行人重识别之注意力机制
Towards Rich Feature Discovery with Class Activation Maps Augmentation for
Person Re-Identification
原文链接:http://openaccess.thecvf.com/content_CVPR_2019/papers/Yang_Towards_Rich_Feature_Discovery_With_Class_Activation_Maps_Augmentation_for_CVPR_2019_paper.pdf
什么是注意力机制,即attention map?在CNN计算的过程中,对图像每一个部分的关注度是不一样的,如下所示。生成attention map: https://github.com/jazzsaxmafia/Weakly_detector

对应到行人重识别,我们不希望网络对某些部位过度关注,从而忽略一些关键信息,甚至于过度关注的部分是没意义的。为此就有了一个研究方向:注意力机制。
改善网络注意力的方法有很多,比如对注意力高的地方进行遮挡、对图像分块分别识别、行人的语义分割等。
这篇文章对注意力机制进行研究,各人认为实现流程相对简单,为我们提供了一种新思路。
改善注意力的方法:
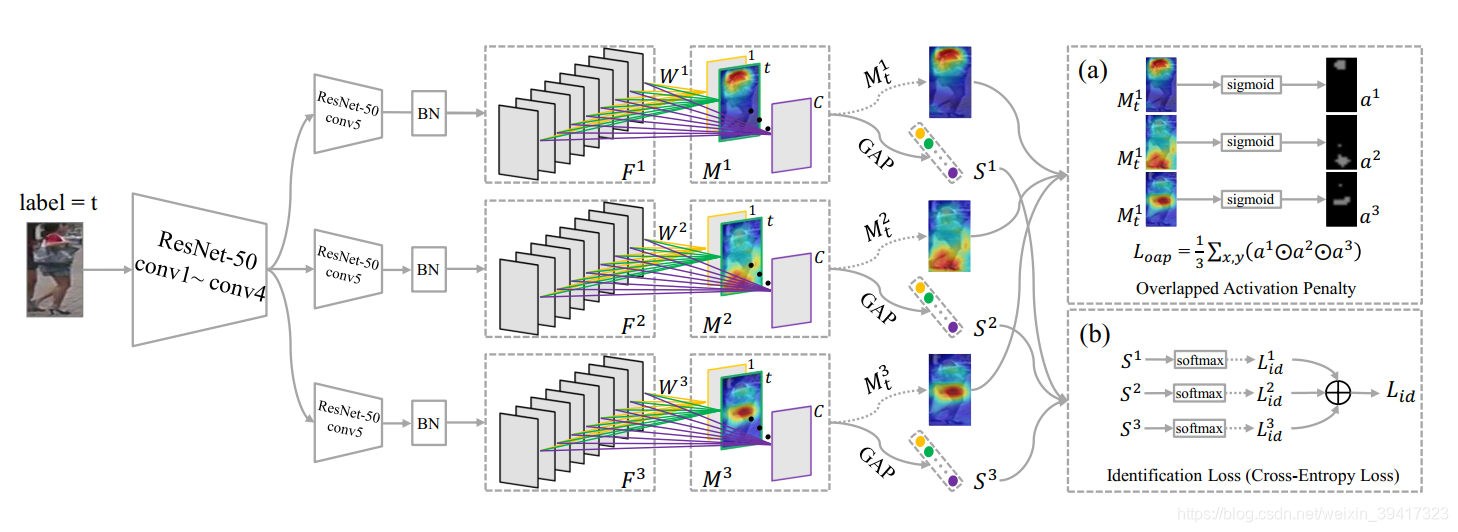
如图,网络有三个分支,conv5之前参数共享。可以看出,每一个分支可以提取出对应label的attention map和标签概率序列S。使用sigmoid激活后,对三个分支的attention map的重合度进行惩罚(如下式)。S使用交叉熵损失进行约束。整体框架就是如此简单。
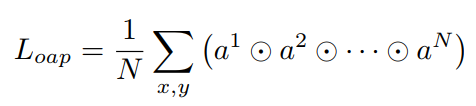
效果如下所示:
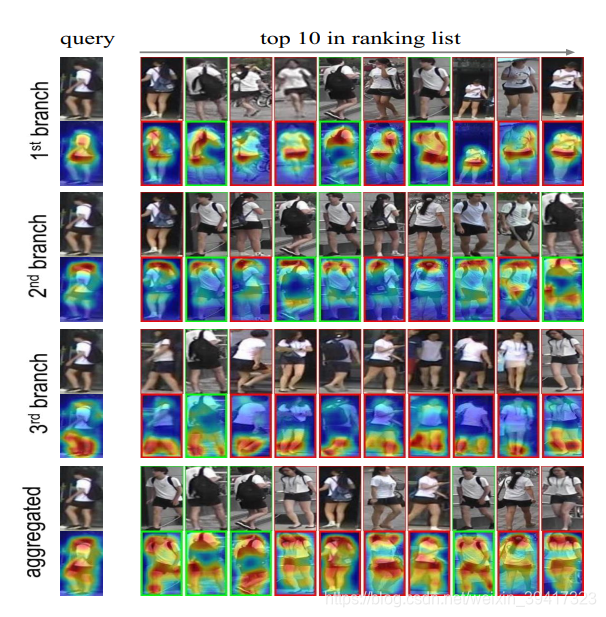
可以看出,三个分支实现了不同的关注点。在测试时,将三个特征向量进行连接(根据之前的经验,直接相加或许性能更好?)就可以实现对图像整体更好的把握。
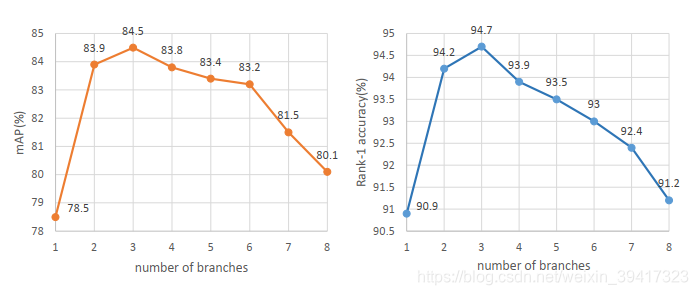
实验证明三个分支比较好,分支过多可能会使网络开始关注无用的背景信息:
另外作者还介绍了用于行人重识别的生成attention map的方法ranking activation map (RAM),个人觉得不是重点,这里就不再阐述。感兴趣的朋友可以参考原文。数学推导还是很简单的。
总结:个人很喜欢这种使用一个损失函数就可以解决某类问题的文章,非常简洁明了。一些需要做过多预处理的,比如行人关键点提取或者语义分割的,总觉得过于复杂。不知这是否是未来的发展之势。
完
欢迎讨论 欢迎吐槽
