这篇文章来自ECCV2018. 主要针对无监督的行人再识别任务,首先用3D引擎和环境渲染技术构建了一个多光照条件的虚拟行人数据集,接着用该合成数据集和其它大型真实数据集合并,共同预训练了一个模型。由于涵盖了各种光照情况,该模型具有良好的泛化性能。为了进一步提升无监督性能,该文章提出了一种域自适应技术(有约束的cycleGAN),选择和目标域的光照情况最相似的那些合成图像,迁移到目标域上,再利用迁移后的合成图像对预训练好的模型进行精调,最终大幅提升了reid的性能,超过其它无监督方法。
一. 摘要
跨监控摄像头的剧烈光照变化会使得行人再识别任务变得非常困难。当前的大型reid数据集有着非常多的行人训练样本,但是缺乏光照的多样性。因此,如果遇到没有见过的光照条件,一个训练好的模型需要进行精调才能变得有效。为了解决这个问题,本文引入了一个包含了上百种光照条件的合成数据集。具体地说,我们使用了100个虚拟人物,利用多个HDR环境图对其进行照明,从而准确建模出真实的室内和户外光照。为了在没见过的光照条件下取得更好的性能,我们提出一种新的域自适应技术,以一种完全无监督的方式利用了我们的合成数据并进行了精调。我们的方法和其它半监督和无监督方法相比,取得了很高的准确率,可以和有监督方法媲美。
二. 贡献
1.提出了一个新数据集,它包含了100个虚拟人物,并使用了140个HDR环境图进行渲染。我们展示了即使不经过fine-tuning,这个数据集也能够增强训练好的模型的泛化性能。
2.我们使用了一种新的三步式的域自适应技术,以无监督的方式提升了reid的性能。具体的说,我们使用了循环一致性迁移(cycleGAN),并增加了一个新的正则项以保证迁移前后行人身份信息不丢失。针对某一目标域迁移后的合成图像被用来fine-tune模型。
三. SyRI Dataset
要收集和标注一个涵盖所有光照条件的reid数据集的成本过高,因此本文提出采用合成数据集。构建这样一个数据集的难点在于如何创造出真实的光照条件的真实场景。我们使用高动态范围(HDR)环境图,它们可以看作是360度的真实世界的全景图,包含了准确的光照信息,能够被用来重新照亮虚拟对象并提供现实背景。该数据集的部分样本如下图所示。

1. Environment maps
如下图所示,一共采集了140张HDR环境图。具体的采集方法是,对每个场景,用鱼眼镜头的Canon相机用不同的曝光(包围式曝光,bracketed exposures)和不同的角度拍摄多张图像,然后用某商业软件合成,最后得到一张360度的HDR环境图。

2. 3D virtual humans and animations
使用Adobe Fuse CC这一软件来制作虚拟的人物3D模型。如下图。

3. Rendering
使用Unreal Engine 4来实现实时渲染速度。对这方面不太了解,具体做法查阅原文。
四. 方法
1. Joint learning of re-identification network
首先,研究如何学习到泛化能力强的特征表示用于reid任务。具体做法是融合所有域的图像构成一个大的数据集(CUHK03 + DukeMTMC4ReID + SyRI),用于训练CNN模型。其实就是把两个真实reid数据集和提出的合成数据集进行融合,然后从头开始训练模型。文中提到的一点是,为了学习到强判别性的泛化能力强的特征,训练的行人类别数必须远大于最终特征向量的维度,比方说,训练集包含了3000+个类别,而最后的特征层维度固定为256.
实验验证了合成数据集的确对提升泛化性能有帮助,但是和在目标域fine-tuned过的模型比起来还有很大的性能差距。文中认为有两个原因:(1)我们的数据集没有涵盖所有可能的光照条件;(2)合成图像和真实图像的分布存在差异。这启发我们使用域自适应方法来解决,也就是让合成图像看起来尽可能真实,并且最小化源域和目标域的光照条件的差异。
2. Domain adaptation

该方法分为三个部分:光照推断、域迁移、精调。具体流程是,给定来自目标域的没有标签的输入图像,我们首先通过光照推断器找出最接近于目标域光照情况的合成域S_k*. 然后,来自合成域S_k*的图像通过cycleGAN迁移到目标域,这个过程是无监督的。最后,使用迁移后的合成图像(具有身份标签)对reid网络进行精调。
Illumination inference 这一步的目的是在所有合成域中找到和目标域光照情况最接近的那种合成域S_k*,具体做法是,训练一个CNN(Resnet-18)模型来对合成数据集中的140种环境渲染图进行分类。训练好这个光照推断模型后,我们就可以将目标域的图像输入到这个模型中,出现次数最多的那个输出对应的环境渲染图即为最接近的源域光照。
Domain translation 使用cycleGAN,比较火的GAN模型,具体可查阅相关文献。

Semantic Shift Regularization 由于cycleGAN的loss没有对迁移前后的颜色分布进行约束,这可能会产生语义的偏移,例如行人身上的衣服颜色发生变化。为了避免这种情况,引入了两个新的约束项,如下所示。第一个id loss为了保证迁移前后目标域图像的变化不大。第二个mask loss为了保证行人图像前景尽可能保持不变,而背景可以自由变化。

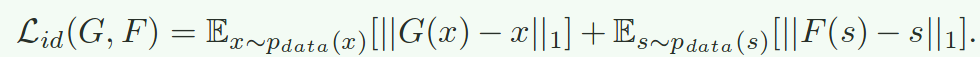

最终的loss如下:
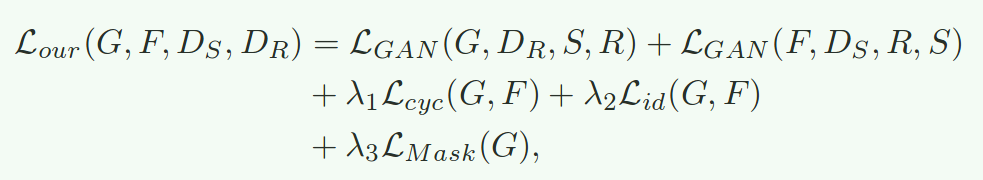
Fine-Tuning 将迁移后的合成图像用于精调reid网络。实际上,上面的域自适应操作是对每个摄像头进行的。即为每个摄像头都找到最接近的光照条件,再迁移合成图像到各个camera domain上。
最后的迁移效果如下图所示。
