行人重识别之cross domain
Cross-Dataset Person Re-Identification via Unsupervised Pose Disentanglement and Adaptation (ICCV2019)
原文链接
这篇文章从图像风格迁移的角度进行了cross domain,用到了生成对抗网络(GAN),对GAN不熟悉的朋友可以参考这篇文章,让你两分钟对GAN有初步的认知。
言归正传,这篇文章的风格迁移主要是针对行人的姿势。在这个过程中,模型学习到了行人与姿态无关的特征,从而更具有鲁棒性,最终提升了cross domain的效果。与以往直接介绍算法不同,这次换一个叙述方法,一步一步按照作者的思路构建出文章算法的框架。
为了对行人进行风格迁移,需要提取出行人的视觉特征向量和姿态特征向量。而且,根据行人的关键点map提取姿态特征向量效果更好。于是有了框架的第一个部分:

S和T分别代表source和target,p和c分别代表姿态维度和视觉维度。我们需要对Ec进行约束,否则其生成的特征向量没有足够的区分度。即图中的re-ID loss。利用了三元组损失函数和MMD。
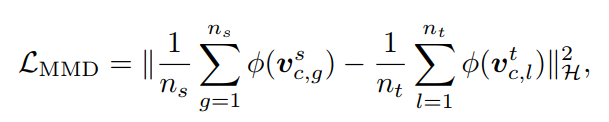
有了特征向量,我们就可以使用GAN生成对应的图像。因为是风格迁移,所以我们希望生成s到t的图像和t到s的图像。所以需要两个生成器Gs和Gt,分别对应s和t。为了对两个生成器增加约束,我们有一个容易忽略的条件可以使用:用Gs和Gt分别进行s到s和t到t的图像重建任务,最后用L1损失计算重构误差,这样就会增强对模型的约束力。另外,GAN中当然也会有判别器,用它来判断迁移的图像的真假,这是另外一个约束。所以,综上所述,我们用Gt的结构举例:
