则得到\(H(p(x),q(x))=2\),即需要2位编码来识别A和B(当然还有C和D,尽管C和D并不会出现,因为真实分布\(p(x)\)中C和D出现的概率为0,这里就钦定概率为0的事件不会发生啦)。注:为了计算方便,这里是以2为底的对数
可以看到上例中根据近似分布\(q(x)\)得到的平均编码长度\(H(p(x),q(x))\)大于根据真实分布\(p(x)\)得到的平均编码长度\(H(p(x))\)。事实上,根据Gibbs inequality可知,\(H(p(x),q(x)) \ge H(p(x))\)恒成立,当\(q(x)=p(x)\)时取等号,此时交叉熵等于信息熵。
有没有发现,我们此时又回到了相对熵,即由\(q(x)\)得到的平均编码长度比由\(p(x)\)得到的平均编码长度多出的bit数(对数底数为2时):
机器学习的目的就是希望\(q(x)\)尽可能地逼近甚至等于\(p(x)\),从而使得相对熵接近最小值0。由于真实的概率分布是固定的(在机器学习中,训练数据分布是固定的),相对熵公式\((7)\)的后半部分就成了一个常数。那么相对熵达到最小值的时候,也意味着交叉熵达到了最小值。对\(q(x)\)的优化就等效于求交叉熵的最小值。另外,对交叉熵求最小值,也等效于求最大似然估计(maximum likelihood estimation)。这里简单介绍一下,具体可以参考(Deep Learning -- 5.5 Maximum Likelihood Estimation.)
假设数据是通过未知分布\(p(x)\)生成的,我们要对\(p(x)\)建模。一个可行的做法是使用一些参数分布\(q(x|\theta)\)来近似这个分布。\(q(x|\theta)\)由可调节的参数\(\theta\)控制,比如说它是一个多元高斯分布。其中一种确定\(q(x|\theta)\)的方式是最小化\(p(x)\)和\(q(x|\theta)\)之间关于\(\theta\)的Kullback-Leibler散度。但是这里有一个问题就是,我们并不知道真实的\(p(x)\)。但是,我们已经观察到了服从分布\(p(x)\)的有限数量的训练点\(x_i, i=1,2,\dots,m\)。我们知道,如果我们给定有限数量的\(m\)个点,这些点满⾜某个概率分布或者概率密度函数,那么期望可以通过求和的⽅式估计,即
那么,关于\(p(x)\)的期望就可以通过这些点的有限加和来近似,同时,从公式\((8)\)可以看出,Kullback-Leibler散度就是求\(p\)与\(q\)之间的对数差在\(p(x)\)上的期望值。所以
上述公式中,右侧第二项与\(\theta\)无关,第⼀项是使⽤训练集估计的分布\(q(x|\theta)\)下的\(\theta\)的负对数似然函数。因此我们看到,最⼩化Kullback-Leibler散度等价于最⼤化似然函数。
通常“相对熵”也可称为“交叉熵”,虽然公式上看相对熵=交叉熵-信息熵,但正如上面说的由于真实分布\(p(x)\)是固定的,\(D_{KL}(p||q)\)由\(H(p(x),q(x))\)决定。当然也有特殊情况,彼时两者须区别对待。
4. 互信息(Mutual Information)
在概率论和信息论中,两个随机变量的互信息(Mutual Information,简称MI)或转移信息(transinformation)是变量间相互依赖性的量度。
现在考虑由\(p(x,y)\)给出的两个变量\(X\)和\(Y\)组成的数据集。如果变量的集合是独⽴的,那么他们的联合分布可以分解为边缘分布的乘积\(p(x,y) = p(x)p(y)\)。如果变量不是独⽴的,那么我们可以通过考察联合概率分布与边缘概率分布乘积之间的Kullback-Leibler散度来判断它们是否“接近”于相互独⽴。此时,Kullback-Leibler散度为
