前言
之前有写过一篇文章介绍信息增益、Gini、信息增益率的,上面介绍过熵及其相关概念,地址为:https://blog.csdn.net/roguesir/article/details/76619919。这篇文章从另外的角度详细介绍熵、联合熵、条件熵、互信息、相对熵、交叉熵、信息增益等信息,为后面介绍最大熵模型做铺垫。下面进行详细介绍:
熵的概念理解
熵(Entropy)最初在热力学中提出,后由香农引入信息论中,成为一个重要物理量,在机器学习中,经典算法如决策树、随机森林等算法都涉及熵的概念。
信息量
信息量作为信息的度量,可以用来衡量熵的定义,设
p(xi)
表示
xi
发生的概率,则信息量可以表示为:
h(xi)=−logap(xi)=loga1p(xi)(1)
其中,a值常取2,表示比特,即非0即1,由此可知,信息量与概率成反比,可以理解为:事件发生概率越高,含有的信息量就越低,事件就越寻常易见。
熵的定义
熵在热力学熵用来描述物质的混乱程度,用来衡量不确定性,也就是说,物质越混乱,不确定性越大,熵值越大。
同步到信息论中,事件发生的不确定行越大,则熵越大。例如:掷骰子,六个面机会均等,因此投一次得到的点数不确定性最大(因为每个点数的概率都是六分之一),因此此时熵最大;再如:敲代码时候打错一个词,编译时出问题的概率为1,是一个确定事件,因此此时熵最小。
熵是信息量的期望,公式如下:
H(X)=−∑i=1np(xi)logap(xi)=∑i=1np(xi)loga1p(xi)(2)
其中
loga1p(xi)
表示信息量,
∑ni=1p(xi)loga1p(xi)
则表示信息量的期望,反应不确定性。
定义熵时,约定:
limp−>0+plogap=0(3)
概率和熵具有如下的性质:
0≤p≤1 and ∑p=1(4)
H(X)可以大于1(5)
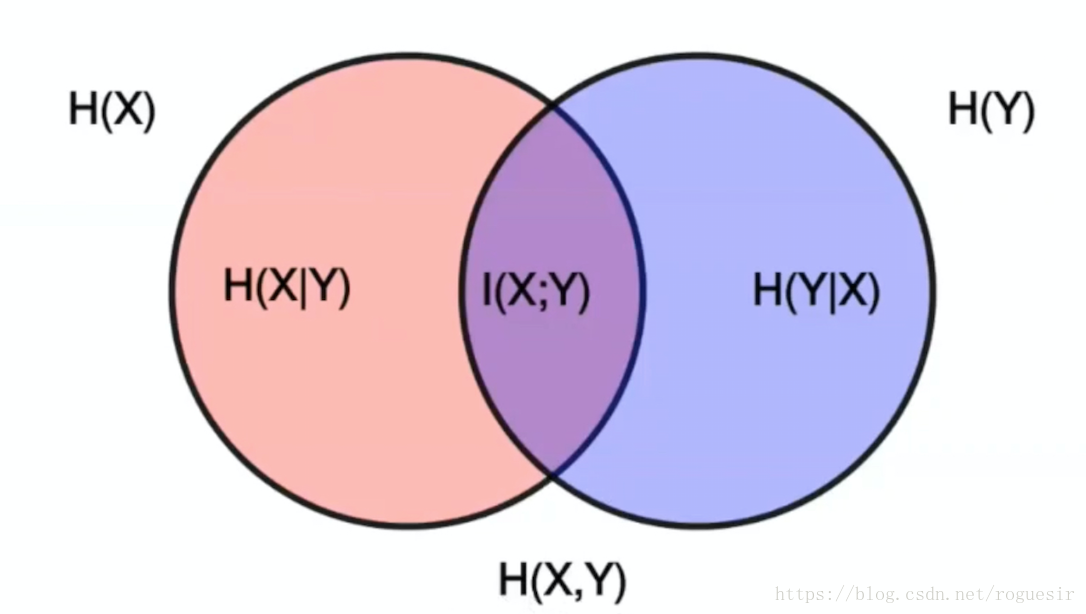
联合熵
由上面的Venn图可知,联合熵可以表示为两个事件的熵的并集:
H(X,Y)==−∑i=1n∑j=1np(xi,yj)log2p(xi,yj)∑i=1n∑j=1np(xi,yj)log21p(xi,yj)(6)(7)
可以得到如下性质:
max[H(X),H(Y)]≤H(X,Y)≤H(X)+H(Y)(8)
条件熵
通过上述Venn图可知,条件熵实际上是联合熵与熵的差集,也可表示为熵与互信息的差集,具体如下:
H(X|Y)==H(X,Y)−H(Y)H(X)−I(X,Y)(9)(10)
具体的推到过程如下:
H(Y|X)===∑i=1np(xi)H(Y|X=xi)−∑i=1n∑j=1np(xi)p(yi|xj)log2p(yi|xj)∑i=1n∑j=1np(xi,yj)log2p(xi)p(xi,yj)(11)(12)(13)
互信息
上面提到了互信息,互信息是用来表示变量间相互以来的程度,常用在特征选择和特征关联性等方面,公式如下:
I(X,Y)=−∑i=1n∑j=1np(xi,yj)log2p(xi,yj)p(xi)p(yj)(14)
互信息与相关性
ρ
相关,
ρ
用来描述线性相关性,互信息用来描述非线性相关性,其中:
ρ=cov(x,y)var(x)‾‾‾‾‾‾√var(y)‾‾‾‾‾‾√(15)
相对熵(KL散度)
相对熵用来描述像个分布之间的差异,在GAN上获得了广泛应用。
KL(p||q)=∑i=1np(xi)log2p(xi)q(xi)(16)
其中,p,q表示两个分布,易知:
KL(p||q)≠KL(q||p)(17)
KL散度越大,两个分布间的差异越明显,并且:
KL(p||q)≥0(18)
对于式(18),可以通过如下证明:
交叉熵
交叉熵常用在深度学习中目标函数优化。
CH(p,q)====−∑i=1np(xi)log2q(xi)−∑i=1npilog2pi+∑i=1npilog2pi−∑i=1npilog2qiH(p)+∑i=1npilog2piqiH(p)+KL(p||q)(19)(20)(21)(22)