模型介绍
baseline 方法存在两个大问题:
1.无法解决unk问题
2.有很多是重复的。
baseline model 是 seq-seq +attention 模型
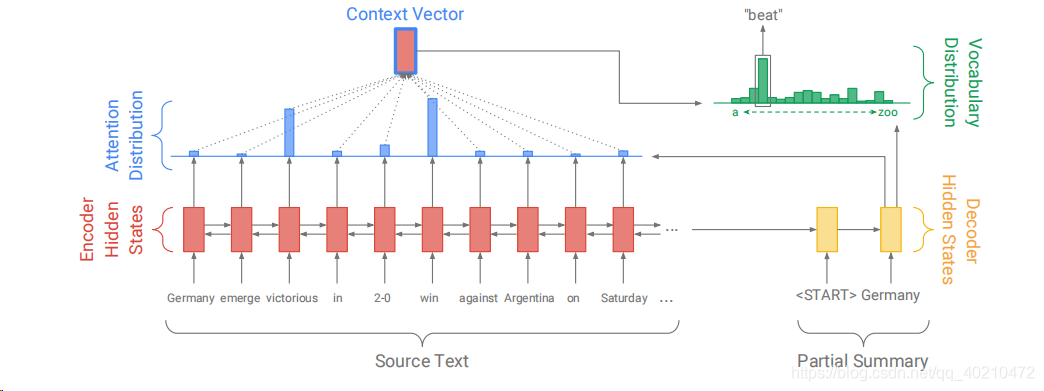
- encoder – 单层双向LSTM,产生了一个序列的隐藏状态hi
- decoder – 单层单向LSTM,训练时,输入是参考摘要的前一个词(使用教师机制) 测试时,使用decoder 的上个输出作为输入。decoder state 用 St表示。
- attention
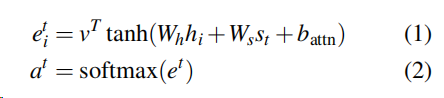
attention 的分布可以看做在源单词上的概率分布,它指示解码器在哪里查找生成下一个单词的位置。 1)式计算当前上下文环境与每个源语言词语的相关度,2)式使用softmax公式将相关度转换为概率的形式
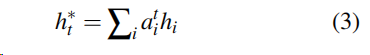
3)式表示一个context vector ,
用得到的概率乘以对应源文档的词的隐藏状态(隐含表示)作为该词对预测目标的贡献,
将所有源文档的词贡献加起来,与decoder状态St相拼接作为两个线性层的输入,
再利用softmax 层产生词表分布,也就是下式。
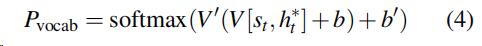
4)式中 Pvocab是表示了词汇表中所有词汇的概率分布。为我们提供最终的分布以预测单词w。
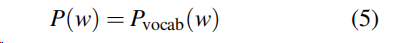
训练时,使用负对数似然函数作为损失函数(softmax作为目标函数时常用negative log-likelihood 函数或者交叉熵作为损失函数。)
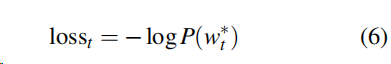
整个训练的损失是 timestep的和。
pointer-generator network
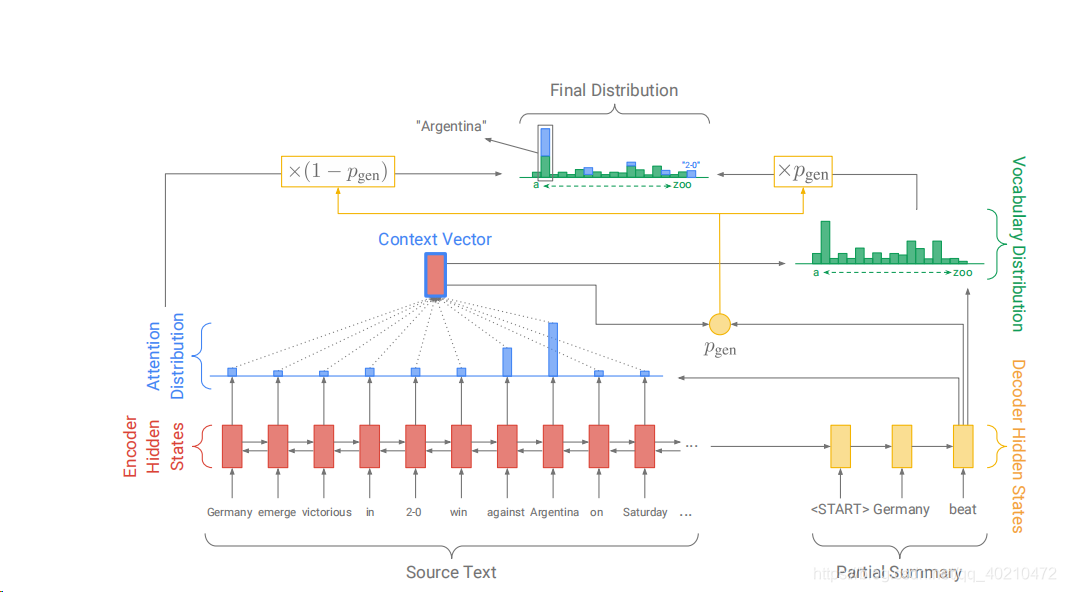
处理这些ooV单词的最直观的方法就是简单地指向他们在源文档中的位置,也就是pointer指针网络。