其中,\(p(x,y)\)是\(X\)和\(Y\)的联合概率分布函数,而\(p(x)\)和\(p(y)\)分别是\(X\)和\(Y\)的边缘概率分布函数。
同样的,在连续型随机变量的情形下,求和被替换为二重定积分:
这被称为变量\(X\)和变量\(Y\)之间的互信息。根据Kullback-Leibler散度的性质,我们看到\(I(X,Y) \ge 0\),当且仅当\(X\)和\(Y\)相互独⽴时等号成⽴。使⽤概率的加和规则和乘积规则,我们看到互信息和条件熵之间的关系为
因此我们可以把互信息看成由于知道\(Y\)值⽽造成的\(X\)的不确定性的减⼩(反之亦然)。从贝叶斯的观点来看,我们可以把\(p(x)\)看成\(x\)的先验概率分布,把\(p(x|y)\)看成我们观察到新数据\(y\)之后的后验概率分布。因此互信息表⽰⼀个新的观测\(y\)造成的\(x\)的不确定性的减⼩。
互信息的性质:
- 对称性:\(I(X,Y) = I(Y,X)\)
- 非负性:\(I(X,Y) \ge 0\)
- 当\(X\),\(Y\)独立时,\(I(X,Y)=0\)
- 当\(X\),\(Y\)知道一个就能推断另一个时,\(I(X,Y)=H(X)=H(Y)\)
直观上,互信息度量\(X\)和\(Y\)共享的信息。如果\(X\)和\(Y\)相互独立,则知道\(X\)不对\(Y\)提供任何信息,反之亦然,所以它们的互信息为0。在另一个极端,如果\(X\)是\(Y\)的一个确定性函数,且\(Y\)也是\(X\)的一个确定性函数,那么传递的所有信息被\(X\)和\(Y\)共享,知道\(X\)就能决定\(Y\)的值,反之亦然。因此,在此情形互信息与\(Y\)(或\(X\))单独包含的不确定度相同,即为\(Y\)(或 \(X\))的熵。而且,这个互信息与\(X\)的熵和\(Y\)的熵相同。(这种情形的一个非常特殊的情况是当\(X\)和\(Y\)为相同随机变量时。)
总结一下上面内容得到的等式:
- 条件熵定义:\(H(X|Y) = H(X,Y) - H(Y)\)
- 互信息展开:\(H(X|Y) = H(X) - I(X,Y)\)
- 对偶式:\(H(Y|X) = H(X,Y) - H(X)\),\(H(Y|X) = H(Y) - I(X,Y)\)
- \(I(X,Y)= H(X) + H(Y) - H(X,Y)\)
以上等式都可以通过之前描述的公式进行推导,这里不再展开。其中,\(H(X)\)和\(H(Y)\)是信息熵,\(H(X|Y)\)和\(H(Y|X)\)是条件熵,\(H(X,Y)\)是\(X\)和\(Y\)的联合熵。注意到这组关系和并集、差集和交集的关系类似,用Venn图表示,如图3:
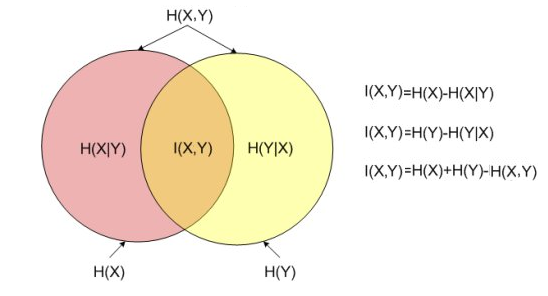
图3
以上!
开心吧
有一天螃蟹出门,不小心撞倒了泥鳅,
泥鳅很生气地说:“你是不是瞎啊!”
螃蟹说:“不是啊,我是螃蟹。”
参考来源:
1)Christopher M. Bishop -- Pattern Recognition and Machine Learning
2)https://www.zhihu.com/question/41252833/answer/141598211
3)https://www.cnblogs.com/kyrieng/p/8694705.html
4)https://blog.csdn.net/witnessai1/article/details/79574812 KL散度(相对熵)、交叉熵的解析
5)https://zhuanlan.zhihu.com/p/26551798 通俗理解条件熵