[1] https://www.cnblogs.com/kyrieng/p/8694705.html
熵
H(X)=−∑xp(x)logp(x), 它表示的是随机变量
X的不确定性,不确定性越大,熵越大。
没有条件约束的时候,X是均匀分布,对应的熵最大。
给定均值和方差的前提下,正态分布对应的熵最大。
联合熵
这里以两个随机变量为例:
H(X,Y)=−∑x,yp(x,y)logp(x,y)
条件熵
H(Y∣X)=H(X,Y)−H(X)
H(Y∣X)=−∑x,yp(x)p(y∣x)logp(y∣x)=−∑x,yp(x,y)logp(y∣x)
相对熵,也称KL散度
相对熵用来衡量两个分布的差异。设p(x),q(x)是离散变量X取值的两个概率分布,则p对q的相对熵是:
DKL(p∣∣q)=∑xp(x)logq(x)p(x)
性质:
-
DKL(p∣∣q)≥0,当p(x)和q(x)两个分布相同的时候,为0
-
DKL(p∣∣q)̸=DKL(q∣∣p),即不对称性
交叉熵
样本的真实分布p(x),非真实分布q(x)
H(p,q)=∑xp(x)logq(x)1
相对熵和交叉熵的关系
DKL(p∣∣q)=∑xp(x)logq(x)p(x)=−H(p)+H(p,q)
其中
H(p)=−∑xp(x)logp(x)
因为相对熵非负,因此
H(p,q)≥H(p)。
在机器学习中,训练数据的分布是固定的,因此最小化相对熵(KL散度)等价于最小化交叉熵,也等价于极大似然估计。所以,交叉熵可以用来计算学习模型分布与训练分布之间的差异。
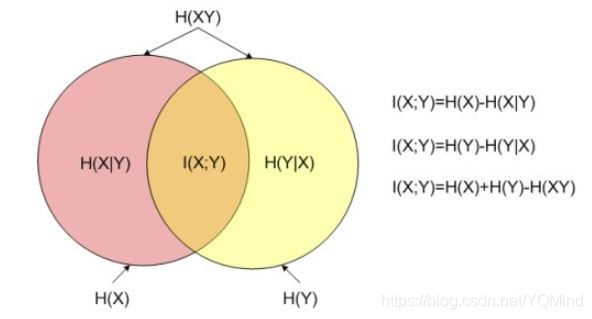
互信息
I(X,Y)=∑x,yp(x,y)logp(x)p(y)p(x,y)
当X和Y独立时,
p(x,y)=p(x)p(y),此时互信息为0。