《Simple and Effective Curriculum Pointer-Generator Networks for Reading Comprehension over Long Narratives》
这篇文章是发表在2019年ACL上的,主要是针对narrativeQA数据集得到了SOTA效果。数据集介绍可见
分以下四部分介绍:
- Motivation
- Model
- Experiment
- Discussion
1、Motivation
- 长文本的阅读理解处理起来较为困难,去除信息过多会导致答案不可预见,去除信息过少则会造成计算复杂,文本冗余。
- 模拟人在阅读理解过程当中,反复的对文档和问题进行斟酌。
解决:
- 提出一种课程学习的方法,让机器学会从简单到困难进行阅读理解,并且使用指针生成网络,即使答案未出现在文本当中,也能够很好的对其进行生成
- 使用 Alignment Layer (IAL)充分的融合对齐,得到更深层次的语义信息
2、Model
2.1 overview
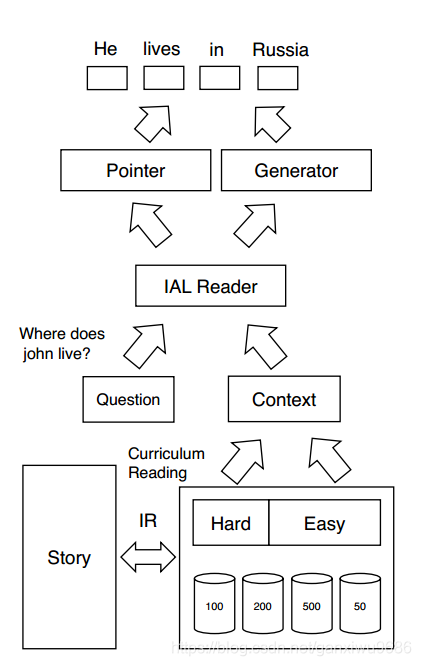
下面是模型的整体框架图,从图中可以看到,主要包括三个部分,首先对故事去进行信息检索,将得到的内容和问题通过IAL reader模型,最后通过指针生成网络生成答案
2.2 Introspective Alignment Reader
- 输入是文档和问题
- 输出是生成的答案
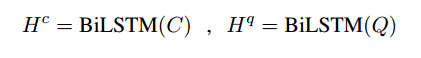
首先经过LSTM得到文档和问题的表示,通过一种对齐方式计算attention,F表示线性和非线性变化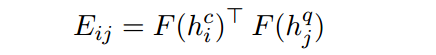
随后融合问题,得到文章的表示:
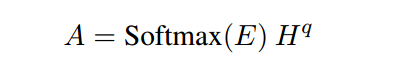
为了更好的衡量原文的表示、原文和融合了问题的文章的表示之间的差异,引入Reasoning over Alignments :
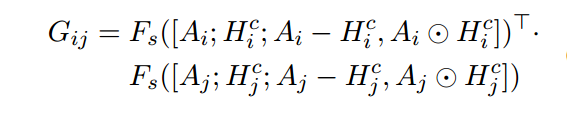
随后会进行一个局部基于block的self attention,考虑到文章的长度过长,经常可能会超过2000,如果对所有的tokens都进行self attention,那么必然会造成计算复杂度过大,因此加入限制:
∣ i − j ∣ < = b {\left| i-j \right|} <= b ∣i−j∣<=b
因为之前在做attention的时候已经考虑了全局的信息,所以这个地方为了计算力,只在窗口内进行一个局部的self attention
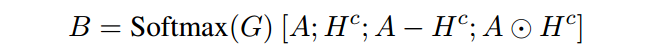
最后再将得到的新的表示进行一个双向lstm得到最终的token
级别的表示
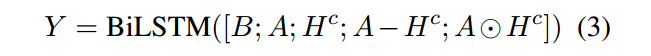
2.3 Pointer-Generator Decoder
在解码时刻,进行attention得到 g i g_i gi ,如果使用对齐后的表示,那么问题的语义信息可能会丢失,因此直接使用编码层的问题表示能够控制解码器,朝着问题的方向去进行答案生成
随后加权求和得到 y t y_t yt:
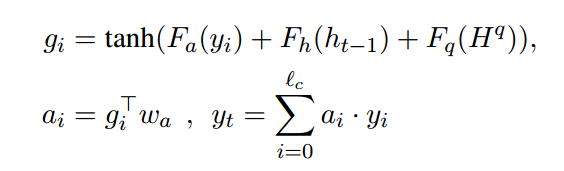
接下来更新解码端的细胞状态和隐藏状态,其中w表示真实答案的词向量:

经过线性变化得到词表概率分布并计算复制概率:

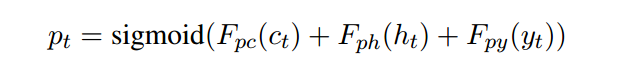
最后将生成词表概率分布和attention概率分布进行加合选择概率最大的那个词,作为输出:
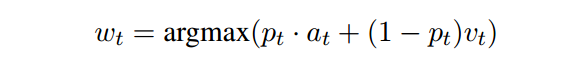
2.4 Curriculum Reading
课程学习的目的就是让机器先从简单的开始进行学习,然后再复杂化。人在进行阅读理解的时候,可以先通过看答案,了解不同的问题所需要回答的答案的形式以及方法。随后再根据问题去文章当中,寻找或者总结答案。
文章提出两个过程,第1个过程就是可回答性,第2个过程是可理解性。
- 可回答性通过,用答案去进行片段检索和用问题去进行片段检索,作为简单和困难的两个方面。
- 可解释性则通过片段的长度去决定。当片段的长度较小时,模型能够更容易的捕获相关的信息。当片段程度较大时,模型则需要进行更深层次的理解,才能够找到对应原文。因此在这个过程当中,我们把片段的大小限制在{50, 100, 200, 500}

