
摘要:
本文在原来的神经seq2seq模型上进行了两种改变,用混合的pointer-generator网络,既可以通过pointing直接从原文中copy单词又保留了通过generator生成新词的能力;另外,用coverage来记录已经总结出的内容,防止重复。
1 Introduction
生成摘要一般有两种方式,extractive和abstractive,前者是直接从原文中获取段落(通常是完整的句子)来汇总成摘要,而后者是生成新的单词或短语。前者相对较简单。seq2seq的出现使得abstractive的方式变得可能,但是有几个问题:产生不准确的事实类细节、生成重复的词,以及不能很好的处理OOV。本文提出的模型旨在解决这三个问题。
2 Model
2.1 baseline seq2seq model
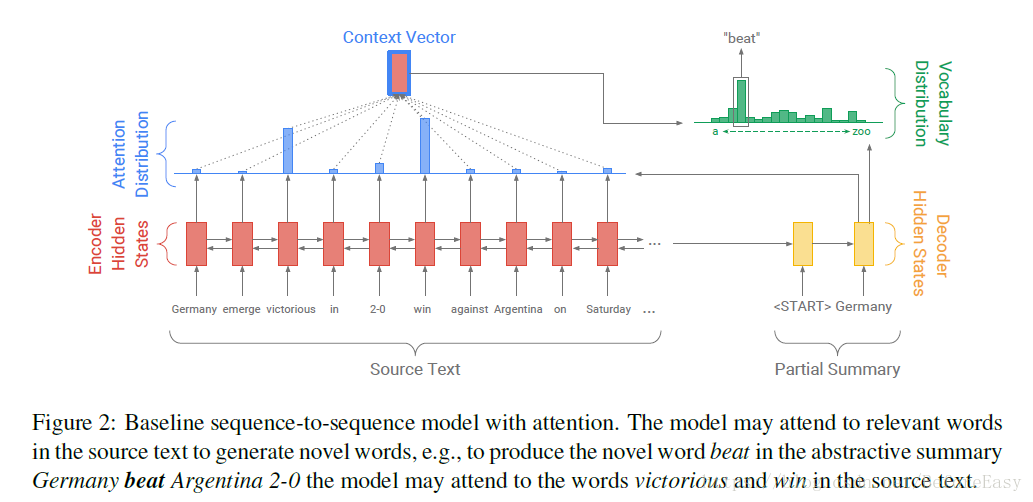
一个单层双向的LSTM作为encoder,源文本(Germany emerge victorious..)中单词被一个一个喂进encoder中,然后生成encoder hidden state hi,也就是图片中红色的长方形。
输入源文本后,解码器decoder(单层单向LSTM)生成摘要。每一步中,decoder以已经生成的摘要来更新decoder hidden state,也就是图中右边黄色长方形的部分(第一步是以特定的开始符<start>作为开始的信号)。
而decoder hidden state被用来计算注意力分布,也就是图中由黄色长方形指向蓝色的那个箭头表示的。注意力分布会告诉我们现在应该重点看哪些输入,也即是source中的词的概率分布。

此刻图中的状态可以直观的看到应该更加关注得分更高的victorious 和win。这个单纯的蓝色的注意力分布被用来生成一个encoder hidden state 的加权和,也就是图中最上方红心蓝框的小长方形,它表示的就是此刻decoder从源输入中看到的东西,也被称为context vector也就是语境向量,文中用ht*表示,而且是fixed size的:
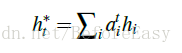
有了语境向量和之前生成的摘要(decoder hidden state),就可以来计算词汇分布,通常是一个大的vocabulary固定词汇中的概率分布,可以看到图中绿色部分a----zoo表示大词汇表中从第一个词a到最后一个词zoo,然后里面概率最大的就是beat,也就是我们要的生成的词。
具体来说这个概率是用上面的加权和连接上这一步的状态st,然后经过两个线性层,最后一个softmax来生成:
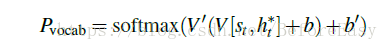