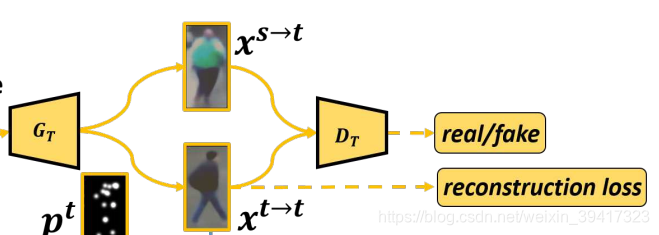
生成t->t时,输入的是第一步target的特征向量,生成s->t时,输入的是第一步source的特征向量。
开头提到,文章希望可以学习到与姿态无关的特征向量,对应第一步中的Vc。那么我们需要再增加一层约束。这时候想到,source是有标签的,如果我们让同一个人不同图像的Vc和同一个姿态的特征向量Vp的结合输入到Gs中,让它们生成的图像一样,那么在训练的过程中,同一个人不同姿态的Vc将慢慢靠近。综上所述,Gs如下所示:
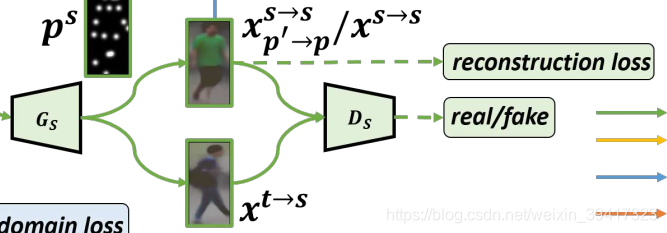
其中上面的部分就是生成了两张图像,与上述对应。
说到这,细心的读者会发现,我们还没有对第一步中的Ep增加约束。所以我们可以引入一个判别器Dp。输入是关键点map和对应的图像,图像分为真实的和生成的,使用Dp对其真实性进行判断。这样,在反向传播的过程中,就会对Ep进行约束。如下图所示(蓝色部分):

最后,文章的总体框架如下所示,其中domain loss代表了和GAN有关的损失函数:
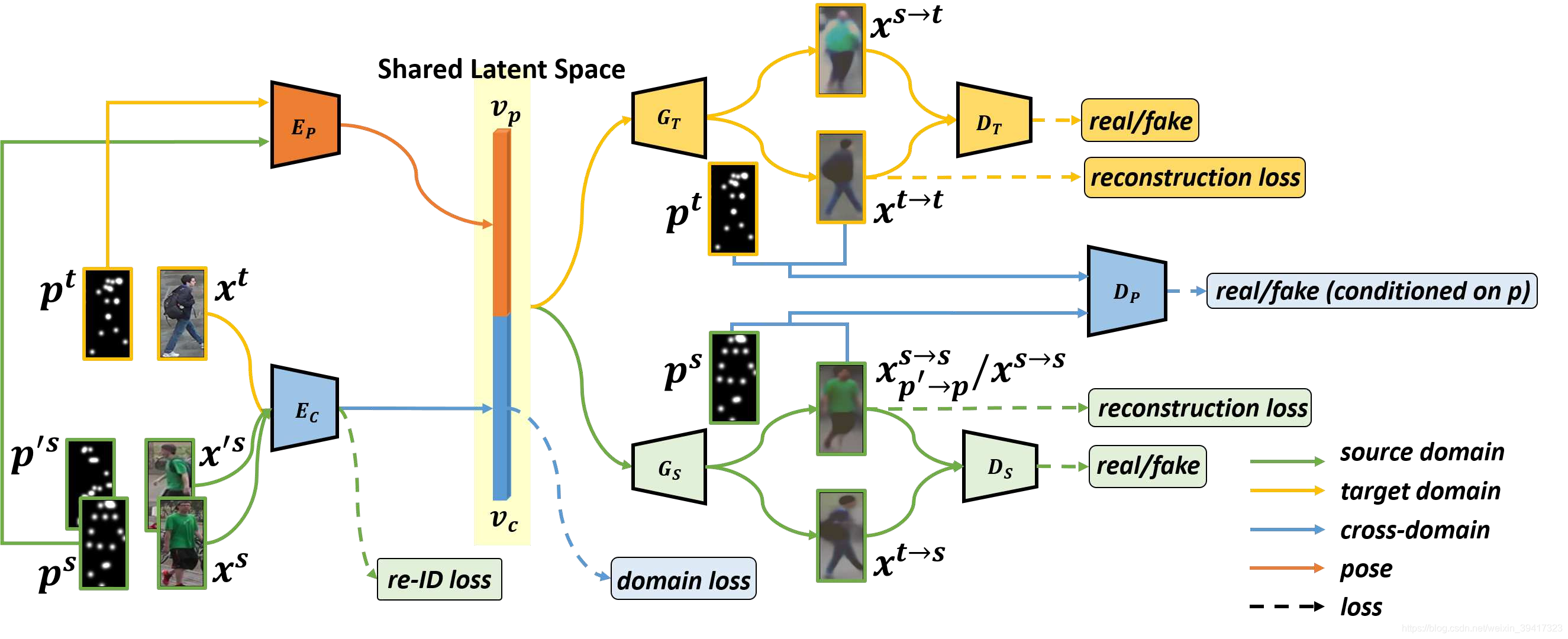
之前有过这种想法,但是当我把框架图画出来的时候,感觉自己单打独斗的话,这种复杂网络我可能永远也调不好。所以对文章的代码十分期待!
总结:这次的博客改变了写法,就是为了和大家分享搭网络的思路。所以,从问题的本源出发,一步一步构建并细化网络才是正确的设计算法的方式。最后,祝愿各位超参调节工程师们调参顺利,哈哈。
完
欢迎讨论 欢迎吐槽
