行人重识别之分块无监督学习
Patch-based Discriminative Feature Learning for Unsupervised
Person Re-identification
原文链接:http://openaccess.thecvf.com/content_CVPR_2019/papers/Yang_Patch-Based_Discriminative_Feature_Learning_for_Unsupervised_Person_Re-Identification_CVPR_2019_paper.pdf
这篇文章的算法是纯粹意义上的无监督,没有使用数据库中的任何标签信息,针对的是同一个数据库。实验结果与有监督学习虽然还有一定的差距,但是至少说明了无监督学习的可行性,这对于未来的研究十分有意义。
如图所示,作者认为,虽然图像的label不同,但是它们的局部存在很多的相似性,对每一个局部的相似性和差异性进行学习,最后再将其整合在一起,各个部分互相补充,就可以进行识别。在这个过程中是不需要标签的,也就实现了完全的无监督学习。

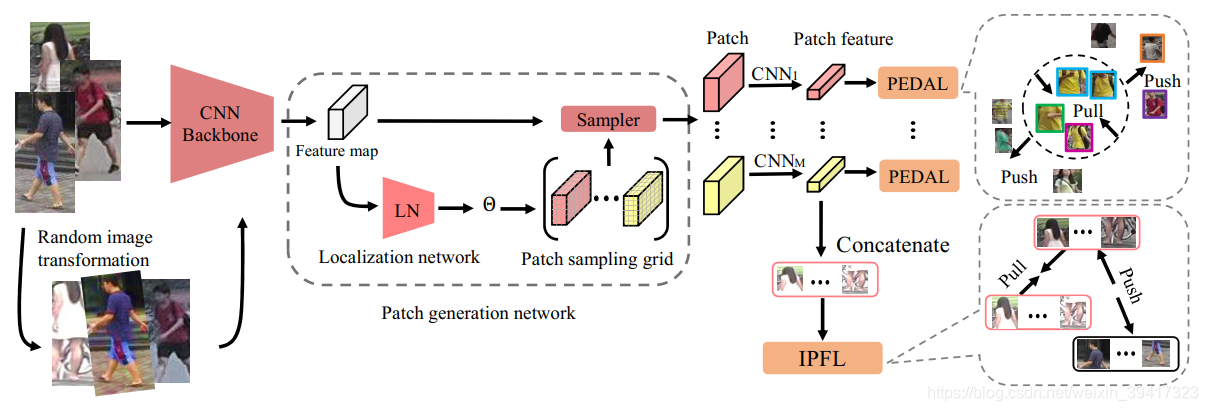
其整体框架如上图所示:
PEDAL是约束局部的损失函数,拉近相似的局部,推开不相似的局部。IPFL是约束整体的损失函数,拉近正样本对(如图左侧,对图像进行一些类似裁剪、饱和度、翻转等变换从而构成正样本对),推开负样本对。Patch generation network是在MSMT17数据库上训练的空间变换网络,对输入的图像进行分块。根据分块位置的不同分成若干个CNN分支,每一个分支对一个batchsize内的一个位置的所有图像块提取特征,然后利用上述PEDAL进行约束,同时,将不同分支的特征进行连接,构成图像整体的特征向量,利用上述IPFL进行约束。
接下来,对上述过程可能会产生的两个问题进行解释。
- 如何判断图像块是否相似?
使用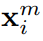 表示第i张图像的第m个图像块的特征。构建一个存储器
表示第i张图像的第m个图像块的特征。构建一个存储器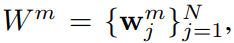 N是图像数量,小w代表之前更新的存在存储器的特征。公式如下:
N是图像数量,小w代表之前更新的存在存储器的特征。公式如下:

l是学习率,t是epoch,可以看出,使用一个epoch内提取的特征x,对w不断进行更新。在此过程中,我们计算x与存储器中每一个w的差异,从而找到最相似的w,然后使用PEDAL对其进行约束,如下所示:k表示最相似的w构成的集合。
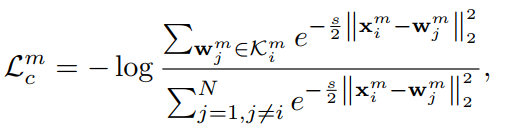
通过损失函数的约束,对存储器不断进行更新,网络就可以使相似的图像块的特征向量越来越相似。换而言之,网络就具有了识别哪些块相似,哪些块不相似的能力。 - 如何构建负样本对?
具体言之,应该是如何构建最难的负样本对,这样才能实现最好的约束。如下图所示:

将局部特征向量的连接,获得了整体图像的特征向量,从而可以计算出一个batch内图像之间的相似度。对于target计算出相似度序列,然后对排在最前面的图像计算相似度序列。如果target不在前r个里面,那么它们就是最难负样本对。
这样做的原因:图中第一行说明两个图像很相似,但不敢保证是否属于正样本对。图中第二行保证它们不是正样本对,因为target越靠前,证明两者是正样本对的概率越大(所以选择合适的r也很重要),虽然也会有漏网之鱼,但是无监督学习也只能这样了。结合这两点,就构成了最难负样本对。再结合上述变换得到的正样本对,就可以使用三元组损失函数了,即上述的IPFL。
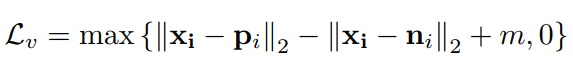
总结:使用了无监督的方式,既实现了局部的约束,也实现了全局的约束。两个人可能因为黄衣服很相似,但是该网络还可以识别裤子的样式,这就可以将两个人区分开。很新颖的方法,无监督学习在行人重识别中还是大有可为的。
完
欢迎讨论 欢迎吐槽
