交叉熵(Cross-Entropy)
交叉熵是一个在ML领域经常会被提到的名词。在这篇文章里将对这个概念进行详细的分析。
假设X是一个离散型随机变量,其取值集合为X,概率分布函数为p(x)=Pr(X=x),x∈X我们定义事件X=x0X=x0的信息量为:
I(x0)=−log(p(x0)),可以理解为,一个事件发生的概率越大,则它所携带的信息量就越小,而当p(x0)=1时,熵将等于0,也就是说该事件的发生不会导致任何信息量的增加。举个例子,小明平时不爱学习,考试经常不及格,而小王是个勤奋学习的好学生,经常得满分,所以我们可以做如下假设:
事件A:小明考试及格,对应的概率P(xA)=0.1,信息量为I(xA)=−log(0.1)=3.3219
事件B:小王考试及格,对应的概率P(xB)=0.999,信息量为I(xB)=−log(0.999)=0.0014
可以看出,结果非常符合直观:小明及格的可能性很低(十次考试只有一次及格),因此如果某次考试及格了(大家都会说:XXX竟然及格了!),必然会引入较大的信息量,对应的I值也较高。而对于小王而言,考试及格是大概率事件,在事件B发生前,大家普遍认为事件B的发生几乎是确定的,因此当某次考试小王及格这个事件发生时并不会引入太多的信息量,相应的I值也非常的低。信息量就是说:概率越大,则携带的信息量就越小,概率越小,则携带的信息量就越大!
2.什么是熵?
那么什么又是熵呢?还是通过上边的例子来说明,假设小明的考试结果是一个0-1分布XA只有两个取值{0:不及格,1:及格},在某次考试结果公布前,小明的考试结果有多大的不确定度呢?你肯定会说:十有八九不及格!因为根据先验知识,小明及格的概率仅有0.1,90%的可能都是不及格的。怎么来度量这个不确定度?求期望!不错,我们对所有可能结果带来的额外信息量求取均值(期望),其结果不就能够衡量出小明考试成绩的不确定度了吗。
即:
HA(x)=−[p(xA)log(p(xA))+(1−p(xA))log(1−p(xA))]=0.4690
对应小王的熵:
HB(x)=−[p(xB)log(p(xB))+(1−p(xB))log(1−p(xB))]=0.0114
虽然小明考试结果的不确定性较低,毕竟十次有9次都不及格,但是也比不上小王(1000次考试只有一次才可能不及格,结果相当的确定)
我们再假设一个成绩相对普通的学生小东,他及格的概率是P(xC)=0.5P(xC)=0.5,即及格与否的概率是一样的,对应的熵:
HC(x)=−[p(xC)log(p(xC))+(1−p(xC))log(1−p(xC))]=1
其熵为1,他的不确定性比前边两位同学要高很多,在成绩公布之前,很难准确猜测出他的考试结果。
可以看出,熵其实是信息量的期望值,它是一个随机变量的确定性的度量。熵越大,变量的取值越不确定,反之就越确定。
对于一个随机变量X而言,它的所有可能取值的信息量的期望(E[I(x)]就称为熵。
X的熵定义为:
H(X)=−∑p(x)logp(x)如果p(x)是连续型随机变量的pdf,则熵定义为:
H(X)=−∫p(x)logp(x)dx
为了保证有效性,这里约定当p(x)→0时,有p(x)logp(x)→0, 极限定理。
当X为0-1分布时,熵与概率p的关系如下图:
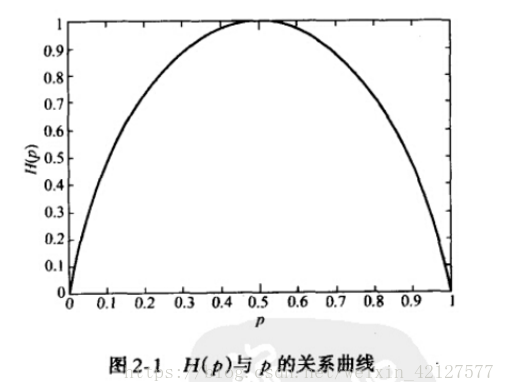
总结:熵可以理解为不确定度,是所有信息量的累加,如果发生的概率越接近0.5,则熵就越大,接近1,不确定度越大。反之,如果,发生的概率越接近1或者0,则熵就越小,接近0,不确定度越小。