行人重识别之cross domain
Self-Training With Progressive Augmentation for Unsupervised Cross-Domain Person Re-Identification (ICCV2019)
cross domain:
很多reid的算法都是针对用同一个数据库训练和测试,这在现实生活中意义不大。所以,如何使得在A场景(数据库)下训练的模型,在B场景(数据库)中取得较好的效果是具有研究意义的。或者利用A(比如常用的数据库)中的有标签数据训练,再用B(比如现实世界的海量数据)中无标签数据调整模型。以上都属于cross domain问题。最近的博客将重点研究这一问题。
以上的A和B通常被称为Source和Target。这篇文章的做法就是利用Source中的数据和标签进行监督学习,预训练模型。再使用Target中的数据,通过无监督学习调整模型。整体框架如下图所示。
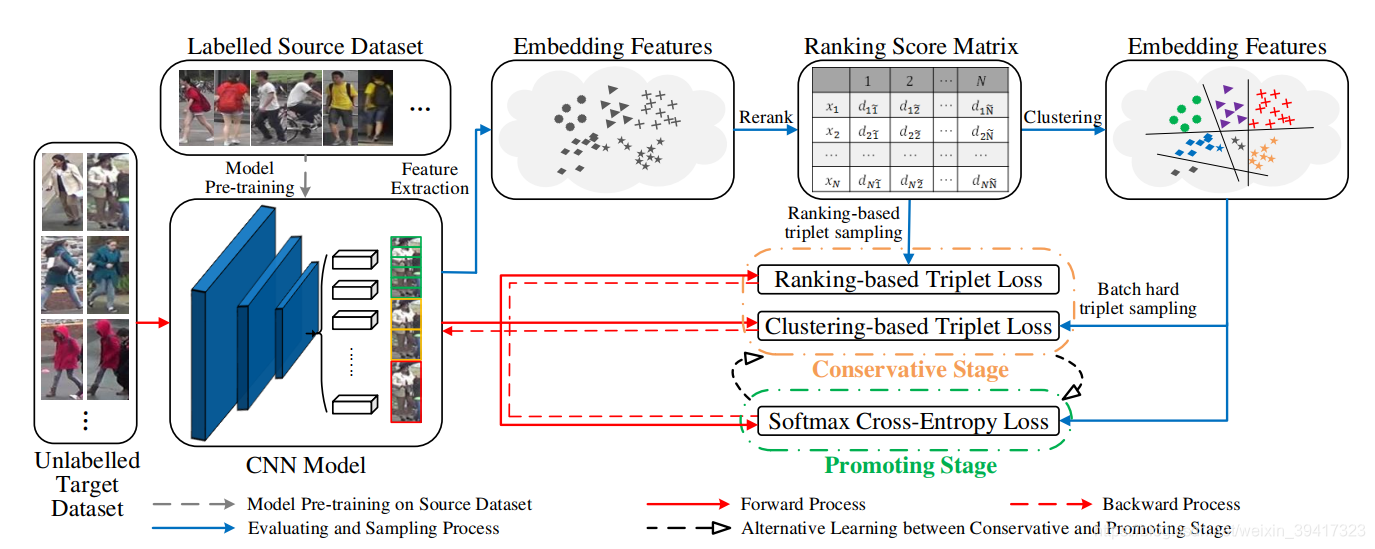
可以看出,算法分为了两个阶段:Conservative Stage和Promoting Stage。分别来看一下。
Conservative Stage:
使用在Source上预训练的模型提取Target的feature。
计算各个图片feature之间的Jaccard距离并进行rank,从而生成rank矩阵。即图中的ranking score matrix。
接下来联合使用以下两个损失函数:clustering-based triplet loss (CTL)和ranking-based triplet loss (RTL),两者都是三元组损失函数,只是细节有一些差异。
CTL:根据rank矩阵直接使用聚类算法,将target分为若干类。然后使用最难三元组损失。
RTL:举个例子比较方便解释:比如给定一张图像,根据rank结果排列了许多图像。从前10张中随机选择一个和该图像作为positive pair ,从11-20张中随机选择一个图像作为negative pair。然后进行三元组损失。在细节上有一些小改动,如下:
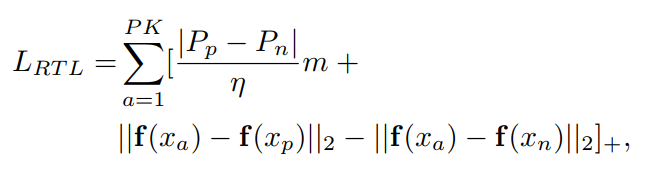
其中P是采样的类别数,K是每一类采样的样本数,pp和pn分别代表上述选择的两张图像的位置,比如7和15。这就导致三元组中的margin(m)是可变的。η和上述的10对应。
Promoting Stage:
三元损失函数的约束力不够,所以在这个阶段中引入了交叉熵损失。引入交叉熵函数后会增加全连接层,而每一次进入Promoting Stage的分类数都不同(因为模型在动态变化,导致分类数也会不同),所以每一次全连接层都需要重新初始化。
初始化方法:
举例说明,比如特征向量是256维,最后分为100类,那么全连接层的参数就是256*100。将每一类的特征向量平均,就得到了100个256维的特征向量。然后用以上特征向量初始化全连接层。作者的解释是,与其随机初始化,还不如用一些已知的经验初始化,这样容错率也高一些。虽然效果好,但是感觉这里有些牵强。还望大佬在评论区指正。
最后,交替使用两个stage,完成模型的训练。
总结:发现一条规律,在行人重识别中(其它任务或许也是),根据客观规律,使用一些动态训练的思想,往往会有较好的效果。
完
欢迎讨论 欢迎吐槽
