行人重识别之cross domain
Transferable Joint Attribute-Identity Deep Learning for Unsupervised Person Re-Identification (CVPR2018)
一篇关于cross domain的文章,发现这类文章有一个相似的规律,即学习行人更具本质的特征。这样在cross domain的时候,这些特征同样适用。比如上一篇文章提到,学习分块图像的特征,这其实就从某种程度上减少了行人姿态(也可以说是摄像头视角)、杂乱的背景等因素的影响。这篇文章就利用了行人的属性信息。因为和行人的身份不同,属性信息在cross domain后同样适用。
这篇文章的内容比较易懂,我们通过算法框架图对该算法进行介绍。最后讨论一下内在思想。
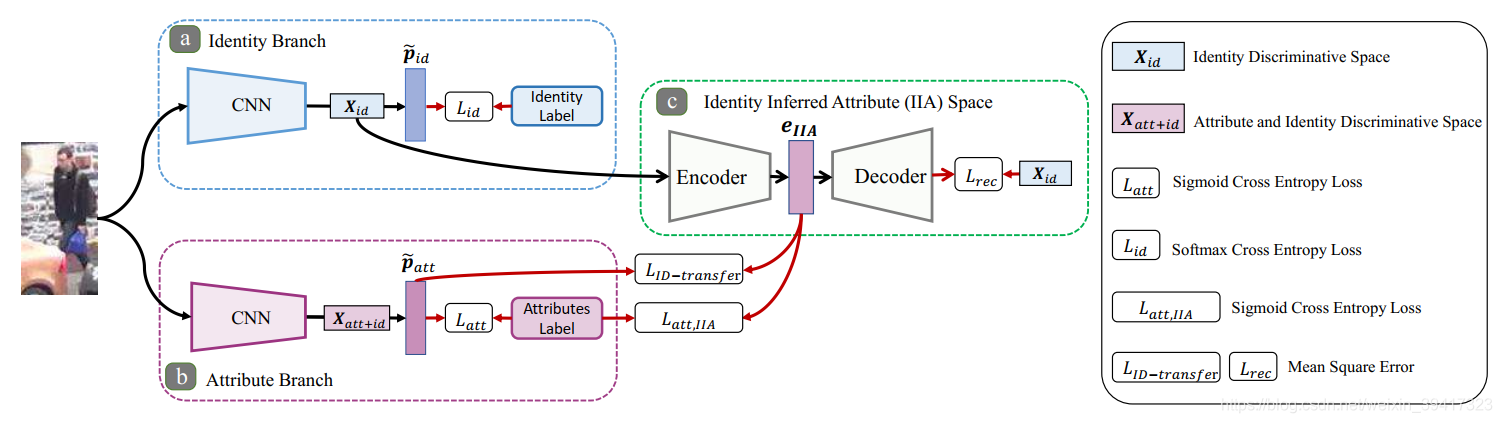
使用Source数据库,训练身份标签分支(蓝色)和属性分支(紫色),都是使用了交叉熵损失。比如图像有m类属性信息,那么粉色分支的交叉熵损失就将m个损失相加。
重点说一下绿色的部分,是一个自编码器网络,编码器和解码器分别是三个全连接层。编码器生成的eIIA的维度为m,和上述的m类属性信息相对应。自编码器网络的输入是蓝色分支的特征向量。使用三个损失函数对其进行约束。
重构损失:
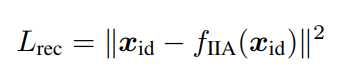
即自编码器输出与输入的均方误差。
迁移损失:
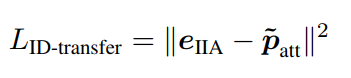
patt是对m类属性的预测,所以也是m维,对两者的差异性进行惩罚。
预测损失:
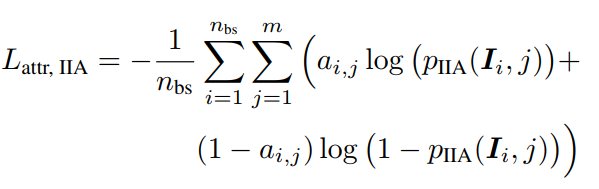
nbs是batchsize。直接使用eIIA对m类属性进行预测的损失。
看到这大家就会明白,使用身份标签训练得到的特征向量,经过自编码器和以上损失,最终实现了属性的预测功能。在joint learning的过程中,身份和属性维度的信息就会逐渐融合。因为这种共同约束体现在图中的紫色和绿色之间(根据图中的箭头可以看出),所以紫色分支从原来的属性维度逐渐变成了身份-属性维度。
在使用target数据库进行迁移的时候,用紫色分支预测target中图像的属性标签(soft label),然后使用该标签对紫色和绿色部分进行进一步的训练。最后的测试只使用紫色分支。
迁移的意义如下图所示:
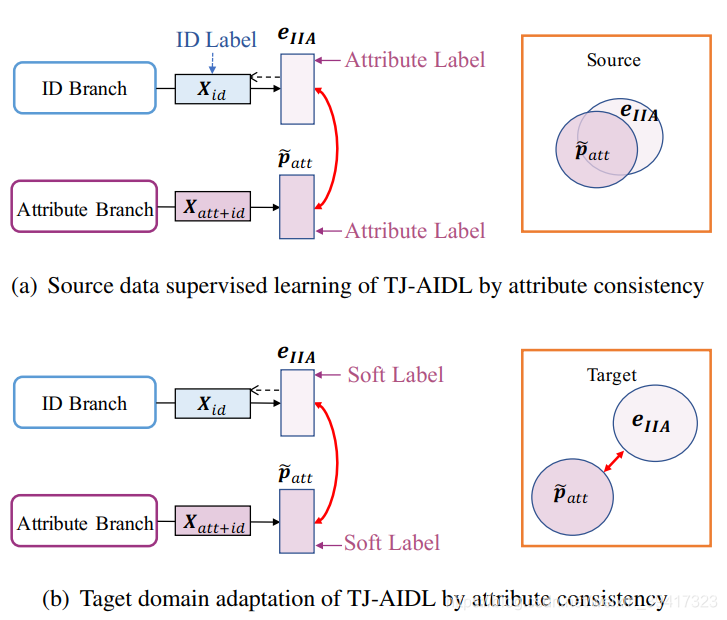
在source上训练完后,eIIA和patt的差距不大了。但是换个数据库,两者的差异性又体现出来。所以要进行迁移,使得两者不断靠近。
对训练过程不清晰的朋友们可以看看下图的算法流程。

总结:通过不同功能网络的结合训练,实现信息的交融是个不错的想法。针对cross domain问题,不能依赖于source的身份标签,核心思想是从另外一个角度学习到更本质的特征。当你找到这个角度的时候,或许就已经赢了一半。
完
欢迎讨论 欢迎吐槽