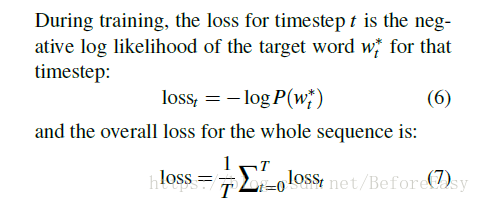
2.2 pointer-generator network
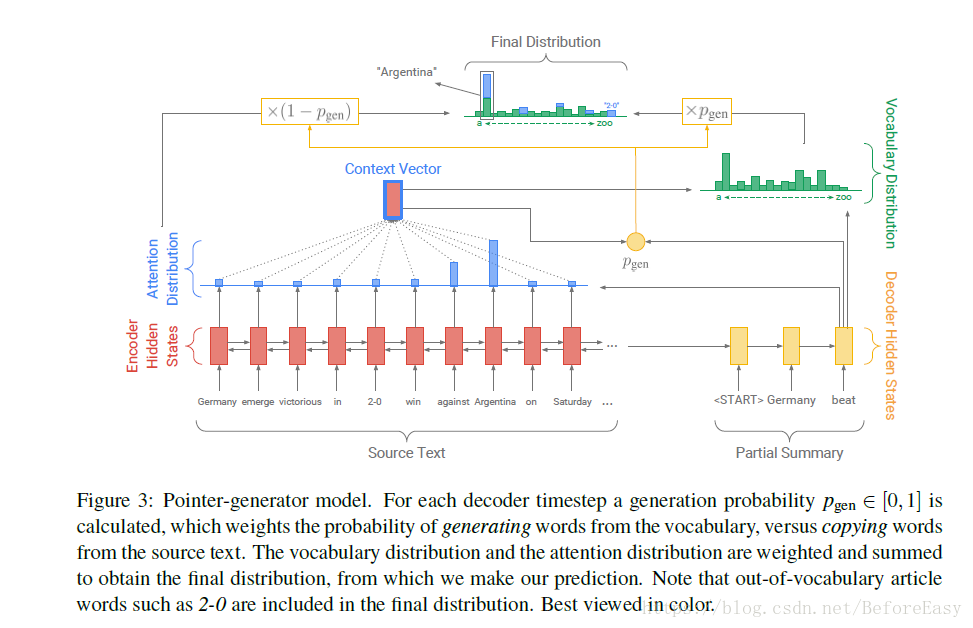
这是上面的baseline模型和copy模型的结合。
语境向量ht*和attention机制at还是要计算的,与baseline模型不同之处在于每一步还计算了一个概率值Pgen,这代表从词表中生成单词的概率,这个Pgen用来给绿色的词汇分布和蓝色来自原文的attention进行加权,得到最最上面那个有绿有蓝的图,可以看到原来不在词表中的2-0也加进去了。
Pgen的计算方式如下:
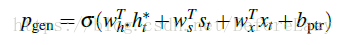
其中ht*还是语境向量,st是这一步的decoder state xt是这一步的decoder的输入,换成yi-1这种表达大家可能更习惯,就是已经生成的摘要嘛,最后外面是一层sigmoid
Pgen就可以用来决定是从词表中生成一个词还是拷贝一个词,具体见下面的公式
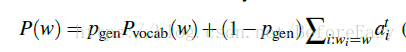
损失函数和上面的baseline是一样的,只不过最后的P(w)的计算方式不一样而已。这个模型相当于每次动态生成时,将源输入中词们加入到了词表vocabulary中

2.3 coverage mechanism
这个是为了解决重复输出的问题
在decoder的每一步,维护一个coverage vector ct
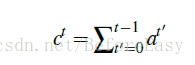
记录之前所有预测步中注意力分布的和,记录模型已经关注过原文中哪些词(也就是目前的生成已经覆盖到哪些词),并让这个向量影响attention的计算,c0是等于0的,因为一开始原文中没有任何词被覆盖
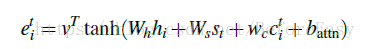
单丝必须加上coverage loss惩罚关注同一位置才能使其发挥作用
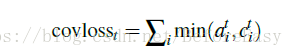
最终,模型的整体损失函数为:
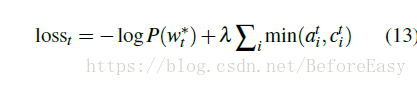
3 related work
4 dataset
CNN/Daily Mail dataset
这是多个句子的摘要
5 experiment
256d hidden state 128d word embedding
learning rate 0.15
initial accumulator value 0.1
6 results
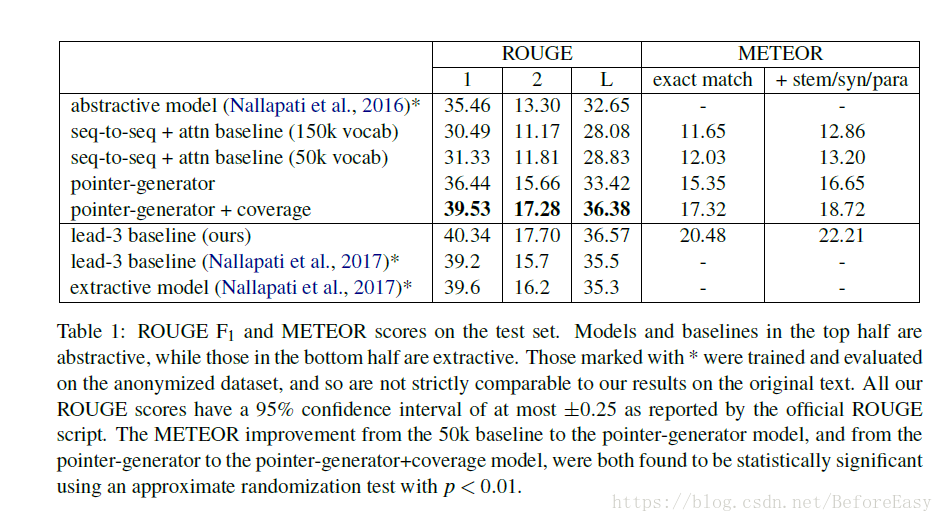
对结果的解释:
为什么下面的extractive方法得分更高?可能新闻类重要的信息就是集中在前几句。而且与ROUGE的评分机制有关。