行人重识别之cross domain
Asymmetric Co-Teaching for Unsupervised Cross-Domain Person Re-Identification (AAAI 2020)
原文链接
代码连接
这篇文章为cross domain问题提供了一个新思路:在使用聚类算法给target数据库打伪标签的时候,会存在一些离群点(outliers),即这些图像特征不是很明显,所以不属于任何一类。大多数人的做法是直接放弃这些图像。本文的重点在于如何利用这些图像进一步提升cross domain的效果。
算法的前两步和其它算法类似,简单说明:
- 使用交叉熵损失和三元组损失在source上进行预训练。
- 使用预训练模型提取target图像的特征向量并根据特征向量进行聚类。根据聚类结果给图像打标签(这里不包括outliers)。在此基础上对1中的模型进行微调,只使用了三元组损失。
接下来,是文章的重点:如何利用好outliers?
先来思考,什么样的图像容易成为outliers呢:特征不明显的图像,比如10张小明的图像,9张角度很正、背景不乱、没有遮挡,即特征明显。1张或者角度不好、光线不好,或者存在遮挡、图像不完整等。那么这1张图像就很容易成为outlier。下图是几个outlier的例子。

所以,即使强行根据聚类的距离对这些图像打上伪标签进行训练,对模型来讲也是一件十分困难的事情。所以,作者使用了一种过渡的思想。比如上面五张图像,最左边的特征相对明显,所以先用该图像进行训练。当模型适应了该图像,我们就可以赋予模型更具挑战性的outliers。这样,模型不断进步,最后就可以使用全部outliers进行训练。
如何确定outliers的难易程度?
给outliers打上伪标签,输入模型。损失越大,即说明该outlier的训练难度越大。
基于以上分析,我们来看一下文章算法的总体框架:
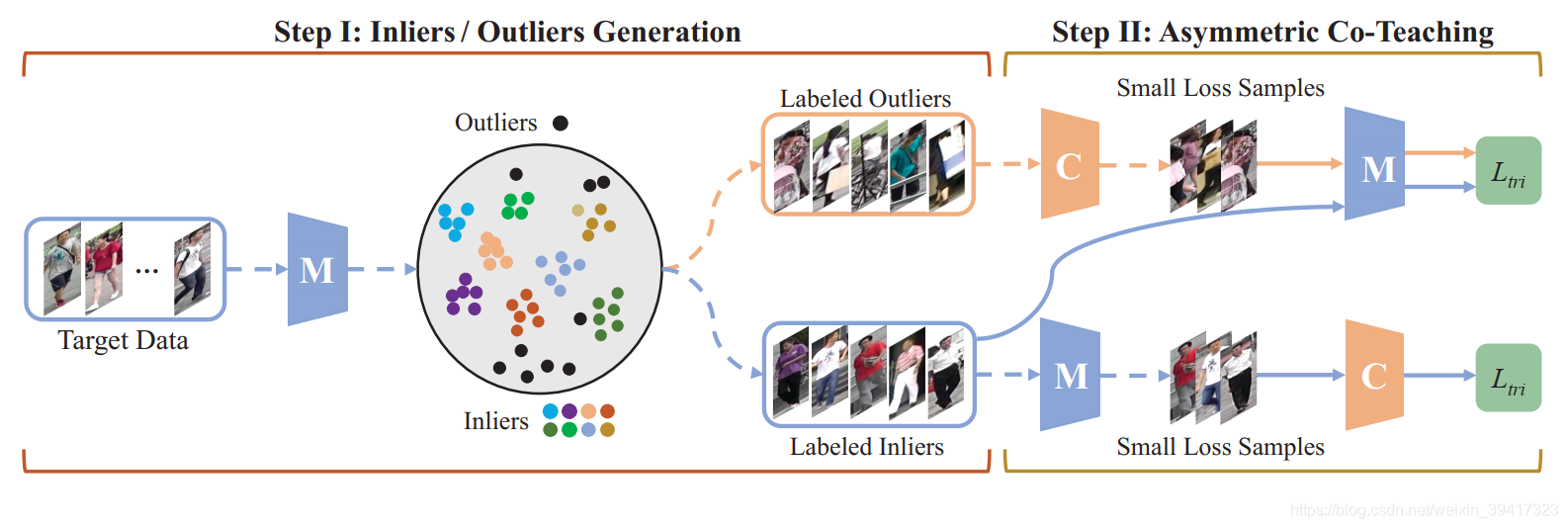
虚线代表没有反向传播,只用来提取特征。实线代表训练过程。
根据上述的前两步训练,我们可以获得一个模型进行下一步的训练。图中的M和C均是该模型,只不过在接下来的训练过程中,两者的训练方式不同。最后的测试模型是M,C用来辅助训练过程。
使用M提取特征,根据聚类算法确定inliers和outliers。C和M分别判断outliers和inliers中比较简单的图像。然后再把简单的图像反过来分别输入到M和C进行训练。另外M的训练图像也包含所有的inliers。损失函数使用了三元组损失。
大家可能有点晕,仔细看一下框图和上一段话,然后我们一起来分析一下其中的思想:
我们希望M能够逐步学习outliers中的信息,所以需要对outliers的难易程度进行判断。但是我们不能使用M本身进行判断,因为outliers本身就是由M选出来的,使用M判断难易程度过于片面。所以,我们需要获得一个具有基本分辨能力的辅助模型,也就是图中的C,用它来判断outliers的难易程度。可是,M越来越强,C的难易程度对于M可能会失去意义。所以,把M认为简单的图像,输入到C中,使C的性能提高。这样,在交替训练的过程中,M和C就能共同进步。最后,充分利用所有的outliers。
总结:本文的思想和对抗思想有异曲同工之处,在共同学习的过程中,两者不断变得更加强大。也让我们看到了使用传统机器学习算法对深度学习进行辅助的优越性。
完
欢迎讨论 欢迎吐槽
