数据挖掘-因变量连续的预测评价指标
因变量连续的准确率指标探究
在之前文章的内容中,我们探讨了衡量机器学习准确率的指标,比如auc指标、精确率、召回率等。从因变量的角度来说,那些指标其实是衡量因变量为离散变量的情况下使用的,从预测结果中统计预测正确和错误的数量去构建指标,从而达到预测效果是否准确的判定。但是当因变量为连续变量的时候,预测的结果不太可能刚好和结果相同,比如身高178厘米,通过某个预测模型得出身高177.4厘米,只能说预测的结果和实际结果很接近,但很难做到刚好相等,因此就需要一些新的模型准确率的指标,这些指标是专门针对因变量连续的问题而建立的。下面我们来介绍几个常用的针对因变量连续模型的预测准确率评判指标,分别是RMSE 、MAE、MAPE这三个常见指标。
首先是RMSE这个指标,该指标的公式如下:
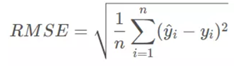
其实RMSE的中文含义就是均方根误差,Root Mean Squard Error,简称RMSE。它的本质是通过衡量预测值和因变量真实值的差值的平方和,然后对平方和求平均值再开根号,得到RMSE的值,RMSE的值容易受到异常值的影响,如果有些预测值结果偏大,通过平方和的放大后会加大RMSE的值,最终影响了结果,所以该指标不是最理想的因变量连续模型的预测指标。
其次是MAE这个指标,该指标的公式如下:

而MAE的中文含义就是平均绝对误差,Mean Absolute Error,简称MAE。它的本质是用预测值和因变量真实值的绝对值误差之和,然后对这个和求平均值,得到MAE的值,MAE相较于RMSE的值有一个优点,就是受异常值影响较小,当预测值和实际值差距较大的时候,MAE受到的影响不大,但是MAE的缺点在于,受到因变量实际的数据分布的影响。举个例子,如果在人群中有婴儿、中年女人、青年男子篮球队员这三类人群,要预测他们的身高,显然婴儿和青年男子篮球队员的身高是差很多的,如果3个婴儿的真实身高是50厘米,预测值是49厘米,那么预测差距不大,但是5个青年男子篮球队员身高是210厘米。预测的值是195厘米,那么这个时候由于因变量本身的数据分布问题,导致青年男子篮球队员的身高值预测差值较大而影响了总体MAE值。
然后是MAPE这个指标,该指标的公式如下:
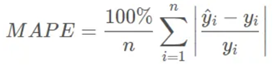
MAPE中文含义是平均绝对百分比误差,Mean Absolute Percentage Error,简称MAPE。MAPE是在MAE的基础上,分母除了一个因变量值,然后乘了100%,其实就是通过百分比的形式看模型的预测效果。MAPE想比MAE要更加客观,数据分布或者异常值的存在都无法影响MAPE的值,但是MAPE有一个小问题,就是当因变量取值有0存在时,会使得公式无法使用,因为分母不能是0,该指标也是竞赛中最常用的衡量指标,需要初学者密切关注该指标的含义。
下面将通过一个例子来说明和比较三种指标的值和差异,有一群人的真实身高和模型预测身高如下,单位是厘米:
| 个体 | 甲 | 乙 | 丙 | 丁 | 戊 | 己 | 庚 | 辛 | 壬 | 癸 |
|---|---|---|---|---|---|---|---|---|---|---|
| 真实身高 | 50 | 49 | 51 | 165 | 161 | 168 | 201 | 210 | 218 | 209 |
| 预测身高 | 50 | 50 | 50 | 166 | 162 | 170 | 205 | 213 | 235 | 212 |
| 绝对值差 | 0 | 1 | 1 | 1 | 1 | 2 | 4 | 3 | 17 | 3 |
| 差平方和 | 0 | 1 | 1 | 1 | 1 | 4 | 16 | 9 | 289 | 9 |
那么这群人的三种预测值分别是:
RMSE= 5.753
MAE= 3.3
MAPE= 1.907%
所以根据上表我们可以发现MAPE确实是最为合理的衡量指标,不会受到数据分布的影响和数据异常值的影响。RMSE显然受到了倒数第二个预测值的影响,显得偏大。
总的来说,对于因变量是连续的时候,相比于RMSE和MAE指标,MAPE的评价是最为客观的,所以竞赛时经常使用MAPE作为衡量不同模型的预测效果。而在因变量是离散的时候,可以使用AUC值这个指标对模型进行准确率的衡量。
