这篇文章写得很好:https://blog.csdn.net/tsyccnh/article/details/79163834
下面自己做个总结。
假设X是一个离散型随机变量,其取值集合为C,概率分布函数p(x)=Pr(X=x),x∈C,则定义事件X=
x
i
的
信息量
为:
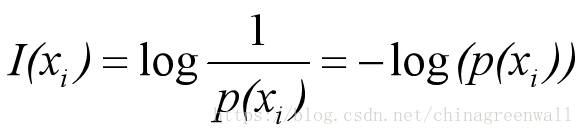
上式有两个含义:
1、当事件发生前,表示该事件发生的不确定性;
2、当事件发生后,标是该事件所提供的信息量
信息量的单位取决于对数所取的底,若以2为底,单位为比特,以e为底,单位为奈特,以10为底,单位为哈特。
当越不可能的事件发生了,我们获取到的信息量就越大。越可能发生的事件发生了,我们获取到的信息量就越小。所以信息量应该和事件发生的概率有关。
熵用来表示所有信息量的期望,即:
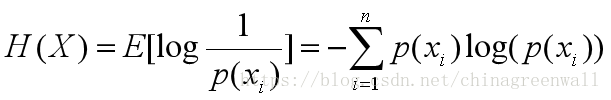
熵是从整个集合的统计特性来考虑的,它从平均意义上来表征信源的总体特征。
信息熵具有以下两种物理含义:
1、表示信源输出前信源的平均不确定性
2、表示信源输出后,每个符号所携带的平均信息量
相对熵又称KL散度,如果我们对于同一个随机变量 x 有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异。
在机器学习中,P往往用来表示样本的真实分布,Q用来表示模型所预测的分布。
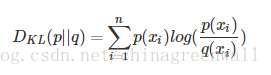
n为事件的所有可能性。
KL散度的值越小,表示q分布和p分布越接近
交叉熵
对式KL散度计算公式变形可以得到
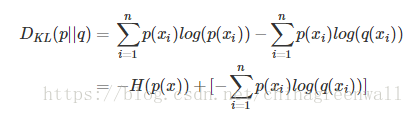
等式的前一部分恰巧就是p的熵,等式的后一部分,就是交叉熵:
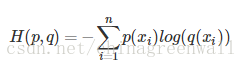
在机器学习中,我们需要评估label和predicts之间的差距,使用KL散度刚刚好。由于KL散度中的前一部分-H(p(x))不变,
故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用用交叉熵做loss,评估模型。