我们的指针生成器网络是基线和指针网络的混合体,因为它既允许通过指向复制单词,也允许从固定词汇表中生成单词,解决了UNK问题。 attention 计算和上文中提到的seq-seq +attention 中的计算方法是一样的,。此外,从上下文向量h∈t、解码器状态st和解码器输入xt计算时间步骤t的生成概率pgen∈[0,1]。
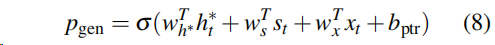
生成概率可以看做一个软开关,它可以选择通过从Pvocab 中取样从词表中生成一个词,或者,通过attention 的分布中取样从输入序列中copy一个单词。
对于每个文档,让扩展的词汇表与原文中出现的所有单词进行合并,扩展词表的概率分布如下。
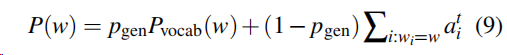
如果w 是一个out-of-vocabulary词汇的话,那么Pvocab=0,如果w不是源文档中的词汇的话,那么w 的attention分布就是0 。这也是这个文章的一个主要贡献,将原词表分布与生成概率结合起来。
coverage mechanism --解决重复问题
重复问题是seq-seq模型最主要的一个问题,这个问题尤其是在生成多文本的时候更为明显。我们很好理解,词汇表中那些重要的词的概率大,所以出现的机会也就越多,也就越容易造成重复问题。
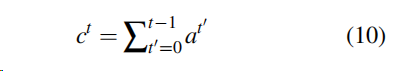 、
、
上述是coverage vector 。coverage vector是所有先前解码器的注意分布之和。Ct是源文档单词上的一个(未规一化的)分布,它表示到目前为止这些词从注意力机制收到的覆盖程度。

coverage vector 作为attention 的额外输入,这也是和之前baseline不一样的地方,这确保了注意机制目前的决定(选择下一个)是通过提醒其先前的决定(ct 的,这将使注意力机制更容易避免重复处理相同的位置,从而避免产生重复的文本。
我们认为有必要另外加入coverage loss,以惩罚多次出现同一位置的词:
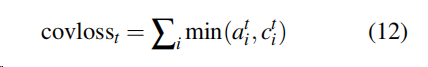
在MT中,我们假设应该有一个大致的一对一的翻译比率;因此,如果最终覆盖向量大于或小于1,则会受到惩罚。因为ait是小于等于1 的。
该模型 最终的loss 函数 为