下图是课程学习的学习算法:

首先选择一个大小比如50,然后用答案和问题分别去检索语料,得到easy和hard训练集(将得到的段落,以50为单位进行划分,然后用答案或者问题去进行匹配,找到最相关的那一块)。首先利用easy训练集,直到在验证集上,效果不再变化。随后我们交换delta的hard训练集,再进行训练,直到所有hard训练集被交换完毕。
此时我们可以将大小,选成100(其它数也可以),再次反复上面那个过程。
将可回答性的和可理解性这两个过程进行交替的训练。即使当我们的块选择很小的时候(50),我们也可以通过去看答案让模型来进行学习,算是一个简单的学习过程。此时模型相当于进行了微调,随后当size变大的时候,模型再去进行训练,如此循序渐进使得模型能够学习到更深层次的语义信息和推理能力。
3、Experiment
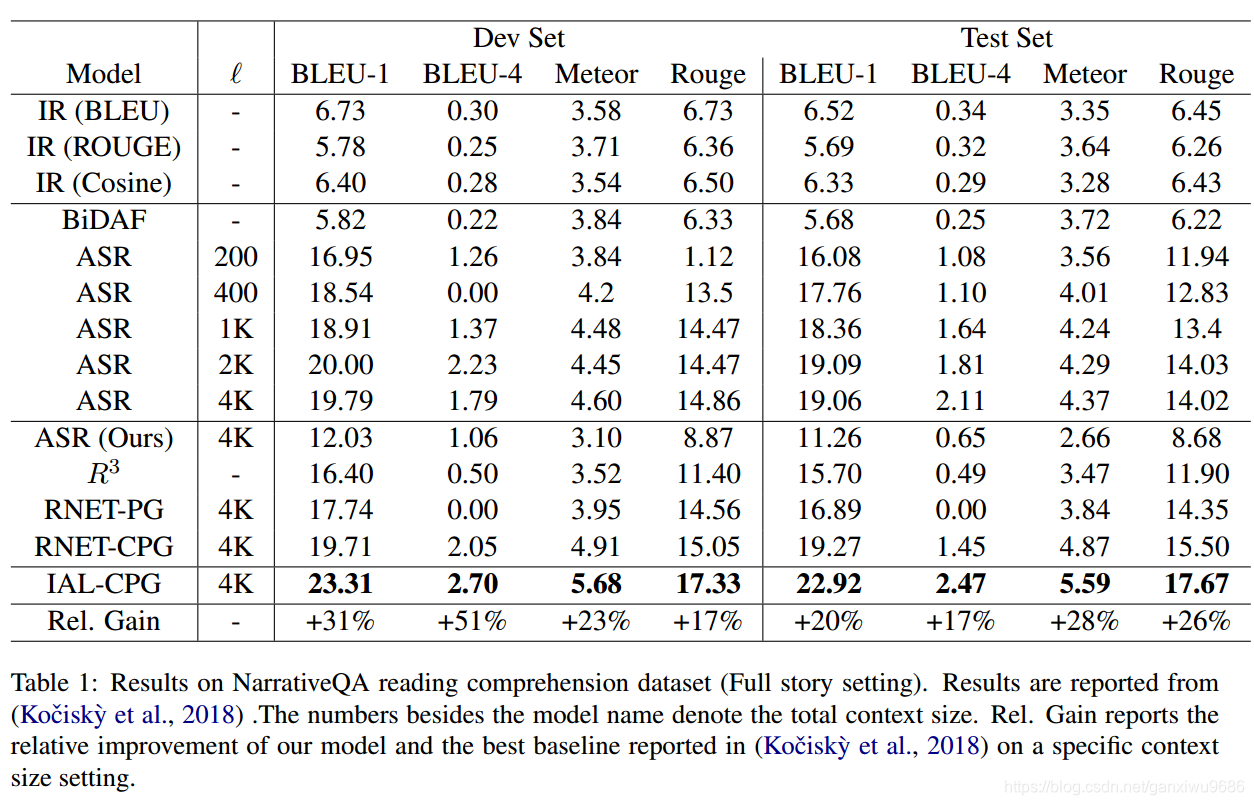
1、可以看到我们的模型实现了最好的效果,并且通过RNET,可以看出课程学习确实能够帮助模型进行更好的理解

2、从Ablation实验里面可以看出,在课程学习当中可回答性更重要。块大小选择的顺序,也会对实验的结果造成差异。
4、Discussion
- 这篇文章主要提出了课程学习的方法,让机器能够循序渐进,从简单到困难的一个学习过程。
- 对文档和融合文档的问题的表示进行反复的融合,内省。更充分的挖掘语义信息。
- 用生成方法去进行阅读理解,虽然能够解决oov的问题,也能够增加答案的多样性,但是生成的语言会存在流畅性和逻辑性的问题。