1.1 背景
无监督学习行人重识别指的是,在没有标签的情况下,将行人的查询图像与gallary图像库中进行匹配。目前,处理无监督行人重识别最主流的方式是,采用一个聚类算法产生伪标签,之后根据产生的伪标签训练一个深度神经网络。
1.2 问题
但是,使用聚类算法生成伪标签的方式,产生的伪标签带有噪声并且对聚类算法中的超参数比较敏感。
1.3 提出方案
因此,本文中,提出了一种简单但有效的基于对比学习的无监督行人重识别框架,具体地:
-
提出一种新的无监督混合对比范式,这样可以更好地利用带噪声的为伪标签数据
-
采用多粒度聚类集成策略,用来描述正样本的置信度,并且提出了一种优先级加权的混合对比损失,更好地容忍伪正样本中的噪声
2.1 整体框架
2.1.1 Hybrid Contrastive Learning(HCL)
使用instance-level的对比学习,它挖掘的是每个样本各自的自监督信息,往往忽略了样本之间的结构性和相关性信息,使用cluster-level的对比学习,虽然得到了结构性信息和相关性信息,但是这对负样本数据而言,引入了过多的额外的结构性信息,这种信息在实际应用中又是无用的。所以为了解决这个问题,本文就提出一种基于instance-level和cluster-level的混合对比学习。
HCL框架由3部分组成:用于学习卷积特征的编码器模块、用于存储所有数据特征的memory bank、用于生成伪标签的聚类模块。编码器模块本文使用的是没有全连接层的ResNet-50;对于memory bank的初始化,本文使用的使用,将经过ResNet-50后的特征进行归一化得到的。对与memory bank的更新,本文使用的是如下的计算公式:

其中,{f_x}_i表示数据x_i特征向量,{f_M}_i表示数据x_i在memory bank中的特征向量,γ就是一个动量因子,认为设定的,一般都很小。
本文采用DBSCAN作为生成伪标签的聚类算法,因为生成的伪标签带有噪声,所以提出了一种混合对比损失函数,这个损失函数混合了instance-level对比学习和cluster-level对比学习,具体的计算公式如下:

其中,, |B| 表示batch-size,<>表示矩阵内积,τ人为设定的一个常数,µ+表示{f_x}_i表示与样本x_i为正样本的所有样本的特征向量的平均值,这就属于instance-level;j /∈ ω+ 表示样本不属于ω+这个类(ω+与µ+$是相关的,前者是后者的样本中心),这就属于cluster-level。
通过这种混合对比学习,保留了正样本之间的cluster information,使得拉近了相似样本之间的距离,同时对于剩余的样本,都认为是负样本,从而拉开了与负样本之间的距离。这样做的原因是因为,有了更多的负样本,就能够提供更多的对比信息。
2.1.2 Hybird Contrastive Learning with Multi-Granularity Cluster Ensembled(MGCE-HCL)
MCGE-HCL与HCL之间不同点在于:1)因为DBSCAN这个算法对超参数比较敏感,算法的效果好坏与超参数之间的关系非常大,所以MCEG-HCL使用不同的超参数生成多粒度聚类结果,并且将获得的聚类结果编码得到一个优先级权重;2)将这个优先级权重引入到混合对比损失中,这样就可以自动探索正样本之间的置信度(置信度越大,表明样本之间越相似)。MGCE-HCL的模型框架如下所示:

-
Multi-Granularity Clustering Ensemble(MGCE)
为了补救DBSCAN对超参数敏感的问题,本文多次使用DBSCAN,并且每次的超参数d都不同,其中超参数d用一个集合表示。在每次使用不同的超参数d之后会产生一个亲和矩阵,这个矩阵中值表示任意样本i与样本j之间是否属于同一个类,如果属于同一个类,值为1,反之值为0.在经过T次DBSCAN算法之后,产生了T个亲和矩阵,之后对这T个亲和矩阵求和再平均,就得到一个优先级权重矩阵,这个矩阵中的值表示任意两个样本之间的置信度,值为0可以认为这两个样本为负样本对,值越大表示这两个样本化为同一个类的可能性就越大,是正样本的可能性就越大。
-
Priority-Weighted Hybird Contrastive Loss
基于得到的优先级权重矩阵,本文提出了一种优先级加权混合对比损失,计算公式如下:
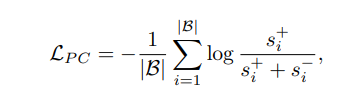
其中,|B|表示batch-size;{s_i}^+表示输入样本与正样本之间的指数相似度;{s_i}^-表示输入样本与负样本之间的指数相似度,具体地,{s_i}^+和{s_i}^-的计算公式如下:
其中,当pi,j = 0 时 ,, I(pi,j = 0)的结果为1
通过计算优先级权重的这种方式,1)MGCE-HCL对属于同一个类中的任意两个样本之间有不同的相似度,而cluster-level和HCL都认为同一个类的样本,任意两个样本之间的相似度相同;2)因为优先级权重能够描述样本的密度,所以为正样本带来更多的信息;3)对于负样本,因为HCL和MGCE-HCL都是在没有使用cluster-information的情况下,单独考虑负样本。
3. 总结
本文中,针对无监督行人重识别提出一种基于聚类集成的混合对比学习
1)提出的这种混合对比学习范式HCL,这种范式保留了正样本的集群结构性信息但是忽略了负样本之间的集群结构性信息
2)为了解决这个问题,本文进一步提出了MGCE-HCL,使用这种方法,为正样本生成了一个优先级权重矩阵,并且提出了优先级加权对比损失,使得在更大粒度的集群上可以在一定程度上减少噪声带有影响
3)在两个benchmark上进行实验,实验结果表示HCL范式的效果明显好于instance-level contrastive learning和cluster-level contrastive learning。并且提出的MGCE-HCL是目前效果最好的模型