《Unsupervised Salience Learning for Person Re-identification》论文分析
1.基础知识
- 颜色直方图(用于颜色特征的提取):它描述的是不同色彩在整幅图像中所占的比例,而不关心每种色彩所处的空间位置,即无法描述图像中的对象和物体。LAB颜色空间:可以表示自然界中任何一点的颜色。
- .SIFI算法:能够适应旋转、尺度缩放、亮度变化,可在图像中检测到关键点,是一种局部特征描述子
- CMC曲线(累积匹配特性曲线):是一个检测识别系统性能的参数,综合反映了分类器的性能。其中Rank-1识别率就是表示按照某种相似度匹配规则匹配后,第一次就能正确判断出正确标签的数目与总的测试数目之比,而Rank-1,Rank-2…组成的曲线就是CMC曲线。
2.论文分析
从论文实现的方面来看,主要分为以下几个步骤
-
1.将图片分为局部的网格(以下的操作都是对网格进行处理)
-
2.提取特征向量:(1)提取LAB颜色直方图(32bins),对L、a、b三个通道进行三个不同级别的下采样,得到3233维的颜色特征向量(2)提取SIFT:对L、a、b三个通道进行提取,将网格再次划分为44的单元,每个单元局部梯度方向量化为8个区间,获得4483维的特征向量。
最后将颜色特征向量与SIFI特征向量进行组合得到最终的组合特征向量。 -
3.带有约束的邻接搜索:对第m行n列为中心的网格块,在数据集中的(m-l,m+l)行内进行搜索,文中l设置为2。然后定义了一个相似度得分的函数:
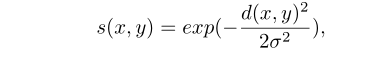
-
4.利用无监督学习的方法学习显著性:(1)k-最近邻的方法:假设数据集中有N张图片,则对于一个网格块来说,利用第3步中的邻接搜索返回N个最相似的网格块,组成一个新的数据集并按照相似度进行了排序。定义一个显著性的得分函数:
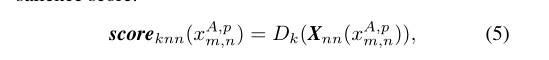
文中k取N/2,是因为论文中假设,如果一个人有这样独特的外表,那么在参考集中超过一半的人与他/她是不同的。这个得分函数计算的是第k个相似的网格与原网格的距离。(这个地方要好好理解,因为如果一个特征是显著的,那么第k个相似的一定与原网格的距离很远,因此显著性得分很高)
(2)基于某一类SVM的方法来计算显著性,这里不再赘述,也是与k-最近邻类似,不过没有了人为定义的k=N/2这个数。因此更客观一点 -
5.双向加权匹配机制:将显著性结合到密集对应中,简而言之,就是利用显著性来指导密集对应。给出了最终的一整张图片的相似度得分函数,这个函数与相似度得分和显著性得分都有一定的关系。
-
6.排序:采用CMC曲线来对最终的结果进行评估,可以看出优于之前的方法
其中较为关键的步骤为利用显著性来指导密集对应,由于带有邻接约束的搜索可以容忍较大程度的姿态以及外观的变化,因此在大视角变化下仍然有很强的灵活性。
3.结论
在这项工作中,我们提出了一个无监督的框架与显著性检测的人重新识别。在邻接约束条件下,利用块匹配来处理视点和姿态的变化。它在大视角变化的匹配中表现出极大的灵活性。人类的显著性是在无监督的情况下学习来寻找有区别的和可靠的补丁匹配。实验表明,我们的无监督显著性学习方法大大提高了人的再识别性能。
4.局限性以及改进
局限:两个人穿相似的衣服就很容易产生误判
改进:可以加入时空信息,使其与显著性一块指导密集对应。